5.6 Protecting Your Cluster
5.6 Protecting Your Cluster
One of the most important issues that face the cluster network designer is that of cluster security. This is not only one of the most obvious concerns, but security decisions are far reaching and can potentially interfere with the usability and performance of the system.
In this section we discuss security concerns and delve into the details of techniques that cluster designers can employ to find the optimal security solution for their own unique requirements.
Briefly, we define 'Protecting Your Cluster' as a series of techniques that range from minimizing a cluster's susceptibility to outsider attacks to making a hackers life difficult even if they somehow gain login access to internal cluster machines. We will not be addressing the securing/validation of application or user data via encryption or digital signature techniques.
We approach the concept of security by breaking the realm into two distinct phases: stopping unwanted network packets before they reach a computer and stopping unwanted network packets once they reach a computer. It should be noted that some cluster network design schemes will require attention in one or the other phases, but all schemes should probably pay attention to both. Although this may seem oversimplified, we believe that by thinking of security in this way we can capture the major issues surrounding cluster network security.
5.6.1 Phase 1: Once the Packets Get There
Since the simplest cluster network design case is one where all machines are openly connected to the Internet, we will first consider security from the standpoint of how to make sure that individual systems are safeguarded against malicious network packets once they arrive at the machine. We can imagine this case analogous to a case where a castle is being attacked by an invading army. Once the invaders have breached the outer defenses, the castle is still far from lost as it could have internal safeguards to keep the attacking forces at bay. While boiling oil and sharpened sticks will not help us in securing a compute cluster (generally), we can still use common node securing techniques to keep intruders from damaging the integrity of our systems once they have breached outer security systems (if such outer security systems exist).
Locking down individual node software
One simple concept, and one that should probably be understood and implemented regardless of a chosen network design, is that of securing individual machines on a local level. History has shown us that Operating Systems are often times initially installed with insecure parameters. The reasons for this truth vary, but are most often the cause of the wide range of users that are installing from a single version of OS media. In our case, the version of Linux we will be installing on nodes was most likely not meant to be a secure, high performance, optimized for scientific computing, cluster node OS. It was probably designed to be an out of the box small business server OS or home desktop OS. The default settings, therefore, may not be properly tuned for our specific application of the OS and must therefore be reconfigured to fit our needs.
Disabling unnecessary services
As a first step towards locking down our systems, we should first take a look at what is running on our systems when nobody is logged in. Is a web server running? An NFS server? Other various network daemons that we don't necessarily need? Ideally, our clusters would be running only what is necessary for compute jobs to run. In reality, this is very little, and is mostly software that does not need to be running with an open port on the system. Historically, popular Linux distributions have been attacked by security experts because the default OS configuration had almost every conceivable UNIX service process enabled. Although these services had no known exploits at the time of distribution rollout, malicious entities across the world are continually looking for service exploits, and inevitably some of the default services were found to be insecure, allowing remote attackers to gain super-user access to machines. This situation gave rise to many Linux machines being installed that were immediately insecure. Although the situation has recently improved a great deal (Linux distributions now focus on simple service configuration tools, but have most of them disabled by default) the lesson is still an important one.
The first step to disabling unnecessary service is to first realize which services are running on the system. As discussed in Section 3.2.3, this information can be gathered using simple ps and netstat commands to examine what processes are running and what network ports they are listening on respectively. See the man pages of these tools for more information. Another common tool for examining which network ports a machine is listening on is the nmap tool which is used to show the network ports that are open on a remote machine.
The second step is to understand the service startup scheme of your systems. This varies from distribution to distribution, but is usually fairly straightforward using bundled GUI tools or command line interaction.
The last step in shutting off unwanted services, once they have been identified and the process for disabling them is understood, is insuring that all systems in the cluster have identical configurations. The specifics of synchronizing configuration across machines in your cluster is beyond the scope of this chapter, but can usually be accomplished via bundled cluster software or simple shell scripts.
Although it would be generally grand to disable all services that can be remotely exploited, there will inevitably be some services that must be enabled for proper cluster operation. This being said, since we can't disable the service, we must do our best to make sure that each enabled service is secure as possible. First, since these network services typically accept remote queries, we should enumerate the remote entities that need to be able to make connections to our local hosts. By default, most services will allow connections from any machine on the Internet, a behavior which is most likely more flexible than it needs to be for Linux cluster services (does a machine in Egypt really need to be able to connect to our local print spool?). For each service, the cluster designer should be able to enumerate domains that should be able to connect to that service, often times to the IP level. The cluster operator should make a table of necessary services, and which groups of external machines need to have access to the service. Table 5.1 summarizes some of the important services.
|
Service |
Description |
Allowed |
|---|---|---|
|
ssh |
Allows remote users to log into machine securely |
Entire Internet |
|
nfsd |
Allows remote machines to share file system volumes over the network |
Internal cluster nodes |
|
named |
DNS server, serves name/IP mapping information |
Internal site machines |
|
httpd |
Web server, serves cluster information documents, files |
Internal site machines |
|
scheduler |
Batch job scheduler |
Login nodes only |
Once we have a clear notion of which remote entities should be able to connect to each of our services, we must identify the mechanism by which these services restrict access. Most services have their own mechanism for access control, while others may rely on a uniform access control system. Following is an example of how we use the '/etc/exports' file to control access to an NFS server process.
[root@host.myu.edu /root]# cat /etc/exports
/exports/rootnfs *.myu.edu(rw,no_root_squash)
/exports/stage *.myu.edu(rw)
/exports/my *.myu.edu(rw)
/exports/scratch100 192.168.1.100(rw)
[root@host.myu.edu /root]#
In this example, we are granting access to all machines in the domain myu.edu to the first three file systems, and only to the machine which is bound to the IP address 192.168.1.100 for the last file system.
Now that we've disabled unneeded processes and secured everything else as much as possible, it may seem that on a local level, we have gone as far as possible. However, the one dimension that most frequently creates security problems for UNIX machine administrators is that of time. Generally, services are not written to be insecure (hopefully) and are not installed on systems with known security holes. The problem is that over time, flaws are first found, shortly afterwards they are exploited. An attentive cluster administrator needs to notice when flaws are found by the Internet security community and act to update installed software in the short time interval between when the flaw is found and when the flaw is exploited. To do this, an administrator must regularly watch the security websites and mailing lists for the uncovering of exploits, as well as watching the distribution vendors security pages for notification of updates. Some examples of established and useful security websites are [101] and [23]. The former has shown to be very fast to respond to new vulnerabilities and often includes proof of concept exploit code in addition to descriptions fixes to security problems. CERT is a very complete index of vendor supplied problems/patches to security problems but is sometimes slower to respond to new vulnerabilities.
5.6.2 Phase 2: Before the Packets Get There
In the previous section, we assumed that an attacker has breached a first line of defense and had the ability to make attacks on individual machine entities in the cluster. To return to our analogy of a castle being attacked, the previous situation implied that our outer walls had fallen or that we didn't have an outer wall at all. While this is sometimes considered sufficient security, we can use outer walls in conjunction with local security measures to provide an even safer system.
Previously, we made sure that our local services were configured to reject connections from sources that we knew were not supposed to be able to access that service but this rejection implicitly assumes that our service is operating properly with regards to its decisions about incoming traffic. There are cases, however, where a service may have such a serious flaw that a remote attacker can introduce a service failure to the point where the service is unable to operate properly anymore, making our hard work of configuring access rules at the service level obsolete. The only way of preventing this from happening is by making sure malicious network traffic never reaches our systems, a task that firewalls can help us with.
In this section we describe some very simple techniques that can be applied to prohibit unwanted network traffic from ever reaching individual cluster machines in the form of software and hardware firewalls.
Firewalls Clarified
A firewall, simply put, is some mechanism that allows for the inspection of individual network packets combined with some set of decisions to make based on where packets originated and where they are destined. Firewalls take many forms, ranging from hardware devices that sit between a site's uplink to the Internet and all internal machines to kernel level software layers that are active on each individual machines. Regardless of how a specific firewall is implemented, its job is essentially the same as any other firewall; inspect a network packet for source and destination information, and decide what to do about it—let it through, divert it to somewhere else, or throw it away.
By using firewalls, we can very efficiently block network packets from ever reaching nodes that we are certain never will need to accept said packets. The first decision we must make, however, is that of where to put our firewall in the network chain of events. The two extremes, as mentioned above, are between a site's uplink and all internal machines, and one firewall per machine. Both extremes are most likely not ideal for a Linux cluster scenario. Since a cluster will comprise some subset of all machines at a site, policies for the cluster nodes will not mirror policies for general site machines. This prohibits the use of one site firewall that can handle all cases. On the other extreme, we would have to maintain one firewall per machine, which can be a potential source of unneeded complexity. Most likely, the cluster designer would want to place a firewall in front of logical partitions of their cluster, whether it be the entire cluster, compute nodes only, management nodes only, server nodes only, or some combination of the above.
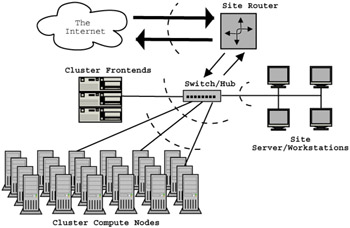
Figure 5.4: Above are shown some possible locations one may wish to place a firewall, denoted by the curved dotted lines.
Where a firewall is placed is entirely dependent on the policies set up by the cluster designer, but for simplicity we will assume one firewall between the cluster uplink and the rest of the Internet (including other site machines). This is to say, all packets that are destined for any machine inside the cluster must past through our firewall, and any packet originating from the Linux cluster must also pass through the firewall.
Linux provides a very powerful suite of firewalling software, which we will cover in detail. Later we will briefly explore various hardware solutions to the same problem.
Linux software firewalling using iptables
The Linux operating system, as of the time of this writing (Linux version 2.4.X), provides a very complete packet filtering and mangling system that can be used as, among other things, a software firewall. All packet inspection/alteration activity is done via a kernel subsystem known as netfilter and is controlled by a userspace utility known as iptables. The scenario in which these subsystems are applicable in our case is when we're using a Linux machine as a network router. Say our cluster machines exist in the 192.168.13.0/24 address range. We have one Linux machine with two network interfaces (one interface on the 192.168.13.0/24 network and the other on a network that is routed to the rest of the site). We can run routing software (refer to routed or gated documentation) to cause our machine to forward packets from one interface to the other, thereby creating an site gateway for our cluster nodes. If one's cluster was using an Internet routable network, the same router setups applies except the router would now be acting as an Internet gateway instead of a simple gateway between one unroutable site network and the unroutable cluster network. Once we have set up this routing Linux machine, we can configure it as a very powerful firewall.
The iptables/netfilter subsystem is best understood when considering the path a network packet takes when traveling through a Linux machine that is acting as a router. Along this path, there are certain predefined inspection points where we can define sets of tests that the packet must endure. Based on the outcome of the tests, we may allow the packet to continue, we may jump to a different set of tests, we may alter the packet, or we may throw the packet away forever.
To understand how we might use such a system, we can start by considering two of the predefined checkpoints, or chains in iptables terminology. One chain is encountered after a packet arrives at the Linux router and the router decides to forward the packet on to its destination (box 1 in Figure 5.5). The other chain is reached by a packet when a Linux machine (router or otherwise) decides that the packet is destined for itself (box 2 in Figure 5.5), and moves the packet up into userspace where a waiting process can handle it. The former, in netfilter terminology is referred to as the FORWARD chain and the latter is the INPUT chain. Each of these chains contain rules that are of the logical form "if the packet matches <X> then perform action <Y>". For a given chain, a packet starts at the first rule and continues through the conditionals (assuming it does not match the <X> criteria) until it reaches the very end. If a packet does match the <X> criteria, a common <Y> action to take would be to accept the packet (let it continue on past the chain). Each chain has a policy set on what to do once a packet makes it through all the rules in the chain.
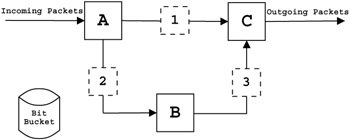
Figure 5.5: Above are shown some of the interesting points through the Linux kernel where network packets are affected. The letters are points in kernel space where routing decisions are made. Numbered locations are some of the places where netfilters exist that will determine the fate of packets passing through. A.) incoming packet routing decision. B.) local machine process space. C.) postrouting decision. 1.) FORWARD netfilter table. 2.) INPUT netfilter table. 3.) OUTPUT netfilter table.
With this basic knowledge of what is happening to a inspected packet, we can start to think about how to use this system to provide reasonable security for our cluster. An old but useful paradigm in firewall policies is to start by blocking all network traffic, then start allowing only what needs to make it through. For us, this would mean that by default, we would want to set the chain policy (remember this is the decision that is made when a packet passes through all the rules without matching any of them) to drop the packet, and then insert rules that look for only the packets we would like to let through and allow them to pass. Generally, we can expect to be able to set up rules that look at a packets source, its destination, protocol (TCP/UDP), and its service type based on the port of its destination process. In this way, we can makes rules based on who is sending the packet, who the packet is supposed to go to, and what service (sshd, httpd, etc) the packet is supposed to be a part of. Following is an example of how we would set up a simple firewall that all incoming traffic except for that destined for the sshd and httpd processes on cluster nodes. We do this by using a Linux router that is sitting between our cluster and the Internet.
First we show how to inspect the current state of the default chains (checkpoints).
[root@host.myu.edu tmp]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
[root@host.myu.edu tmp]#
We can see that there are no rules defined.
Next we set the policy on the FORWARD chain to DROP, thus insuring that any packet that does not match one of our to be determined rules will be immediately dropped instead of forwarded on.
[root@host.myu.edu root]# iptables -P FORWARD DROP
Since our DROP policy will drop packets coming from and heading to the internal cluster machines, we set up a simple rule to let all traffic originating from the cluster through. In the following, where we needed to continue an input line, we used a backslash at the end of the line.
[root@host.myu.edu root]# iptables -A FORWARD \
-s 192.168.13.0/24 -d 0.0.0.0 -j ACCEPT
Finally we can set up some rules for allowing packets destined for sshd (port 22) or httpd (port 80) to pass from the outside network to our internal network.
[root@host.myu.edu root]# iptables -A FORWARD -s 0.0.0.0 \
--protocol tcp --dport 22 -d 192.168.13.0/24 -j ACCEPT
[root@host.myu.edu root]# iptables -A FORWARD -s 0.0.0.0 \
--protocol tcp --dport 80 -d 192.168.13.0/24 -j ACCEPT
Once again, we use the -L flag to view our new firewall setup.
[root@host.myu.edu root]# iptables -L
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy DROP)
target prot opt source destination
ACCEPT all -- 192.168.13.0/24 0.0.0.0
ACCEPT tcp -- 0.0.0.0 192.168.13.0/24 tcp dpt:22
ACCEPT tcp -- 0.0.0.0 192.168.13.0/24 tcp dpt:www
Chain OUTPUT (policy ACCEPT)
target prot opt source destination
[root@host.myu.edu root]#
If we wanted to set up rules to block packets arriving at the local machine, we would perform the same style of operations but instead add rules to the INPUT chain instead of the FORWARD chain.
Setting up a complete firewall will take many rules, and will be different for every site. For more information regarding Linux firewalls, the reader may wish to consult one of the many books written on the topic, for instance [127].
Hardware firewalls
An alternative to using a Linux machine as a router/firewall between protected machines and the Internet is to use any number of specialized hardware devices which essentially do the same thing. Many companies have provided embedded systems that are easy to configure/manage and quite robust. The benefit of these systems are they're relative ease of use (no iptables commands to learn) and the fact that they have vendor support. The drawbacks are the slower response times to security hole fixes and of course cost.







