5.5 Improving Performance
5.5 Improving Performance
The overall performance of a cluster is very difficult to measure because so many disparate resources must be properly tuned for everything to run at peak performance. Also, different applications may require different tuning parameters to achieve optimal behavior. The cluster network is probably the subsystem that most influences the performance of parallel scientific applications.
Many network performance benefits can be gained at the individual node level, but more still can be uncovered at the network and network design level. When deciding on a specific network technology, the designer must think about performance of the system as well as cost and vendor/OS support. In this section we will discuss some high level network design concepts which increase overall performance of the cluster. In addition, we delve into some low level details involving the tuning of specific protocol and network parameters, thereby giving the reader a feeling for the parts of their network that can be modified to potentially improve application performance.
5.5.1 Offloading Services
One simple method for removing service bottlenecks in a cluster is to offload the service to a dedicated system. In our simple cluster case, we had no machines dedicated to specific tasks. For small systems primarily used for compute bound applications, this may work nicely. But as we increase the number of nodes, the number of users and the complexity of the applications, running services on the compute nodes quickly becomes problematic. Imagine a case where one user's application, running on the node providing NFS service, is fully utilizing the compute and I/O capabilities of that machine. Along comes another user, attempting to run a parallel application with moderate NFS requirements. The result is resource contention for the CPU, disk and network on the NFS server, causing both applications to slow down. If there is one node in a system that has multiple tasks to perform while others have only one task, the potential exists for wasted cycles. The obvious, and often implemented, solution is to offload services to a dedicated service machine so that all compute nodes are identical in the resources they provide to applications. This simple optimization leaves us with a pool of compute nodes distinct from the machine devoted to servicing tasks such as user login, compilation, NFS service, DNS service, etc. If bottlenecks still appear, services may be further split across multiple machines, leaving us with several service nodes, each with their own set of balanced tasks. Service offloading is a very important step towards achieving the goal of maximizing the performance of our cluster. However, the cluster can still have bottlenecks within a specific service.
While not specific to cluster environment, the idea of service load balancing remains a very important concept for cluster network designers. Although the idea of load balancing transfers nicely from more traditional UNIX networks, the specific load characteristics of the same services in a cluster environment can be drastically different. For instance, a traditional UNIX network may happily operate with a single NFS server and a large number of clients; whereas, a cluster with the same number of clients could easily overrun the single NFS server because the intensity and frequency of client accesses is radically different. With this disparity in mind, the cluster network designer should be careful to reevaluate their load balancing experiences with traditional UNIX networks before applying that knowledge to balancing their cluster services.
The specifics of service offloading vary depending on the particular service, but the idea remains the same: identify service bottlenecks (where a single service is being overwhelmed by multiple simultaneous requests) and find a way to offload that specific service to multiple servers so no one server is being overwhelmed. For example, if a NFS home file system server is being overwhelmed, a simple but effective way to lighten the burden is to bring up a second NFS server. The home file system can then be split into two volumes with half the homes served by one machine and the other half served by the second machine. While this technique can work for some services, it can not be used for services that require a synchronized, centralized repository of data. These types of services often have their own mechanisms for dealing with load balancing and should be researched thoroughly before attempting to make any adjustments.
Another case where the "splitting data in two" technique fails is when a single job places high demands on a single service, overloading the associated server. For instance, if a user's job places heavy demands on a single NFS server from many nodes, that job can overload the server. Since there is only one canonical data source, we cannot employ our "split into two" method without introducing serious synchronization problems. As it turns out, this case highlights an inherent scalability problem with the NFS service, which is not easily overcome. In such a situation, we may have to employ more powerful, better scaling solutions to the problem. To rectify this situation, we would likely move to a parallel file system, such as PVFS (see Chapter 19), which scales by splitting data requests to multiple servers and therefore eliminates the single server problem with NFS.
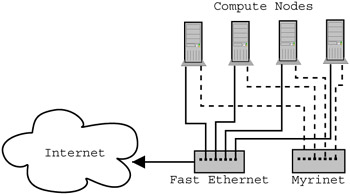
Figure 5.3: Diagram showing compute nodes with multiple interfaces on multiple networks. Notice that the Myrinet network is entirely internal to the cluster, a common design point since the dedicated network is typically much higher performing than networks outside the cluster.
5.5.2 Multiple Networks
For a cluster with high performance requirements, a common network design optimization employs multiple networks to separate different classes of network traffic. Examples of network traffic classes are application message passing, NFS traffic, cluster management traffic, etc. If we think about the types of high bandwidth traffic that pass over a cluster network, we can identify times when the network is saturated by one class, thus reducing the performance of the another class. In most cases, both classes would be affected, and the overall performance of the system would suffer. We can imagine the situation where a user's job is simultaneously reading a large file from NFS and attempting to do a collective communication operation, resulting in serious network resource contention.
Application message passing traffic is probably the most sensitive to network resource contention. Since the performance of the cluster is often gauged in terms of application performance, application message passing traffic is usually the class that drives the need for a separate, dedicated network. The concept is fairly straightforward; we would have one network devoted to message passing, and one devoted to all other traffic. While we can sometimes use a duplicate network technology such as fast Ethernet for our dedicated network, the performance may not be sufficient. More often, designers invest in a specialized network technology that will improve network performance for message passing by a large order of magnitude. The drawbacks of installing a specialized dedicated network include increased cost and administrative complexity. The cost of a specialized network, on a per host basis, may double the cost of a node.
5.5.3 Channel Bonding
As we stated earlier, cost plays a role in cluster network design. The highest bandwidth networks tend to be emerging technologies with premium price tags. However, sometimes applications require more capacity than a single channel (link) of a more suitably priced network can provide. One solution is to bind multiple channels together, thus creating a virtual channel of higher capacity.
As you might have guessed, channel bonding is no stranger to Beowulf clusters. In the early days of Beowulf clusters, 10Mb Ethernet was commonplace, but 100Mb Ethernet was still emerging and quite costly. Cluster designers wishing to obtain additional bandwidth, but unable to afford 100Mb Ethernet, would place multiple 10Mb Ethernet cards in each node and bond them together so they appeared as a single higher capacity link. The same thing occurred when 100Mb Ethernet became readily available and gigabit Ethernet was still being sold at a premium price. Now, as the price of gigabit Ethernet hardware drops and 10Gb Ethernet begins to emerge, we are starting to see the bonding of multiple gigabit Ethernet channels appear in Beowulf clusters.
While channel bonding can be an attractive solution to a bandwidth problem, it is not without its difficulties. For example, channel bonding may require additional switches, one for each channel, if the switch itself does not support bonding. Also, the configuration process is somewhat more complex than for a single network interface. More information on channel bonding can be found in the Linux Ethernet Bonding Driver mini-howto, '/usr/src/linux/Documentation/networking/bonding.txt', as well as in the mailing list archives on Beowulf.org.
5.5.4 Jumbo Frames
Often techniques for improving network performance spawn directly from the specific network technology deployed. The cluster designer is encouraged to research their own choice of network technology to determine how best to tune their network. While many technology specific solutions exist, we focus on one technology in particular, gigabit Ethernet using jumbo frames, as it has gained a degree of support within the network vendor and user communities.
Historically, the Ethernet standard has specified a frame size of 1518 bytes. Drivers commonly set the MTU (Maximum Transfer Unit) of the interface to 1500 bytes, leaving space for Ethernet header information in the frame. While this frame size was appropriate for 10Mb and even 100Mb Ethernet, the introduction of 1000Mb Ethernet (gigabit Ethernet) has caused a great deal of controversy surrounding the initial choice to stay with 1500/1518 byte MTU/frame sizes. Because gigabit Ethernet network adapters, running at 1000Mb/s, can transmit far more frames per time unit than before, many modern computer architectures are having difficulty keeping up with the number of frames, and hence interrupts, that must be serviced from the network. Increasing the frame size decreases the number of times the network adapter must interrupt the processor, thus freeing CPU cycles for other tasks when performing large network transfers. The commonly chosen size of this increased MTU/frame size, or jumbo frame, is approximately 9000 bytes. This size was chosen for its proximity to a base two value (8192) with additional room for headers, while still being small enough to not compromise Ethernet error detection schemes. The choice of an exact MTU greatly depends on the largest size supported by both the gigabit Ethernet adapter and the switch hardware. Unfortunately, increasing the size of MTU creates problems for existing hardware and clients that are configured to use the standard 1500 byte MTU. This disparity can cause hosts communication problems, switch hardware to drop what it considers to be oversized frames, and various other problems.
For the sake of simplicity, we will assume that the cluster network is composed entirely of all gigabit Ethernet connected hosts with no external communication requirements. In other words, the network is a dedicated communication network. With this assumption, enabling jumbo frames within the cluster just means that we need to set our interface's MTU to 9000 bytes using the following command. If the reader's adapter/hardware configuration supports a different maximum MTU size, they should substitute that value for the 9000 value used below.
ifconfig eth0 mtu 9000 up
This command can be placed in the startup scripts of each node to ensure that the setting will persist across reboots. On Red Hat systems, we can insert the following line into the '/etc/sysconfig/network-scripts/ifcfg-eth0' file to automatically set the MTU for device eth0 on boot.
MTU=9000
When configured correctly, we should see lower CPU utilization when network transfers are active, and higher bandwidth due to the removal of potential bottlenecks.
5.5.5 Interrupt Coalescing
The primary advantage of jumbo frames is the reduction in the number of interrupts, and thus the CPU utilization, required to process incoming data. As an alternative, some network cards can be configured to delay interrupting the host until multiple packets have been sent or received. On the receive side, the interrupt is typically delayed until a specific number of packets have been received or a specified amount of time has elapsed since the first packet was received after the last interrupt. A similar thing occurs on the send side. The exact use of packet counts or delay times depends on implementation of the network card. Regardless of the mechanism causing the interrupt delay, the effect is the coalescing of interrupts.
Network cards that support interrupt coalescing generally have tunable parameters that can be modified when the driver is loaded. Care must be taken when adjusting these parameters. Increasing the maximum delay or packet count threshold too high can have negative effects. On the send side, too long of a delay can result in all of the send descriptors being depleted, thus causing a stall. A stall translates into wasted bandwidth. On the receive side, too long of a delay can result in all of the receive descriptors being depleted, thus causing incoming packets to be dropped. For TCP, dropped packets means retransmission, wasting bandwidth and delaying data reception. Frequent retransmission causes the TCP implementation to decide the link is oversubscribed and to apply its congestion control algorithms. The net effect is a further reduction in available bandwidth for the application(s) attempting to send data. (For details on TCP congestion control see [28, 110].)
Assuming the parameters are set to values preventing descriptor depletion, interrupt coalescing still impacts performance in interesting ways. The obvious positive impact is the decrease in the amount of CPU time spent entering and exiting the interrupt handling code, freeing the CPU to spend more time executing other user or kernel codes. If prior to enabling interrupt coalescing the CPU was saturated with interrupts, the application may not have been receiving enough cycles to keep the send buffer sufficiently full or the receive buffer sufficiently empty. Enabling interrupt coalescing may be just what a bandwidth starved application needs to obtain maximal performance. On the other hand, any delay in triggering the receive interrupt directly affects latency as the kernel has no knowledge of a packet's arrival until the interrupt occurs. This delay could have a negative effect on latency sensitive applications.
As you can see, interrupt coalescing has tradeoffs and requires careful tuning to obtain maximal bandwidth while also achieving a minimal impact on latency. But, when jumbo frames are not an available option, interrupt coalescing may prove important to meeting the performance needs of your applications.
5.5.6 Socket Buffers
For TCP communication, the size of the send socket buffer determines the maximum window size at the sender. As mentioned in Section 5.2, the send window controls the amount of unacknowledged data that can be outstanding, thereby affecting the actual bandwidth achieved over the connection. Your first instinct might be to make the send socket buffer as big as possible; however, this would unnecessarily consume a shared resource, thus possibly depriving other connections of suitable buffer space. Additionally, excessively large buffers can result in less than optimal performance. The trick is to determine a suitably sized buffer that maximizes bandwidth while minimizing the consumption of shared resources. The bandwidth-delay product is used to compute the minimum necessary buffer size.
For the bandwidth-delay product, bandwidth is defined to be the maximum bandwidth obtainable over the connection. In other words, it is the maximum possible bandwidth of the slowest network involved in the connection. On most clusters, intra-cluster communication travels over a system area network for which the bandwidth is generally known, so obtaining the bandwidth figure should not be difficult.
Delay is measured as the time it takes for the sender to send a packet to the receiver, the receiver to receive the packet and to send an acknowledge back to the sender (possibly piggybacked on a data packet), and the sender to receive that acknowledgment. This delay is traditionally known as the round trip time (RTT). RTT is frequently measured using the ping program. Although ping does not use the same protocol nor have the same processing overheads as TCP, the ping RTT is usually sufficiently close to the TCP RTT. The best results can be obtained if the size of the packet transmitted by ping is equal to the MTU of the underlying network. Fortunately, the version of ping provided with most Linux distributions allows the data size to be specified. For Ethernet, a data size of 1472 bytes plus the ICMP and IP headers will result in the desired MTU of 1500 bytes.
The size of the receive socket buffer determines the amount of data that can be buffered by the receiver while it is waiting for the application to consume the data. The receive buffer size also impacts how much data the sender may send before being notified that more buffer space is available on the receiving end. This notification is sent by the receiver along with acknowledgment and data packets and is therefore impacted by the round trip delay we have already discussed. The implication is that the receive buffer should be at least as big as the send buffer if maximum bandwidth is to be achieved.
Unfortunately, for high bandwidth, low latency links like those used for a cluster network, the bandwidth-delay product only computes the lower bound of the needed buffer space. Other factors in the network hardware and software layers, for which the delay measurements do not account, affect the amount of buffer space required to achieve the maximum obtainable bandwidth. In fact, even the communication characteristics of the application can affect the buffer sizes required to obtain optimal performance.
The application itself (or a kernel of it) is a the best tool for determining the appropriate socket buffer sizes needed to obtain high communication performance from that application. Sophisticated applications allow the send and receive buffer sizes to be specified, either as command line options or through environment variables. Unfortunately, not all applications which use sockets and TCP to communicate include this ability. And, even if they were included, many users are either unaware of the options or lack the understanding to set them. Therefore, programs like iperf [59] and NetPIPE [104] must be used by the system administrator to determine reasonable defaults.
Linux provides a mechanism for the system administrator to manipulate the default socket buffer sizes. The '/proc' file system entries '/proc/sys/net/core/wmem_default' and '/proc/sys/net/core/rmem_default' correspond to the default send and receive buffer sizes respectively. The current defaults can be obtained by executing the following commands.
cat /proc/sys/net/core/wmem_default
cat /proc/sys/net/core/rmem_default
New defaults can be set by writing the desired buffer sizes to those same '/proc' entries. For example, if send and receive buffer sizes of 256KB were determined to be appropriate, the following commands could be executed to set those buffer sizes.
echo 256000 >/proc/sys/net/core/wmem_default
echo 256000 >/proc/sys/net/core/rmem_default
To automatically apply the settings when then system reboots, the above commands can be added to '/etc/rc.d/rc.local'.
The system administrator also has control over the maximum buffer sizes, preventing applications from allocating excessive amounts of buffer space. The maximum send and receive buffer sizes are set by writing the desired sizes to '/proc/sys/net/core/wmem_max' and '/proc/sys/net/core/wmem_max' respectively. As before, the current settings can be obtained by reading those same entries. The maximum buffer sizes should be set so they are at least as large as the defaults. Again, commands to set these parameters when the system boots may be added to '/etc/rc.d/rc.local'.







