6.3 File Encoding
This surprisingly critical issue gets slighted in most application development texts. Normally, it comes up in discussions of multiple-language support, but even if you target only English-speaking users, you'll run into encoding when multiple platforms are taken into account.
In its simplest form, ASCII text is a slightly more elaborate version of the simple "secret decoder" that kids play with. The decoder rings would let you map a letter to a number, and you would need the right decoder rings to convert a string of text to numbers (and back to text). ASCII defines a standard set of characters that convert to numbers, with uppercase and lowercase letters, numbers, spaces, and a few extra symbols thrown into the mix.
That said, only seven bits of a number are defined. The eighth bit, often called the high bit, is unspecified. Some systems, such as the Apple II series or the Commodore PET line, use these so-called high-bit characters to generate graphics onscreen. For example, the high-bit letter "r" might draw a smiley face character. There are many high-bit encodings with systems sold to non-English-speaking users who need extra characters for certain languages. Other non-English systems throw out ASCII entirely and use their own character encodings.
When the original Macintosh was released, graphics could be drawn in multiple fonts simultaneously. The smiley face character (and all of its friends) was moved to the Dingbats fonts. Normal user fonts, such as Times, now used the high-bit characters for accents and non-English punctuation. Apple could sell a Macintosh in France with a different keyboard that would generate the proper high-bit characters, and French users could now enter text and share that text with English users without any additional software. Users of Chinese, Japanese, and other pictographic-based systems ended up using double-byte systems, as the 256 slots available to a single 8-bit value could not adequately represent their character sets.
These encodings made multiple-language management a huge undertaking. Developers wound up having to support multiple custom encoding import and export tables, with no standard for normalizing the data.
6.3.1 Enter Unicode
At this point, Unicode entered the scene in an attempt to clear up this large and confusing mess. Unicode defines a single "decoder ring" set of values for pretty much any language you're likely to support (and a great deal beyond, including several dead languages). Thus, a Unicode-aware system maps the A to the number 35, the Japanese character for rice to 11263, and so on. You can be sure that this system will be consistent across character sets, in any language.
However, the Unicode character set is not a standard means of writing (or encoding) these values to disk, or even specifying a method for storing the values in memory. The most popular method for saving and reading Unicode text for persistence (e.g., writing to disk or sending text to another system on the network) is a format called UTF-8. UTF-8 is a multi-byte format, which means that the amount of storage required to save a specific character varies depending on the location of the character in the Unicode number chart. The lower, English values map to the old 7-bit ASCII values. Higher values are "escaped" and represented by two, three, or four characters.
The big problem with UTF-8 is that it is impossible to access linearly; that is, if you load a UTF-8 character stream into memory, you don't know if the 8-bit character at offset 48 is actually character 12, 24, 48, or something else. Java takes care of this by converting all character data internally into UTF-16, a double-byte format. This is what the Java marketing folk mean by Unicode-enabled Java. A Java developer can specify an encoding format, open a text file, and the JVM will convert the text internally from whatever the original text was to UTF-16.
6.3.2 Java, Unicode, and UTF
It's possible to use the standard Java APIs with a character set that is specified programmatically:
java.io.OutputStreamWriter.OutputStreamWriter( OutputStream out, String charsetName )
For information on all of the available character sets and their names, check Sun's online documentation at http://java.sun.com/j2se/1.4.1/docs/guide/intl/encoding.doc.html.
Unfortunately, there is no consistent way for a developer to auto-detect the encoding format of a text file, which means that you'll have to either guess or require that your users know their encoding format. To see how unlikely this latter prospect is, ask your Windows users if they are aware that "Cp1252" is the standard Windows text file encoding format. That said, you can usually assume that a file uses the system's default encoding, which is obtained through the following system property:
System.getProperty("file.encoding")
|

Windows and Mac OS X systems have different defaults for this property, which explains why the topic comes up in a discussion of cross-platform compatibility. You can assume that any high-bit characters a user specifies will cause problems, and with tools like Word and AppleWorks automatically converting straight quotes to curly quotes even for English users, there will probably be high-bit characters sneaking into your text files for any but the most basic applications.
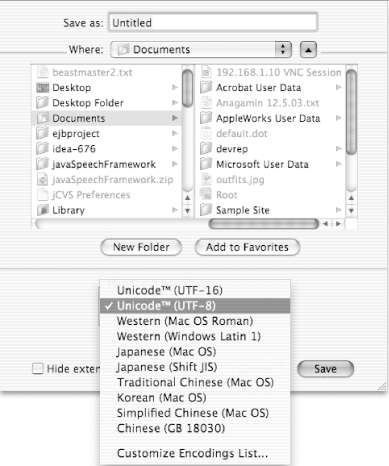
If you expect users to share text files between different platforms, you'll need to decide how you want to manage these encoding issues. If users move files across platforms (or different language operating systems), they will at least have a rudimentary familiarity with language encodings. Consider Figure 6-1, an example of what is presented to a user when he or she saves a text file. In this case, the default encoding is UTF-8, which is probably a safe bet for most operations (especially for exported files and your application's default document saving functionality). UTF-8 shares the same text encoding for the first 127 characters as for normal ASCII; this fact in addition to UTF-8's flexibility and growing popularity make it an ideal choice for your application's default. For sophisticated applications, you should probably add the ability to specify file encodings on a per-file basis as well.
Figure 6-1. TextEdit encodings