19.3 File System Access Semantics
19.3 File System Access Semantics
From the user's point of view, two aspects of the file system API should be considered: what types of accesses can be described to the file system, and what happens when multiple processes access a file at the same time. We discussed earlier the importance of structured access descriptions; in this section we will focus on the second aspect, concurrent access semantics.
19.3.1 POSIX I/O Semantics
The most significant barrier to scalable parallel I/O systems today is the POSIX I/O interface and its associated semantics.
The POSIX I/O interface [58] was specified with local file systems in mind. The POSIX I/O interface specifies the open, close, read, write interface that we are all accustomed to using. It further specifies that writes through this interface must be performed in a sequentially consistent manner. Writes to the file must also appear as atomic operations to any readers that access the file during the write; the reader will see either all or none of any write. These semantics apply to any processes that access the file from any location.
Internal to a single system, the disadvantages of the POSIX semantics are not so apparent. In the single system, all operations to a file will pass through to a single device, and locks can be used to efficiently manage atomic access to files. However, the semantics of the POSIX interface have broad-reaching implications on any type of distributed or parallel file storage. In stark contrast to the single system, now we have multiple devices that might be accessed by any single operation, and all these devices, plus the clients, are distributed across some type of network. In this situation maintaining the POSIX semantics can be a complicated and communication-intensive process, particularly when many processes access the same resources.
POSIX I/O and Locking
The most common approach to providing these semantics is to use a locking subsystem to manage access to files, and this is in fact the approach applied in all our example systems that implement the POSIX semantics (Frangipani, GFS, GPFS, and Lustre). POSIX semantics require that all accesses be atomic operations. When implemented with locks, this means that before a process can write to a region of a file, it must obtain the lock associated with that region. It can then write, then release the lock. Sophisticated lock caching and forwarding are used to alleviate the overhead of the locking subsystem in systems that expect to see a high degree of concurrent access.
Locks may be applied at the block, file, or extent granularity. The most coarse grained of these is file-based locks. File-based locks associate a single lock with an entire file. No distributed file system employing file-based locks should be seriously considered as part of a parallel I/O system because the contention for locks during concurrent access will ruin the performance of all but the least I/O-bound problems.
The second most coarse grained is block-based locks. This approach is often used in systems that use block-based accesses when communicating between clients and the underlying storage. Block-based locks have the advantage of being much finer grained than are file based locks. For large files, however, this approach can result in a very large number of locks being present in the system. Often these file systems address this by simply increasing the size of blocks. This, however, results in a situation where false sharing of blocks is more likely to occur.
The third, and most flexible, locking approach is extent-based locks. This approach can result in fewer locks in use because large ranges may be described as a single extent. This advantage is lost; however, if accesses are interleaved at a fine granularity. This approach, when coupled with noncontiguous access, can also result in a very large number of locks being processed in the system. Even with these two disadvantages this is the best locking approach for concurrent access under POSIX in use in parallel file systems today.
Scientific access patterns have a great deal of regularity. None of this information is retained in any of these locking approaches, however, leading to all these approaches being relatively inefficient, either in number of locks or in contention for a small number of locks. Approaches like IBM's data shipping can certainly help make lock approaches perform more effectively, especially when accesses are interleaved. We will discuss the similar two-phase I/O approach later in Section 19.4.4.
From this discussion, and the presence of optimizations such as data shipping, it should be clear that the POSIX semantics are known in the community to be a problem. In fact, this problem is very similar to those seen in distributed shared memory (DSM) systems, where hardware and software are used to build globally accessible memory regions [121, 54]. The DSM community has for the most part abandoned the sequential consistency model in favor of more relaxed consistency models, in large part because of the overhead of maintaining such a model as systems scale. Perhaps it is time for the I/O community to follow suit.
19.3.2 NFS Semantics
The Network File System (NFS) protocol [80, 21, 102] is probably the most popular means for accessing remote file systems. Typically, remote file systems are "mounted" via NFS and accessed through the Linux virtual file system (VFS) layer just as local file systems are. What many users don't understand is that these NFS-mounted file systems do not provide the POSIX consistency semantics! The NFS version 3 RFC notes [21]:
The NFS version 3 protocol does not define a policy for caching on the client or server. In particular, there is no support for strict cache consistency between a client and server, nor between different clients.
The story is a little more complicated for NFS version 4, but the lack of cache consistency on the client side remains.
NFS is an everyday example of relaxing the POSIX I/O consistency semantics in order to gain performance. NFS clients cache file data, checking every now and again to see whether the file has changed. This loosely synchronous consistency model makes for convenient, low-latency access to one's home directory stored on a remote system. Further, the locking systems typically used to implement the POSIX semantics are avoided along with their overheads.
On the other hand, NFS semantics are nearly useless from a parallel computing point of view. Clients can cache data indiscriminately, and tend to do so at arbitrary block boundaries. This causes unexpected results when nearby regions are written by processes on different clients; if two processes concurrently write to the same block on different processes, even if they write to different bytes, the result is undefined! Figure 19.7 shows an example of how this happens. Two nodes have cached the same block, and processes have written to different parts. First one block is committed back to storage, then the second. Because of the blocking, and the lack of consistency control, the data from the first write is lost when the second write completes.
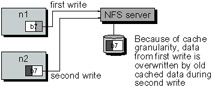
Figure 19.7: Concurrent Writes and NFS
Nevertheless, the semantics implemented by most NFS clients are sufficient to provide a usable file system for a number of situations.
19.3.3 MPI-IO Semantics
One could argue that the POSIX semantics are stricter than necessary for use in parallel I/O in that they force I/O systems to implement more consistency control than applications really need. Do scientific application programmers typically write to overlapping regions and let the file system sort it out? Probably not; they have better things to do with the I/O bandwidth! On the other hand, NFS semantics are definitely too loose; the nondeterminism introduced by uncoordinated client-side caching makes NFS semantics troublesome for concurrent writes.
The MPI-IO semantics [46] provide a very precise, but less strict, set of consistency semantics. The Using MPI-2 [50] book provides a very thorough description of these semantics; they are actually relatively complicated. We touch on the semantics for some common cases here.
First, the scope of the MPI-IO semantics is the MPI communicator used to open the file. MPI says nothing about the semantics of access from different communicators, leaving this coordination to the application programmer. Second, by default MPI-IO does guarantee that concurrent nonoverlapping writes will be written correctly (unlike NFS) and that the changes will be immediately visible to the writing process. These changes are not visible by other processes in the communicator right away. Instead, explicit synchronization between the processes is necessary. This can be accomplished in a number of ways, all outlined in [50]. Simply closing and reopening the file is one method of synchronization, and the use of explicit file synchronization operations is another.
This model makes a lot of sense for many access modes seen in parallel applications, including checkpointing and of course all read-only modes. More importantly it relaxes the requirements on the underlying I/O components significantly and provides many opportunities for optimization within the MPI-IO implementation. We will discuss two such optimizations later in this chapter in the context of using ROMIO with PVFS.
19.3.4 PVFS Semantics
Noting the increased system complexity and potential overhead in implementing full POSIX I/O semantics (and having limited resources!), the PVFS developers chose to implement a different set of I/O semantics. With PVFS, concurrent nonoverlapping writes are written correctly and are immediately visible to all processes. Note that this approach is stronger than the default MPI-IO semantics. Overlapping writes will leave some undefined combination of the written data in the overlapping file region, and reads that occur concurrently with writes may see pieces of old and new data.
These semantics are adequate for implementing most of MPI-IO and are more than adequate for most access methods while simultaneously simplifying the system significantly: no coordination is needed at write time between clients or servers. The result is a more scalable system, at the cost of POSIX semantics.







