20.1 Chiba City
20.1 Chiba City
With 256 dual-CPU computing nodes, Chiba City is the largest cluster in the Argonne scalable clusters project.
Chiba City was designed with a unique purpose in mind: to support scalable computer science and the development of scalable systems software. We believe that advances in the state of system software for high-performance computing are critical in order to improve the performance and reliability of high-end machines. Yet the developers and researchers who will bring about those advances often find it very difficult to gain access to the largest systems because those computers are dedicated to running large code. With the advent of commodity clusters, the solution to this problem became clear: using relatively inexpensive parts, it was now possible to build a system that could be used to support activities that required development and testing at large scale without the usual large price tag. This was the basis of the idea for Chiba City.
In addition, Chiba City was built to support a wide range of parallel computational science applications. In the Mathematics and Computer Science (MCS) Division of Argonne National Laboratory, we collaborate with hundreds of researchers around the world who use our computing facilities in partnership with the scientists in our division. Chiba City was meant to be used by these scientists in order to tackle real scientific problems while they simultaneously worked with computer scientists to expand the scope of problem that they could address.
In essence, Chiba City is intended to support two distinct goals that are occasionally in conflict: scalable computer science research, which needs a dynamic and interactive testbed, and computational science, which has historically used stable, batch-oriented systems. We believe that Chiba City has achieved a comfortable balance between these two worlds and has helped promote good science in both.
The difference in requirements between experimentation and classic production computing has kept us—Chiba City's designers and administrators—living in two worlds at once, trying to keep the cluster both stable and interesting.
20.1.1 Chiba City Configuration
In this section, we describe the configuration of the Chiba City from multiple perspectives. We cover not only what went into the cluster but why it is there and how it is used.
Node Configuration
Chiba City includes the following computing components (see Figure 20.1):
-
256 computing nodes
-
32 visualization nodes
-
8 storage nodes
-
18 management nodes
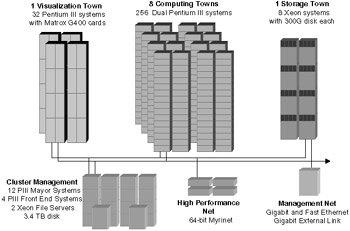
Figure 20.1: Chiba City schematic.
Computing Nodes. The 256 computing nodes are the workhorse portion of the cluster. These are the primary nodes that run the user's programs.
CPU. Each computing node has two 550 MHz Pentium III CPUs. This lets us play the game of sometimes referring to the system as a "512-CPU computer" rather than a "256-node computer." (Of course, some people actually include every CPU on the system when they count, not just the ones available to the users. In Chiba's case, this would be 574 CPUs, not including the CPUs in the networking equipment.)
One of the more hotly debated issue throughout the design phase of Chiba was the question of how many CPUs each node should have. From a pure performance viewpoint, it makes the most sense to have only one CPU per system, for several reasons. First, the memory bandwidth on Pentium IIIs is quite limited; thus one CPU alone can easily saturate the memory bus, making any more than the first one potentially useless. Second, in order to most efficiently use all of the CPUs in the system with an MPI job, the communication between processes must use both network and shared-memory communication, which is difficult. Third, at the time of the installation, Linux didn't run on more than one CPU particularly well.
On the other hand, from a price/performance perspective, it makes much more sense to have multiple CPUs on each node—and in fact, four would have been better than two from this viewpoint. It's typically cheaper to buy a dual-CPU system than to buy two of the same system, each with only one CPU. Furthermore, it's far cheaper to install a network for 256 nodes than for 512 nodes. (On the other hand, if the network is the bottleneck, then some people who use multi-CPU systems end up installing two or more network interfaces per computer.)
On Chiba City, we decided to go with dual-CPUs for flexibility. We wanted to be able to support experiments and development on both types of MPI programming. Those wishing to go for maximal node performance could ignore the second CPU. Alternatively, those wishing to use or experiment with mixed-mode MPI programming would have that option as well.
In retrospect, this is exactly what has happened. Some users find that their code is more efficient if they use only one processor. Others find that two processors work well for them. And developers have needed access to both types of configurations.
Computing Node Memory. Each computing node has 512 megabytes of RAM. We felt that this was a minimum for dual CPUs at the time. We do occasionally see applications run out of free memory and start swapping, particularly when using both CPUs, but in general this has proven to be sufficient.
Computing Node Footprint. The nodes themselves are 2U units. (Equipment that can be housed in computer racks is measured in the unit U, where 1U is 1.75 inches. A standard rack is 42U.) We went with these because they were the smallest system we could find at the time. In fact, the size of the units was a major driver: one of the initial proposals we received from vendors had 3U and 5U units, which would essentially doubled the floor space required for the cluster. We simply didn't have that much space in our machine room.
Ironically, 1U Pentium systems hit the market a few months after we installed Chiba City. We knew they were likely be available around then, but renegotiating the cluster purchase to have 1Us was simply not an option. These days, blade technology and clever mounting schemes allow configurations of less than 1U.
Computing Node Disks. Some cluster builders include disks in all nodes. Others go completely diskless. Diskless nodes have a number of advantages in a cluster. First, it's a little easier to configure the operating systems on the nodes when they're diskless, because those configurations are stored on management nodes. (This advantage can be negated if adequate configuration tools are used to manage diskful nodes.) Also, disks tend to break. If the nodes don't have disks, that's one less thing on each node that may require service. On large clusters, it's a good idea to eliminate any situation that involves touching the nodes.
On Chiba City, we have 9 gigabyte hard drives on each node. We decided to install disks in each node for maximum flexibility. Some applications that the scientists run make extensive use of local disk. We also anticipated that system-software experiments or alternative operating systems might need to use the local disk. It has turned out that, for us, this was the right choice. Many, many uses of the system rely on or take advantage of the local disk. And while we do occasionally have drives that fail, this has been much less of an issue than many other hardware components, particularly the fans.
Other Computing Node Hardware. In addition to the CPUs, the RAM, and the hard drive, each computing node has
-
one 32-bit PCI slot that is used for a Myrinet card,
-
a 10/100 Ethernet port on the motherboard,
-
a floppy drive (because that was included), and
-
serial, parallel, keyboard, and the other usual PC ports.
Computing Node Connections. Looking at the back of a node can be instructive. Each connection plugs into another component of the cluster, all of which are described in detail in following sections of this chapter.
-
The Myrinet card is a part of the Myrinet network. Each node has one fairly large Myrinet cable that runs under the floor to a Myrinet Clos64 switch.
-
The Ethernet port is used for to connect to the Ethernet network. Each node connects to an Ethernet switch in its rack or in a neighboring rack.
-
The serial port that Linux uses as the console plugs into a serial concentrator in the rack, which enables remote access to all of the consoles.
-
The "management" serial port on each node plugs into a separate serial concentrator, to be used for low-level hardware and management. This is a motherboard-specific management interface, and we've never needed to use it.
-
The power cable runs to a Baytech power control unit that allows us to remotely monitor and control the power to each node.
-
The keyboard and video ports are left vacant. In rare situations, such as hardware diagnosis or BIOS upgrades, we may plug a keyboard and monitor into them. In an ideal world, we would never use these at all. Other clusters built since Chiba use daisy-chain mechanisms to allow somewhat remote access to the keyboard and video.
Visualization Nodes. The 32 visualization nodes are used by computer scientists for research into cluster-based image synthesis and computer graphics. They are sometimes used as their own independent 32-node cluster and sometimes used in conjunction with the computing nodes as part of one large program.
The primary feature of the visualization nodes is that they include high-end video cards that can be used for graphics and image synthesis. Ideally, these cards can be used in two ways:
-
Simply as video cards. In our environment, we have a remote console infrastructure for graphics systems that allows us to connect the display port of graphics systems located in one spot to display systems located in a laboratory. This means that the visualization nodes can be housed in the machine room and still be used to drive the CAVE or our 15-projector Active Mural, both of which are in other rooms.
-
As pipelines for generating images.
These video cards typically require an AGP slot. The requirement for the AGP slot drives every other detail of the visualization nodes. For example, computers with AGP slots are usually desktop systems or workstations rather than servers. Our visualization nodes are workstation-style systems that don't fit into racks well and are actually kept on shelves. The systems that were available at the time we purchased Chiba City were 550 MHz Pentium III systems configured with 13 GBytes of disk and 384 MBytes of RAM. We manage them the same way that we do the compute nodes, including remote serial and power control.
The video cards were originally Matrox Millenium 32 MBytes G400Max cards. Since installing Chiba City, we've upgraded the video cards to NVidea GEFORCE3 cards.
Storage Nodes. The eight storage nodes are not accessed directly by most of the users of Chiba City. Instead, they provide file system service to the computing nodes, as described below under "file servers."
Each storage node has a 500 MHz Xeon, 512 MBytes of RAM, and, most important, 300 Gbytes of SCSI-attached disk. So, in aggregate, the storage nodes provide 2.4 TBytes of raw disk space to the computing nodes. This was a lot of disk at the time we installed the cluster.
The storage nodes are a part of the Myrinet network. In some cases, cluster builders will choose to put their storage nodes exclusively on the Ethernet network. This choice is primarily an issue of performance versus cost. With an even order of two number of computing nodes (i.e., 64, 128, 256, etc.), one can often build an interconnect network with a lot less hardware than would be required for those same compute nodes plus a few storage nodes. The difference may be negligible or may be substantial. In our case, getting the storage nodes onto the Myrinet meant that we needed to purchase several additional Myrinet switches. Because I/O performance and experiments are important to our user community, we felt the cost was worth it.
The storage nodes interface with the rest of the cluster in the same way that the rest of nodes on the cluster do. In addition to being available over Myrinet, they're also on the Ethernet. They also have remote power and console control.
Under normal conditions users don't have direct access to the storage nodes. However, scientists working on a project specifically related to I/O research may have access to the I/O servers. In this case, it's possible that their programs will run simultaneously on both the compute nodes and the storage nodes.
Management Nodes and Servers. The nodes used for cluster management come in several different flavors:
-
12 systems used as the cluster "mayors," or monitor systems
-
4 front ends
-
2 file servers
The mayors provide a scalable management mechanism, which is described in greater detail in Section 20.1.1. Most clusters don't need this many mayors because their configuration isn't changed as frequently as Chiba City's.
Mayor systems. Every set of 32 computers in the cluster is associated with a computer, called their "mayor," that monitors and manages them. The mayors are never used as part of any computation or experiment running on the cluster but are instead used to configure the cluster for that experiment and recover from any problems it might cause. Each mayor is system with a single 550 MHz Pentium III, 512 MBytes of RAM, 10/100 Ethernet, Gigabit Ethernet, and 200 GBytes of SCSI disk. Two of the mayor units have special functions. One serves as the "city mayor" and is used to control the other mayors. The other runs the scheduler for the cluster.
Front ends. Chiba City was originally configured with four front ends: systems that users could login to in order to build their programs and launch them onto the compute nodes. Since these systems are identical to the compute nodes, the users' build environment would be the same as program's execution environment. In practice we found that two front ends was sufficient, and we have used the other two nodes as test systems.
File servers. The two file servers provide file systems via NFS to the login nodes and to the mayors. They house all of the user's home file systems and all of the configuration files (kernels, RPMs, config files, and so on) for the nodes. They do not export file systems directly to the nodes—that's the job of the storage nodes. The file servers have exactly the same hardware configuration as the storage nodes. Each has 500 GBytes of disk.
Nodes We Missed. After a few years of running the cluster, we've concluded that the configuration that we put together is almost correct, but we missed a few pieces.
First, we could use more test systems. Linux kernels, file systems, system software, and applications all change rapidly. Having between four and eight test machines for testing individual pieces of code and cluster functions would be extremely helpful. At present, we usually allocate some of the compute nodes in order to test new software. This procedure works okay, but since it reduces the pool of compute nodes the users can access, it tends to be a short-term solution.
Second, we could use a few spare nodes. We always seem to have a small handful of nodes with hardware problems, which makes it difficult to reliably be able to run jobs on all 256 nodes. We would like to have a pool of spare nodes that we would swap in for a node with broken hardware. Then, once that node was repaired, it would go into the pool of spare nodes. Four spare nodes would probably cover most situations.
We actually considered both of these in the original plan, but for financial reasons they were removed. It's difficult to justify between eight and twelve computers that aren't really being used most of the time.
Logical Configuration
Chiba City is conceptually divided into cluster building units which we call "towns." In our definition, a town consists of a set of computers and a single "mayor" node that manages them. For example, each of the eight towns of computing nodes in Chiba City includes one mayor and thirty-two computing nodes.
In Chiba City, there are eleven towns:
-
8 computing towns, each with 32 computing nodes
-
1 visualization town of 32 visualization nodes
-
1 storage town with the 8 storage nodes
-
1 server/mayor town with the 10 mayors, login nodes, and file servers
The towns are a mechanism to allow scalable management (see Figure 20.2). From a systems administration perspective, we would like to be able to completely manage every node in a town by interacting with its mayor. So, in order to manage the 256 computing nodes in Chiba, one merely needs to manage the 8 mayors of those computing nodes. To accomplish this, the mayor provides boot service, operating system configuration, console management, and file services to each of the other nodes in its town. It monitors those nodes to make sure that they're running correctly. The mayor performs management functions only and never participates in the computing activity of the nodes, so the users of the cluster never work with the mayors directly.

Figure 20.2: A Chiba City town.
In most cases on Chiba City, each mayor monitors 32 nodes. In a few cases, such as the storage town, there are fewer nodes in the town. We chose 32 clients for a number of reasons:
-
Our tests indicated that NFS performed reasonably with 32 clients. Thus, NFS would be an option within a town if we so chose.
-
In a 1024-node cluster, there would be 32 towns of 32 nodes.
-
The hardware for a 32-node town fit nearly perfectly into two racks.
The town relationship is hierarchical. A collection of mayors can be managed by a higher-level mayor in the same way that a collection of nodes is managed by a mayor. In Chiba City, we have one node, which we refer to as the City Mayor, that is responsible for managing each of the mayors. This gives us a single point of control from which the entire cluster can be managed.
The concept of building the larger system out of smaller replicated systems, each with their own server, wasn't a new one. Beyond being a classic computer science technique, it was used to some degree in the IBM SP, has been a standard approach for years in the systems administration community, and was demonstrated on clusters by the Sandia National Laboratories CPlant project.
We've made a number of observations about the mayor/town concept while operating the cluster:
-
The mayor concept has proven its worth over and over. We could not manage the cluster without some sort of hierarchical approach.
-
Some network services already have scalability mechanisms built in, or scale to the size of the cluster. The Dynamic Host Configuration Protocol (DHCP) is one of these. Breaking these down so that it runs on each mayor and supports only the local town isn't worth the time. In other words, some services for the cluster can and should be global.
-
The ratio of clients to mayor is highly dependent on what those clients are doing. With 32 nodes, we're comfortable supporting network booting and remote operating system installation. If we were also supporting high-capacity file systems or other services, we might need to scale down. On the other hand, if every node was largely independent except for monitoring and time service, for example, then we could probably shift to 64 nodes per mayor.
We have often been asked why we call the building blocks "towns." In the early design phases of Chiba City, we talked to a lot of people in a lot of companies who had never heard of clusters before. We had trouble explaining that we wanted to build the cluster out of these subclusters that had a monitoring agent, so we started to call them "towns" as a part of the city metaphor. This explanation helped quite a bit even though, of course, real cities aren't made up of towns that look identical—they're made up of neighborhoods that are usually very different. But the metaphor helped explain the concept, and the name stuck.
Network Configuration
Chiba City has two types of networks—Myrinet and Ethernet. In this section, we describe their configuration and their use.
Myrinet. The Myrinet network is used to support high-speed communication between nodes as part of a user's program, usually related to computation or I/O.
On Chiba City, a high-performance network is essential. Many of the jobs that run on the cluster are bound by the performance of the network: the faster the network, the better the performance of their code. Also, a lot of the computer science research on Chiba is related to communication.
We chose to use Myrinet, a product of Myricom, because it was the most cost-effective high-performance networking solution on the market at the time we purchased the cluster. Myrinet has a number of nice characteristics. It can deliver a full bisection bandwith network between all of the nodes of a cluster. The network cards that we installed can support a theoretical 1.28 Gbps transfer rate, with latencies from process to process in the 10–15 microsecond range.
The specific Myrinet hardware on Chiba City includes 4 Myrinet spine switches, 5 CLOS-64 switches, and 320 Lanai 7.2 NICs. The hosts that usually participate on the Myrinet network include the computing nodes, the visualization nodes, the storage nodes, and the login nodes. In other words, everything except the management nodes and the file servers is typically on Myrinet. At different times over the life of the cluster, we have connected the file servers and mayors to support experiments.
It is possible to run IP over Myrinet, and we do. From an IP standpoint, the Myrinet network is a flat IP subnet and is not accessible from outside of the cluster.
Ethernet. The Ethernet network is used for everything that the Myrinet network isn't. For the most part, this means management functions, remote access, and a fallback communications network for applications if the Myrinet network isn't available.
Figure 20.3 is a diagram of the Ethernet network, which is arranged in a simple tree structure. Each computing, visualization, and storage node is connected via Fast Ethernet to an Ethernet switch near that node. There are 10 Cisco Catalyst 4000s distributed around the cluster, each connecting approximately 32 nodes.
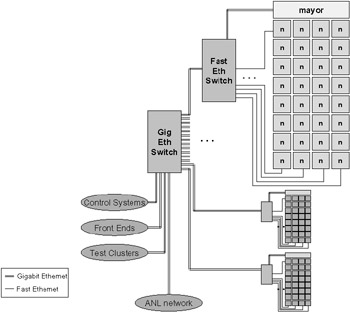
Figure 20.3: The Chiba City Ethernet.
A central Gigabit Ethernet switch, a Cisco Catalyst 6509, is connected to each of the Catalyst 4000s with two channel bonded Gigabit Ethernet links. The remaining computers—the front end nodes, the file servers, and the mayors—all connect directly to the Catalyst 6509. Also, Chiba City's link to the outside world comes in through the Catalyst 6509.
In essence, Chiba City has a completely switched Ethernet. The IP network layered on top of this Ethernet is one flat subnet with no routing. Every node in the cluster is at most three Ethernet switch hops away from every other node.
Physical Configuration
The physical layout of a cluster is particularly important if space is limited, as is the case for us. Chiba City occupies twenty-seven standard 19-inch racks arranged into two rows (see Figure 20.4). The racks include

Figure 20.4: One of two rows of Chiba City.
-
16 racks of computing nodes. Each computing town fits precisely into two racks. This include the 32 compute nodes, the mayor and its disk, the serial and power management systems, and the Ethernet switch for the town.
-
4 racks of storage nodes. The storage nodes and their associated disk each take up half of a rack.
-
2 double-layer shelving units for the visualization nodes. Because of cable length limits for the video systems, these are located in another part of our machine room from the rest of Chiba City.
-
3 racks for the Myrinet switches. These racks have the heaviest cable density in Chiba, because every node has a cable that runs to some port in these racks.
-
1 rack for the file servers and their disk.
-
1 rack for the Gigabit Ethernet switch and remaining servers.
20.1.2 Chiba City Timeline
In this section of the case study, we examine the phases of activity that Chiba City has gone through, starting with the early seeds of the idea up through full-time operation. These are similar to the phases that most other clusters go through.
Phase 1: Motivation
As noted at the beginning of this chapter, the primary driver for Chiba City was to create a testbed that could be used to support scalability testing and research into scalability issues. We believe that this area is the most important aspect of computing to address in order to advance the state of high-performance computing.
Furthermore, we felt that it was important to build a system that could be used for general computer science and development, rather than on applications and simulations, which is typically what large computers are used for.
Before building Chiba City, we had been building and running small clusters for several years, including clusters based on Windows NT, Linux, and FreeBSD. We had used those to support research into communication, visualization, and several other areas of experimentation. But, by fall of 1998, we still had not yet been convinced that the large system in MCS would be a cluster.
However, once we considered the issues of scalability, the need for a computer science testbed, and the price/performance of commodity clusters, it became clear that a large-scale cluster could probably address all of these needs as well as become the next major MCS platform for simulation and computational science.
We originally considered installing a 1024-node system. However, we decided to start with a 256-node system in order to test many of the concepts. Thus, Chiba City was started as the first step toward a thousand-node (or larger) cluster, with a primary goal of supporting scalable computer science and a secondary goal of supporting scientific applications.
Phase 2: Design and Purchase
Having convinced ourselves that a large cluster was the right direction for MCS, we started, in December 1998, to design the system and arrange to purchase it.
We spent the next several months repeating this cycle over and over:
-
Think about what we needed and how we would use it.
-
Talk to vendors, integrators, and the cluster community in order to find out what would be available on our time frame.
-
Consider various funding options and match those with design and availability.
We discovered, among other things, that the traditional set of high-performance computing vendors were all trying to decide what to do about clusters (and what to do about Linux). At the time, it was possible to buy an actual cluster from Compaq and from a number of small integrators, but none of the larger vendors had yet created cluster product lines. No one was selling anything like what we wanted for Chiba City.
Eventually we put together a presentation to use to explain to vendors what we wanted to buy. The presentation explained what clusters were, what the cluster would be used for, how we wanted to operate it, and what we thought the necessary parts might be. As we updated our internal designs for the system software, we updated the purchasing presentation. We talked to a lot of different vendors and then went through the formal purchasing process. Eventually we agreed to buy the system through IBM. IBM arranged to provide subsets of the system from other vendors, including the Ethernet hardware from Cisco, the Myrinet from Myricom, and the 2U compute nodes from VA Linux.
These days, the purchasing phase is a lot easier. Almost every vendor can sell you a small or medium cluster without much thought, and even standard large clusters are relatively simple. However, the very large clusters with focused requirements still require a great deal of interaction with the vendor, as will be described later in this chapter when we discuss Jazz.
Throughout this period, we continued the design of the management infrastructure and system software for Chiba City, developing and testing it on a small cluster. (We called the nodes in the small cluster "the freakies." No one seems to knows why. That small cluster is long gone, but the name continues to live on in code references and machine configurations. Be warned.)
Phase 3: Installation
In October 1999, we installed the cluster.
During the preceding month, truck after truck had backed up to our loading dock and dropped off boxes. We had piles of computers, racks, cables, network boxes, disks, and miscellaneous hardware stacked everywhere. Fortunately we had been through large computer installations before, so we were careful to keep rigorous track of which boxes arrived from which vendor on which truck on which day. Despite this, there were still a few missing boxes that took weeks to locate.
During the purchase phase of the system, we realized that the installation of the cluster would be interesting. While the vendors were willing to provide installation technicians as part of the package, we were the ones who knew how the cluster should be connected. We needed to be actively involved in the installation.
Once we realized this, we decided this was an opportunity rather than a problem. Many of the scientists at Argonne are interested in the details of the computers, and we felt that they would probably enjoy being able to help install the system. We decided to assemble the cluster in the style of an old-fashioned barnraising, inviting everyone to join in. Everyone was enthusiastic about the idea. Over forty people signed up to help.
Before the installation, the MCS Systems Group built one of the computing towns. We took detailed notes on what we did and then put together a twelve-page installation manual. Based on the amount of time it took us and the space to work in the machine room, we estimated that we could build the entire cluster in two days. We spent the day before the barnraising working with technicians from VA to assemble the racks and to put the Ethernet and serial cables under the floor.
The barnraising itself was great fun. We divided the volunteers into teams of four people. Each team was led by a member of the Systems Group or a VA technician. We ran four teams at a time. Each team took half a day to assemble one rack, and each rack was half a town. So, by the end of the first day, four computing towns—half of Chiba City—was assembled.
While the teams worked, lots of other things were going on. IBM engineers assembled the storage nodes. The Chiba development team fine-tuned the software for some initial testing. And, most important, Janet Sayre of the Systems Group created just the right kind of atmosphere by sitting in the middle of all the activity and playing the banjo.
At the end of the second day, we connected all of the towns and booted every node. There were a few minor hardware problems with a few systems, so we weren't able to bring them all up, but we were able to run an MPI job on 248 of the nodes.
A time-lapse video of the barnraising is available on the Chiba City Web page www.mcs.anl.gov/chiba/barnraising/video.html.
Phase 4: Final Development
For the next four months, the cluster was primarily in development mode. While we had demonstrated that the nodes were running an operating system and connected to each other at the end of the barnraising, a lot of work had to be completed before the system was ready for users.
Among other things, we needed to finish the cluster environment: to get a cluster schedule installed, arrange for data management, and tune the communications networks. We also had to get the management system working, including the ability to create user accounts, push out node configuration changes, and so on.
During this time, we asked a few users to try various tests on the system, but it was not available to more than three or four users.
Phase 5: Early Users
Starting in March 2000, we opened up the cluster to the first set of early application users. There were around four early users at first, all of whom were trying to use the cluster but were also providing detailed feedback to us so that we could fix problems they found.
Once things were relatively stable for them, we opened up the cluster to a few more users, and then a few more, and so on. By the end of the early user phase, we had around sixty user accounts on the cluster.
The majority of the problems that we had to address during this time were related to the scheduler and to the Myrinet communication libraries.
Phase 6: Full Operation
In June 2000, we felt that we had eliminated most of problems that would impact users of the system, and we opened up the cluster for general use.
From this point on, account requests for Chiba City were handled in the same way that requests are handled for other MCS computing facilities—the account request is approved based on whether the use matches the mission (and therefore the funding) of the system. These decisions are made by a group of MCS scientists who are responsible for the activities on the MCS systems.
Chiba City has been in full operation mode since that point. The nature of the operational load has shifted—initially it was supporting a lot of computational science interspersed with computer science testing. As the cluster aged, however, many computational scientists shifted to faster platforms while the computer scientists begin to carry out more substantial systems software development and deployment. Fortunately, the cluster was able to support both of these kinds of usage without any modification.
In the future, Chiba will no doubt go through the next phase: gradual obsolescense. At one time, we could have upgraded it, but at this point it will likely make more sense to simply replace it.
20.1.3 Chiba City Software Environment
In this section we examine two aspects of the Chiba City software environment: computing and management.
The Computing Environment
The computing environment on Chiba City was, like the rest of the cluster, optimized to support computer science yet intended to support other uses. In this section, we describe the standard computing environment on the cluster as well as the special modifications we've made to support computer science and scalability research.
The Default Node Environment. The "node computing environment" is the set of programs and services available on the user-accessible nodes of the system, that is, the computing nodes, the visualization nodes, and the login nodes.
All machines in the cluster run Linux by default. The original distribution that we started with when building the node operating system was Red Hat 6.2. Over time, we added and removed RPMs, changed much of the default behavior, and added software from all over. The nodes are still vaguely recognizable as Red Hat, but they could just as easily have been another distribution.
The specific kernel installed by default on the computing nodes varies over time. Intially, it varied a bit more than we would like because we kept running into odd problems that forced us to switch kernels to isolate problems. After the first year of operation, this settled down—we found a kernel version that worked and didn't change it without substantial testing.
Twice in the lifetime of the cluster, we have installed a completely new software image on the entire cluster in order to roll out a global update of new kernels, libraries, and software. These images are tested rigorously on a small set of nodes before they become the default environment. Updating the computing nodes has proven to be relatively simple, while updating the mayors and servers is always complex.
The compilers available on the front end include C, C++, and Fortran 90. Some users also program in Java, Perl, Python, and PHP.
The Default Cluster Environment. The software glue that we use to turn the pile of nodes into a functional cluster includes a number of different packages.
Communications libraries. The vast majority of jobs on Chiba City use MPI for communication. Our preferred version of MPI is MPICH. We have multiple versions of MPICH installed in order to allow users to choose their favorite compiler and flavor of network. To use generic messages over Myrinet, you must link with MPICH-GM from Myricom.
The set of MPICH installations on Chiba got so large, in fact, that we built a small tool that lists all of the MPICH installations and allows you to pick the one you will be working with by default. The number of MPICH installations inspired the MPICH group to provide an alternative for handling multiple compilers; see Section 8.7.6.
Scheduling. We use OpenPBS on Chiba City for queue management. (See Chapter 17 for a detailed discussion of PBS.) OpenPBS is the open source fork of the Portable Batch Scheduler (PBS).
OpenPBS wasn't designed for environments as large or distributed as Chiba City and therefore has some scalability issues. Most of the problems that users of the cluster have had are related to OpenPBS. Many of these have been solved by the community over time, while others remain issues. Becaues OpenPBS is not under active development by a focused author or community, it's not clear that these will ever be solved.
OpenPBS can be interfaced with an external scheduler that makes the decisions about which jobs in the queue will run at what time. We use the Maui scheduler for this purpose (see Chapter 16 for a detailed discussion of the Maui scheduler). We've been quite happy with Maui.
Global file systems. A global file system is one that is available on every node of the cluster and presents the same view of the data in the file system. It is not necessarily capable of supporting high-performance use, but at least provides a common name space. This normally is used for home directories, common applications, and so on.
One of the early design decisions on Chiba City was that we would not use NFS as a global file system on the cluster. NFS performs badly and scales worse. We felt that if it were really necessary, NFS could be made to work on the 256+ nodes of Chiba City, perhaps by using an optimized NFS server such as a Network Appliance box. However, Chiba City is meant in part to be a prototype of a much larger cluster of 1024 nodes or more, and at that level we expect NFS to be useless. Therefore, we decided to try to run the cluster without a global NFS file system to see how it worked out.
This has been an experiment with a clear finding: global file systems are very important.
Because there was no plausible file system alternative at the time we built Chiba City, we avoided NFS by simply not having a global file system.
It's fairly easy to survive without a global file system for administration purposes—one simply uses rdist or other file synchronization mechanisms. On the user side, though, we've had two primary problems:
-
Job staging. The user's program, support files, and data must be copied out to that user's nodes at the beginning of their job. After the job has completed, any output files that were created must be staged off the nodes before the nodes can be used by the next user. We've tackled this problem from a number of angles and have a solution in place that works but is not as fast as we would like. We believe that multicast file copying is the right solution to this problem and will be investigating it in the near future.
-
Confusion. Users tend to expect that the cluster will have a global file system. When they log in to their nodes and look around, they don't see the files they expect in their home file system on that node. Even when the entire environment is explained, it is difficult to use the data transfer tools to copy in the right files and copy out the right files.
Initially, we felt that a global file system would be convenient, but not critical. Based on all the difficulties that the users of the system have had, we now believe that a global file system, even if it performs relatively poorly, is essential.
Parallel file systems. In contrast to a global file system, a parallel file system is specifically meant to provide high-performance access to application data for large parallel jobs. For example, one might store a very large input dataset on a parallel file system and subsequently start an application consisting of a few hundred tasks, all of which simultaneously access portions of this dataset. The parallel file system provides both a single logical space for application processes to look for data files and also the performance necessary for these parallel applications to have timely access to their data.
The only open source parallel file system available on Linux clusters at the time that we installed Chiba City was the Parallel Virtual File System (PVFS), which is described in detail in Chapter 19. PVFS and Chiba have a comfortable relationship, and over the years Chiba has become the primary development platform for PVFS. In this environment PVFS has been proven to scale to hundreds of I/O servers and compute processes, and peak aggregate throughput of over 3 GBytes per second has been shown.
Running at these scales also served to highlight some reliability issues in PVFS that were not evident when running in smaller configurations. As these problems have been addressed and PVFS has begun to stabilize, we have begun to make a PVFS file system available as a full-time resource for the users of Chiba City. This has two benefits for users: it provides a high-performance data storage space for use by applications, and it gives users a single place to store datasets that can be accessed from any node.
Job invocation. Job startup of hundreds of processes using MPICH with its default ch_p4 device is slow. Especially for interactive jobs, something more scalable is needed. Chiba provided some of the motivation for the ch_p4mpd device that made use of an earlier version of the MPD process startup system, described in Section 8.7.3. Chiba City has provided a valuable testbed for the development of the MPD system and the version of MPICH that relies on it for job startup. The MPD daemons can run as root, and we have been using them to run a mix of user jobs.
Parallel Unix commands. Chiba City is also serving as testbed for the Scalable Unix Commands [44], which provide parallel versions of the common Unix commands such as ps and cp. A new version of these [82] is now available at www.mcs.anl.gov/sut. The new version implements these interactive commands as MPI applications, so the fast startup of MPI jobs made possible by MPD is critical. We plan to make these familiar commands available to all users as part of the Chiba environment.
Support for Computer Science. Computer scientists have a few general requirements that conflict with running applications on a system: interactivity, a license to crash the system, and the need to modify the system software.
Interactivity. Computer scientists, as well as developers of all types, often want to use the computer in "interactive" mode. They want to edit code, compile it, and then test it immediately. The test, and even the production run, may last only for a few seconds, but it often needs to use the entire system.
If the computer scientist has to submit a test job in a queue and wait until it can be scheduled, it can take hours or even days to complete a one-minute run. If the scheduler is optimized to allow access to the entire machine quickly, the resulting schedule will have huge numbers of unused node time. Production sites and computers that have real dollars tied to machine utilization simply can't afford to have that type of scheduling policy.
This need for interactivity is not unique to computer scientists, of course. Application developers need interactive test cycles while building code that will eventually run for hours. But many of these developers can get away with testing on a small set of nodes, which is easier to acquire, and computer scientists may never need the entire cluster for more than a few minutes at a time.
On Chiba City, we do run a batch scheduler because we have not yet found a better way to equitably share the system between many users. But we clear the cluster of all jobs every day for a two-hour period, during which time no job longer than five minutes can run. This gives computer scientists a two-hour window every day for quick turnaround. Long-running jobs have to wait until the weekend, when we allow jobs to go from Friday evening until Monday morning.
Also, it's possible to schedule a number of nodes and then simply use them in interactive mode during that timeslot.
License to crash. Some computer scientists and developers work on low-level pieces of code that can have bugs that impact the entire operating system on a node. In some cases, such as in file systems and job managers, they may even crash the entire cluster. It's important to have some kind of facility where code like this can be tested in a real-world environment.
Crashing a node on Chiba, even to the point of requiring a rebuild, is fairly minor. We have remote power control, remote monitoring, and the ability to rebuild a node from scratch. (All of these systems are described in Section 20.1.3.) If a node needs to be rebuilt, we simply set a flag in the City database for that node, and that node's mayor will initiate a rebuild the next time that node reboots. If necessary, the mayor can force the reboot.
Crashing the entire cluster is a bigger problem. Still, we set the expectation that we actively support development of the cluster's system software and that we expect things will occasionally crash. We try to minimize the frequency of these large-scale problems and try to minimize their impact. But in a worst-case situation, we can rebuild all the nodes and reboot in 20–30 minutes.
Modifiable node environment. A small number of developers actually need a completely different node environment. They might be testing a set of device drivers that are unusual, or comparing FreeBSD to Windows XP to Linux. (We actually have run FreeBSD and Windows XP on the computing nodes on Chiba.) In any of these cases, the scientists may need to have root access on their nodes or may want to replace the node operating system entirely for the duration of their job.
We support the ability to arbitrarily modify the node computing environment. The mayors build their nodes from a node "image," where an image is a set of files or binary file system data. The mayor will write that to the node's disk, then boot it.
You can build an image of any operating system desired, as long as it boots. During the time that the nodes are reserved for you by the scheduler, you can do whatever is necessary on those nodes. Once your scheduled time is up, the mayor power cycles the node, catches the booting system, and reinstalls the Chiba City default Linux image on the node. This process is illustrated in Figure 20.5.
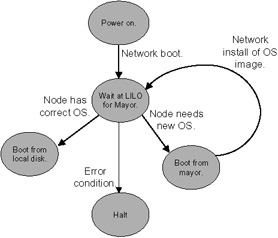
Figure 20.5: Node image management.
Management Environment
Starting with the very first design for the cluster, we put a great deal of emphasis on scalable management of Chiba City. For example, one of our goals was never to have to physically touch a node unless it was having hardware problems.
We emphasized scalable administration because we must. All management functions of a very large system, of which Chiba City is a prototype, must scale for obvious reasons. Furthermore, we need scalable management for Chiba itself. The management team for Chiba City consists of three people who are responsible for all aspects of the administration of the cluster, all user support, the development of management tools and system software, involvement in experiments, and other aspects of the MCS computing environment.
The management approach for Chiba City incorporates a number of philosophies:
-
Support all the needs of the diverse user community, ranging from stable batch-oriented computing to letting individual users have root access on their nodes.
-
Don't change the model too much, because our scientists need to work in the common model to make their tools applicable to others. For example, we couldn't switch over to a shared-memory model of the cluster.
-
Manage from a central point. The mayor/town architecture—in which the city mayor presides over the mayors, each of whom manages a set of nodes—is designed to strongly support central management.
-
Use open source and existing tools as much as possible. As much as we like to invent cooler wheels, we don't have time.
The remainder of this section describes the individual components of the management environment.
City Database. The city mayor keeps a database of relatively static cluster information. We call this database the City Database or "citydb." The database describes the node/mayor relationship, keeps track of which nodes have what types of hardware, and knows which nodes should have which operating system image at which time.
The City Database is different from the database kept by the scheduler, which is much more dynamic. The dynamic database includes job information, which users own which nodes, and which nodes are currently up. Optimally, both databases would be more closely related, but in practice it has been easier for us to keep the functionality split.
The City Database is authoritative. If the database and reality don't match, then reality must be wrong. Using this philosophy, we can describe the desired cluster configuration in the database and then tell the mayors to make sure the cluster conforms to the configuration. The configuration management tools described below take care of this.
Citydb is built on MySQL using standard SQL.
Configuration Management. At the highest level, the configuration model works this way:
-
The configuration for every node is described on the city mayor. Since many nodes are identical, this is not as bad as it might seem.
-
The city mayor is the source for all configuration files, images, and RPMs. All mayors keep a mirror image of those files.
-
When a configuration change is necessary, the administrator makes a change on the city mayor and then invokes a process to push that change out.
-
The nodes themselves are checked at boot up and after user jobs run to make sure that they have the correct configuration.
The primary configuration management tool that we use on Chiba City is a program called sanity. The idea behind sanity is that it can install RPMs, modify configuration files, and execute scripts. It decides what to do based on a configuration file that can be general or very specific to a node. Once it has established that the node matches the configuration in that file, the node is pronounced sane.
The mayors have the ability to invoke sanity on each of their nodes. The nodes also run sanity when they first boot and after a user job completes. The configuration for sanity is an aspect of the image on that node, and the image for each node is recorded in the citydb on the city mayor.
In order to make a change to all of the nodes on the system, one would modify the sanity configuration file for the default image, then invoke a global sanity push on the city mayor. It tells each mayor to kick off a sanity run, and each mayor in turn tells each node to run sanity. This process is illustrated in Figure 20.6.
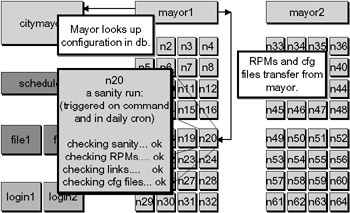
Figure 20.6: OS image management.
Serial Infrastructure. Another tool in the management arsenal is remote console management. The console of every system in Chiba City is available over the network. The system works in the following way:
-
The console port on each node is connected to a serial concentrator for that town.
-
The serial concentrator is connected to the mayor.
-
The mayor runs a daemon called conserver that enables remote access to the console from anywhere on the network that has permission. This daemon is an open source tool that is widely used in the system administration community.
-
From any point on the MCS network, an administrator can type console <node> and get access to the console of that node.
This process is illustrated in Figure 20.7.
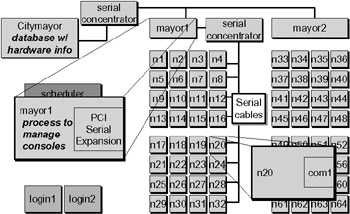
Figure 20.7: Serial infrastructure.
In practice, we use this feature only when debugging. Ideally we don't want to actually have to go to all the consoles of all the nodes. Sometimes, though, a node will quit responding for no reason. It's frequently possible to recover the node via the console—or at least get a hint from the console messages what might have gone wrong.
The conserver daemon has another feature of console management that is also critical to Chiba City. It can log all of the output of any console to a file or to a process. We wrote a program called chex that monitors the output of each console, looking for particular strings. Among other things, this lets us know whether a node is rebooting, whether it has panicked, or whether some other error condition has taken place.
We take advantage of this console monitoring to capture node-specific information such as the node's MAC address. See the section below entitled "The First Boot Process" for an example of why this is useful.
Low-Level Diagnostics. Some motherboards have the ability to provide useful information about the hardware, such as the temperature of the node and the fan speed. Some can also control the power of the system.
The nodes that we are using have this ability. Initially, however, this functionality was accessible only if you used a Windows NT system to monitor the node remotely. Since then, people have created open source software that runs on Linux to manage these ports.
Unfortunately, we have never taken advantage of this system. It would be nice, but we haven't had time to get to it.
Power Control. We do, however, have remote power control for every component of Chiba City. The power control system works as follows:
-
Every computer and network box is plugged into a Baytech power unit. There are, on average, five Baytech units per town.
-
The Baytech unit is somewhat like a power strip with an Ethernet port. It's possible to telnet to the Baytech a







