Section 9.12. Running Blagg
Blagg may be run in either interactive or automatic mode, aggregating only feeds of the same mode in your rss.dat file. When run in interactive mode, Blagg ignores all feeds marked as automatic and vice versa.
9.12.1 Interactive Blagging
To run Blagg interactively on the Mac OS X or Unix command line, type:
./blagg -mode=interactive
Under Windows, type:
perl blagg -mode=interactive
Blagg starts up, fetches each feed in turn, and asks whether you'd like to blog each story in turn. Type y for yes, n for no, or q to quit, and press the Enter key.
Figure 9-8 shows Blagg aggregating the BoingBoing feed interactively.
Figure 9-8. Interactive Blagging

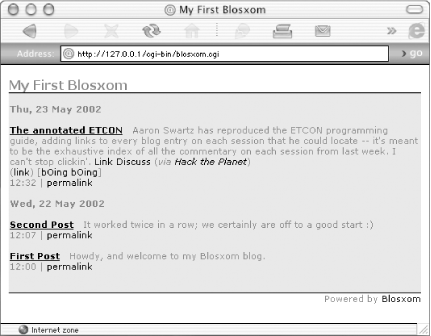
Figure 9-9 shows the annotated ETCON item alongside the previous two weblog entries. Notice Blagg automatically adds a parenthesized (link), linking to the original weblog entry on BoingBoing and bracketed [bOing bOing], linking to the source of the entry, the BoingBoing weblog itself.
Figure 9-9. Interactively aggregated story
9.12.2 Automatic Blagging
To run Blagg automatically on the Mac OS X or Unix command line, type:
./blagg -mode=automatic
Under Windows, type:
blagg -mode=automatic
Blagg starts up, fetches each feed in turn, and quietly adds new stories it finds to your weblog.
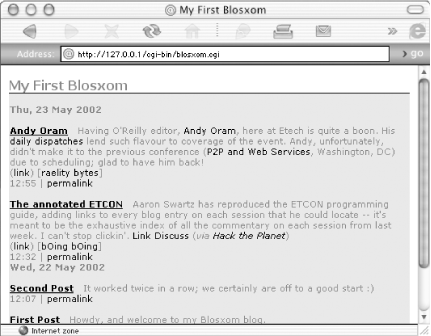
Figure 9-10 shows a new story on Andy Oram appearing just after the annotated ETCON story.
Figure 9-10. Automatically aggregated story
9.12.3 Blagging to Other Blogs
You can use Blagg to aggregate items in weblogs other than the default Blosxom weblog. By adding a -blog=gardening command-line switch, you can can instruct Blagg to read the rss.dat file in the gardening subdirectory under $datadir and blog any entries to your gardening weblog rather than initial weblog.
So if there were an rss.dat file in $datadir/gardening to contain a feed or three, you would interactively aggregate items to the gardening blog like so:
./blagg -mode=interactive -blog=gardening
9.12.4 Under the Hood
If you're curious about what's going on under the hood, it's actually rather simple. For every aggregated story, Blagg simply borrows a slightly fiddled-with version of the title (replacing all but alphanumeric characters with underscores and shortening the whole thing), prepends the feed's nickname specified in the rss.dat file, and pops a .txt extension to the end. The two aggregated items in Figure 9-10 are stored as:
boingboing.The_annotated_E...ETCON.txt raelitybytes.Andy_Oram..._Oram.txt
Each time Blagg is run, it makes sure it doesn't already have a copy of a particular story from a particular source by checking it against the filename.






