19.5 Parallel I/O in the Future
19.5 Parallel I/O in the Future
Machines with tens of thousands of nodes are on the horizon. For a parallel I/O system to efficiently operate at this scale, a number of issues must be addressed.
Adapting to new technologies is critical in this environment. It is not clear what processor, storage, or network technologies will be present in future machines, or even what operating system will run on nodes. Any new parallel file system design should be built with abstract interfaces to allow adoption of new technologies and porting to new operating systems.
Leveraging collective operations, rich I/O request languages, and relaxed consistency semantics will be key to operating efficiently on these machines and exploiting the inherent hierarchy in these systems. Opportunities exist at many levels in the I/O component stack to boost performance.
Management of I/O systems is a growing concern because the systems continue to become more complex. Tools to aid the administrator are key, and self-maintaining solutions would be ideal.
Our next-generation parallel file system, PVFS2, is being designed to tackle just these problems. By the time this book is published, early versions of the next-generation Parallel Virtual File System, PVFS2, should be available online. The core of PVFS2 has been designed to provide PVFS2 is the culmination of a 3-year effort to redesign PVFS as a production-capable parallel file system based on experience gained in the design and operation of the original PVFS, observations of other parallel file systems, and interactions with the scientific data management community.
-
modular networking and storage subsystems,
-
a structured data request format modeled after MPI datatypes,
-
flexible and extensible data distribution modules,
-
distributed metadata,
-
tunable consistency semantics, and
-
and support for data redundancy.
In this section we will examine some of the challenges facing parallel I/O systems both today and in the near future. We will use PVFS2 as one example of how these problems might be addressed.
19.5.1 Supporting New Hardware Technologies
While in some sense cluster computing is about using commodity parts, we often see new technologies in use in larger clusters before they hit the commodity market. Networks are a great example of this; we see many interesting network technologies, including Myrinet, Quadrics, and InfiniBand, in use in clusters today. Likewise on the storage side we see locally attached hardware, SANs, and iSCSI as some of the potential mechanisms for storage access. Leveraging these technologies requires appropriate abstractions in the I/O system. In the Lustre design we see a very modular system used to attack just this problem [17].
19.5.2 PVFS2 Abstract Interfaces
PVFS2 also addresses this problem with abstraction layers. The first two of these are BMI, through which client and server messages flow, and Trove, through which storage is accessed. Figure 19.9 shows the overall software architecture of PVFS2; we will discuss the major components here.

Figure 19.9: PVFS2 Software Architecture
The Buffered Messaging Interface (BMI) provides a nonblocking network interface that can be used with a variety of high-performance network fabrics and is tailored for use in file system servers and clients. Currently BMI modules exist for both TCP/IP and GM networks.
The Trove storage interface provides a nonblocking interface that can be used with a number of underlying storage mechanisms. Trove storage objects, called data spaces, consist of both a stream of bytes and a keyword/value pair space, similar in some ways to the data and resource forks available in other local file systems. Keyword/value pairs are convenient for arbitrary metadata storage and directory entries, while the stream of bytes is a natural place to store file data. The current implementation uses Unix files and Berkeley db4, but many other implementations are possible.
The third major abstraction in PVFS2 is Flows. Flows combine the functionality of the network and storage subsystems by providing a mechanism to specify a flow of data between network and storage. Flows also incorporate the request and distribution processing system that allows PVFS2 to handle highly complex access patterns. Finally, Flows provide a point for optimization: specific flow implementations to optimize data movement between a particular network and storage pair can be implemented to exploit fast paths.
Above all these the job scheduling layer provides a common interface for posting BMI, Trove, and Flows and checking on their completion. Within this layer, scheduling decisions are made, and multiple threads are used to manage asynchrony and leverage multiple CPUs. This is tightly integrated with a state machine processing system that is used to track operations in progress. With this layer in place, new underlying components may also be added and integrated with minimal effort. At the highest level within the server, the request processing component handles incoming requests and initializes new state machines to process these requests.
19.5.3 Tolerating Faults
Parallel computing systems continue to grow in numbers of components (nodes, disks, etc.), and because components are becoming no more reliable, the likelihood of component failure is increasing. While application and middleware are beginning to be adapted to handle faults, most users depend on the I/O system to be a reliable and available location for data storage. On the other hand, because providing fault tolerance usually lowers performance, some users will desire to forego fault tolerance at the I/O system level and instead implement it in a more efficient manner at the application level. Doing so allows them to get the highest performance from the I/O system. For a parallel file system to be usable in many domains, the level of redundancy should be configurable. The approach PVFS2 takes to redundancy is much the same as it takes to semantics and other issues involving a trade-off between performance and protection: that is, it provides a choice of various levels of protection, with the requisite loss or gain in performance. Thus PVFS2 aims to allow files to be stored with no redundancy or with varying degrees of redundancy, as needed. Multiple technologies may be leveraged to accomplish this, some built into the file system and others external components.
Redundant Storage
Many tools are available for providing fault tolerance in storage systems. One is the use of local RAID arrays. This is a time-proven approach to handling disk failures, and a RAID provides high-performance I/O with minimal performance degradation when directly accessed by a single I/O server. We encourage this application of RAID with both PVFS1 and PVFS2. RAID like-techniques can also be applied across the devices on a SAN; the file system examples implementing a VSD use this type of approach. Using RAID in this way can incur performance penalties because of the fine-grained locking often used to control concurrent access when multiple nodes have access to the resources.
In PVFS2 we will provide what we term lazy redundancy as an option. In this approach writes to files do not update redundant information automatically as they would in a RAID-like approach. Instead redundant information is updated only when clients make explicit calls. These calls can be automatically made within I/O middleware libraries at logical points, such as MPI sync or close operations. By delaying the update to these explicit points we allow the I/O layers the option of aggregating updates to redundant data. Further, in the context of MPI-IO we have control of all the processes accessing the file; we can use these processes to update redundant data in parallel for higher performance. The data distribution component of PVFS allows us to describe where this redundant data is located in a convenient manner, and the approach can be applied on a per file basis. Lazy redundancy can be coupled with server failover to provide an even greater degree of protection.
Failover
High availability (HA) software provides a mechanism for server failover in the case of node failure. Dual-attach storage hardware can be used with this software to tolerate single-node failures by creating pairs of nodes that provide "backup" for each other. This allows systems to run in what is termed active-active mode (meaning that neither node sits idle in absence of failure), with somewhat degraded performance in the event that one node fails. Of course, if you don't mind having half your system sitting idle, active-passive mode can be used, leaving an extra server for each of the ones in service. More complicated HA solutions are becoming available that allow for a pool of backup servers that can be brought online as needed. In contrast to active-active pairs, this architecture would allow for a small number of extra servers that could fill in without degrading performance. However, these extra servers would need access to many different storage resources; providing this capability could be prohibitively expensive.
Having the hardware and software infrastructure necessary to restart a server on backup hardware is just the first step. A second issue to be considered with respect to failover is shared state. Clients and servers in a stateless system do not maintain information about other entities in the system that is necessary for correct operation (i.e., they can cache information for performance reasons, but the system must be able to function without this information). Assuming that a system is stateless and that no file system data is cached in volatile storage, a server restart need not cause the loss of any data. Unfortunately, shared state is used in many parallel file systems; write-back caches are an example, where a client is holding onto the state of blocks (for performance reasons) that a server is in fact responsible for. Servers and clients can checkpoint their state on shared storage if it is available. This is a viable option for systems where clients and servers have access to shared storage, but this connectivity may not be available. Another option is to implement an arbitration process that allows the system as a whole to reclaim resources and synchronize state in the event of a node loss. Handling all the failure cases can be very difficult. PVFS2 servers and clients are stateless in order to simplify the use of failover solutions and minimize complication in failure scenarios.
19.5.4 Aiding Management
Most parallel file systems today (excluding PVFS1) have mechanisms for checking the status of devices involved in the system, migrating data on and off particular resources, checking the consistency of the file system, and adding or removing devices from the file system. Looking beyond this functionality, we can imagine I/O systems that can suggest optimizations based on observed access patterns or, even better, manage themselves. The areas of "autonomic computing" [61] and "autonomous storage" in particular cover just this type of operation. PVFS1 lacked most of the management tools that administrators expect from such a system, and we believe that this discouraged its use in a number of cases. We intend to take management very seriously in PVFS2, and we will discuss some of the basics here.
System Monitoring
The first step in easing the management task is providing tools for system monitoring. These tools should allow for both examining the real-time state of the system and looking at trends over time for optimization purposes. A complicating factor in parallel I/O monitoring is the sheer amount of data available, particularly information on access patterns. This process is similar to gathering logs from parallel programs in that data from many cooperating components must be collected and presented coherently.
The PVFS development team has experimented with instrumentation of the PVFS1 servers and has developed tools to aggregate performance metrics, collect access pattern statistics, and visualize the results. Using the tools and techniques developed for PVFS and looking at other work in the area, we have slated monitoring operations to be an integral part of the suite of operations that PVFS2 supports. These monitoring functions can be used as a starting point for visualization, analysis, and self-management tools.
Data Migration
In PVFS2, file data is distributed to Trove data objects for storage. Trove data objects are referenced by a handle. These data object handles are clustered into logical groups such that all handles within a logical group are managed by a single server. In the simplest case, each server manages a single logical group of Trove handles, and therefore the objects referenced by those handles. These groups can be split and merged if necessary for repartitioning purposes, and servers may be responsible for many of these logical groups. The mapping of handles to the servers where they are stored is a part of system configuration and is easily changed. This not only provides a decoupling from handles to servers but potentially allows storage objects to be moved from server to server by transferring the control of an entire logical group and updating the handle mapping appropriately.
Figure 19.10 shows three servers, each with two logical groups of storage objects referenced by different handle ranges. If resources on the middle server need to be freed (e.g., to replace faulty hardware), the groups of objects stored on the server can be relocated to one or more servers, and requests from the clients can be redirected by updating the mapping of these groups. Because these Trove objects are used to store both metadata and data, metadata can be migrated in the same manner.
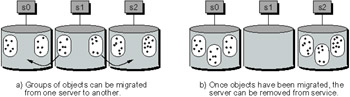
Figure 19.10: Migrating Storage Objects
Automated Management
Ideally, these systems would simply manage themselves! If components fail, data could be migrated appropriately to allow for continued fault tolerance and minimum degradation of performance. Data that is used frequently as input could be replicated so that multiple copies were available for reading or redistributed to match observed access patterns. Infrequently used data could be kept on slower disks or moved to tertiary storage. Caching and scheduling policies could be tuned to match access patterns as well.
We are very interested in this type of system, and we plan to start working in this area once the PVFS2 system matures. The first step is to provide a suite of management operations as part of the server API. With this API in place, an additional set of monitoring processes can interpret the performance monitoring information over time and direct changes to the file system accordingly. Separating these management processes into their own components will maintain the simplicity of the underlying PVFS2 core.
19.5.5 Leveraging I/O Languages and Semantics
Earlier in the chapter we discussed consistency semantics; obviously we feel that experimentation in this area could lead to useful alternative semantics. Equally important is the use of structured I/O descriptions from the highest-level interfaces down as low as possible in the I/O stack. Certainly, parallel file systems should be supporting these operations.
MPI-IO
So far, MPI-IO implementations have been very conservative in their exploitation of the more relaxed MPI-IO consistency semantics. As systems scale, taking further advantage of these semantics allows us to potentially improve I/O system performance using the same hardware as before. During this process, however, some users are likely to experience surprising behavior from the I/O system because of assumptions about what level of consistency MPI-IO will provide. We will do everything possible to minimize the pain experienced by users in order to keep them from abandoning this powerful API.
Caching at the MPI layer is one of the biggest opportunities that has so far been unexploited in production systems. The constrained scope of the MPI-IO semantics, coupled with the explicit synchronization points, makes caching in MPI-IO a straightforward process. This is in stark contrast to the infrastructure necessary to cache under the POSIX interface. File systems such as PVFS2 can benefit greatly from caching at this layer.
Operations such as MPI_File_open can be further optimized with appropriate support from the parallel file system. PVFS2 does not keep state regarding open files. Instead, clients essentially find only a file handle during an open call. A scalable implementation of MPI_File_open for PVFS2 can have a single process perform the mapping from file name to handle, then broadcast the file handle to the rest of the processes. This type of optimization can be applied in a number of cases where MPI collectives are used.
Configurable Semantics
Earlier in the chapter we discussed the file consistency semantics of a number of interfaces. We noted that for some types of workloads the NFS semantics were acceptable, while for others they were not. It is not difficult for a parallel file system to relax its semantics; usually this is a matter of simply neglecting to perform consistency checks it might have otherwise. This approach should be considered seriously. As a real example, many large physics datasets are being put online today. Files in these datasets are never modified once written. Aggressive caching of these files can be performed because the semantics applied to the dataset by the scientists permit it. We should allow for these optimizations.
Likewise, relaxing the consistency of directory contents provides another potential point of optimization, as could metadata of files and directories (in particular file size). PVFS2 will provide a configurable window of time for which previous metadata values and directory contents are treated as up to date. This allows for caching without locks, at the cost of short periods of time where views of the file system on different clients are slightly different. Such an approach might be useful as we attempt to share parallel file system access across wide-area networks.
Describing I/O Operations and Data Distributions
PVFS2 allows for structured I/O requests via a format based directly on MPI datatypes. Currently a set of datatype constructor functions identical in function to the equivalent MPI calls is provided, and the format can readily be translated from existing MPI datatype formats, making it trivial to leverage this functionality within an MPI-IO implementation such as ROMIO. PVFS2 servers directly process this format (in the flow component) to service I/O requests; the type is not converted into a vector before processing.
With structured data sets comes the potential for leveraging more sophisticated data distributions. Most parallel file systems use striping. In PVFS2, however, the distribution mechanism has been abstracted so that different files can be stored with different distributions. PVFS2 relies on an algorithmic mechanism for distribution of data to servers. The functions that define the distribution can now be selected at file creation time, permitting a number of potential data distributions.
One such alternative distribution pattern is nested striping. As shown in Figure 19.11, simple striping distributes data round-robin to all IO nodes used to store the file. Nested striping distributes data round-robin first to one subset of nodes and then to another subset in a round-robin pattern among subsets. This pattern better matches block distributions of multidimensional datasets. Any distribution that can be represented algorithmically can potentially become a PVFS2 distribution scheme.
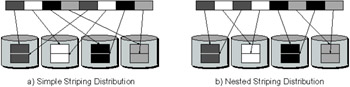
Figure 19.11: Examples of Data Distributions







