Hack 21 Spinning Document Portals
![]()
![]()
Help readers navigate your PDF documents with an HTML front-end. Let them search your PDF's full text, and then link search hits directly to PDF pages.
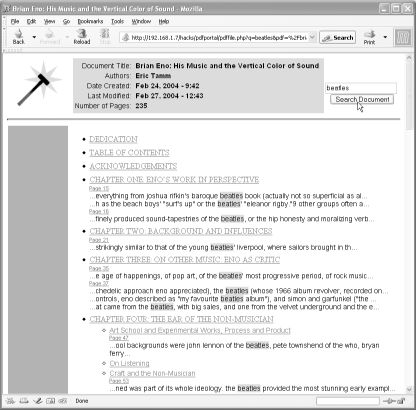
An HTML portal into a PDF document should describe the document, and it should link readers directly to the sections they might need. This hack uses the information locked in a PDF to create its portal page, as shown in Figure 2-12. We automate the process with PHP, so portals are created on demand. An optional search feature enables readers to drill down into the PDF's full text. Visit http://www.pdfhacks.com/eno/ to see an online example.
Figure 2-12. Our automatic HTML portals linking readers directly to PDF sections
In [Hack #70], we discussed how to extract document information from a PDF using pdftk [Hack #79] . Here, we automate the process with PHP, casting the PDF information into a friendly, dynamic web page. Pass a PDF's path into the script and it yields an HTML portal. If the PDF has no bookmarks or metadata (Title, Author, etc.), this portal will look pretty lean. Even so, the search feature will help readers find what they want.
2.8.1 Tool Up
We'll need pdftk [Hack #79] and pdfportal (http://www.pdfhacks.com/pdfportal/). pdftk can extract information from PDF documents, like metadata and bookmarks. pdfportal is a set of PHP scripts that use this document data to create hyperlinked HTML pages.
To install pdfportal, visit http://www.pdfhacks.com/pdfportal/ and download pdfportal-1.0.zip. Unpack the archive and copy its files to a location on your PHP-enabled web server where it can read and execute them. Edit pdfportal.config.php to reflect the location of pdftk on your web server.
If you want to use the pdfportal search feature, you must also have pdftotext [Hack #19] . Pdftotext converts PDF documents into plain text. Edit pdfportal.config.php to reflect the location of pdftotext on your web server.
|

Windows users without access to a PHP-enabled web server can download and install IndigoPerl from http://www.indigostar.com. IndigoPerl is an Apache installer for Windows that includes PHP and Perl support.
2.8.2 Open the Portal
Let's say you copied the pdfportal files to http://localhost/pdfportal/ and you have a PDF named http://localhost/collection/mydoc.pdf. To view this PDF using the portal, pass its path to pdffile.php like so:
http://localhost/pdfportal/pdffile.php?pdf=/collection/mydoc.pdf
pdffile.php calls pdftk to create http://localhost/collection/mydoc.pdf.info, if it doesn't already exist. pdffile.php then uses this plain-text info file to create an HTML page. An info file is simply the output from pdftk's dump_data operation [Hack #64] .
2.8.3 Search the PDF's Full Text
Open your PDF's document portal. If pdffile.php can find pdftotext on your computer (see pdfportal.config.php), it does two things. It uses pdftotext to convert your PDF into a plain-text file, and it activates its search interface. It stores the plain-text file in the same directory as the PDF file.
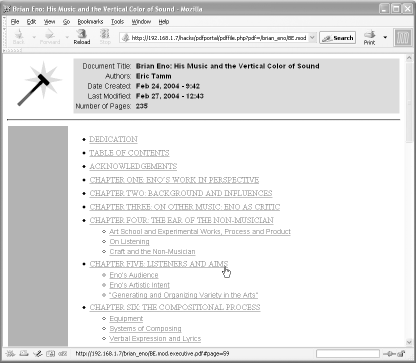
When you submit a search, pdffile.php scans this text file to discover which PDF pages contain your search terms. It reports search hits in reading order, as shown in Figure 2-13. If the PDF has bookmarks, these are used to organize the results. Click a link and the PDF opens to that page.
Figure 2-13. pdfportal's document bookmarks, which organize search results