11.4 Introducing AmphetaDesk
AmphetaDesk was started by Morbus Iff in January 2001 and continues in development. In this book, we will be working with Version 0.93. Apart from being a very popular tool for reading RSS feeds, AmphetaDesk's internal architecture makes it eminently hackable and a great way to learn how to use RSS feeds in your own programs. It also runs on Windows, Linux, and Mac OS, so most readers will be able to try it out.
The system works like this: the workings are written in Perl and HTML templates and come accompanied by an operating system-specific program that acts as the Perl interpreter. Because of this, you can access and change the source code even while the program is running, and you will see the changes happen immediately. Plus, you can add any feature you like by just dropping the correct Perl module into the right directory and writing a template file to call it.
In this section, we will download AmphetaDesk, install it, and examine how it works, and then move on to customizing it.
11.4.1 Installing AmphetaDesk
Installing AmphetaDesk is simplicity itself?download the latest version from http://www.disobey.com/amphetadesk/, unpack the archive, and save the resulting directory structure and files to wherever you want to keep it. You are then presented with the following files and directories:
- /AmphetaDesk.exe
-
The AmphetaDesk runtime file. This is the file you run to use the program. It contains all the necessary aspects of Perl needed by your machine to go about its RSS-reading business.
- /AmphetaDesk.pl
-
The Perl version of the AmphetaDesk runtime file.
- /data/myChannels.opml
-
An OPML file containing the details of the feeds to which you are subscribed.
- /data/mySettings.xml
-
An XML file containing the user's settings.
- /data/channels/
-
A directory to contain local copies of the subscribed-to feeds.
- /data/internal/
-
This directory contains files created and used as the program is running, namely:
- /data/internal/version.txt
-
This file contains the version number of the AmphetaDesk installation you are using. It is compared at startup with a version on the AmphetaDesk server, and appropriate messages are displayed.
- /data/internal/AmphetaDesk.log
-
This file, recreated every time you run AmphetaDesk, contains the logged messages from the program ? very useful for debugging.
- /data/lists/
-
The directory that stores lists of RSS feeds (called channels in this context) that you can add to your AmphetaDesk display. It consists of:
- /data/lists/services-channels-complete.xml
-
This lists all the channel services that are still publishing something. The feed is not checked for anything at all, bar actually being there to read.
- /data/lists/services-channels-failure.xml
-
This lists all the feeds that have failed to be retrieved correctly three times in a row.
- /data/lists/services-channels-recent.xml
-
This is a cut-down version of the complete list, removing only those feeds known definitively to have not updated within the month.
- /docs
-
The directory that contains the system documentation and one subdirectory:
- /docs/images
-
The directory that contains images for use within the documentation.
- /lib
-
The directory that contains the Perl modules used by the program. It contains:
- AmphetaDesk.pm
-
This controls the data traffic between the different modules and the templates.
- /lib/AmphetaDesk/
-
This directory contains all the original modules used within the workings of AmphetaDesk. These include:
- /lib/AmphetaDesk/Channels.pm
-
AmphetaDesk::Channels handles the parsing of the feed. It takes the feed and returns it in a common data structure, regardless of which version of RSS you are using.
- /lib/AmphetaDesk/ChannelsList.pm
-
AmphetaDesk::ChannelsList handles the channel listing in the "Add a Channel" section of the program. It takes an OPML file and converts it into something more useful for displaying on the screen.
- /lib/AmphetaDesk/MyChannels.pm
-
AmphetaDesk::MyChannels handles all the functions that deal with the user's subscription list.
- /lib/AmphetaDesk/Settings.pm
-
AmphetaDesk::Settings controls the program settings: loading, saving, and providing an API for changing every tweakable configuration.
- /lib/AmphetaDesk/Utilities.pm
-
AmphetaDesk::Utilities provides all the little functions needed to make RSS readers run nicely ? strip_newlines_and_tabs, for example.
- /lib/AmphetaDesk/Versioning.pm
-
AmphetaDesk::Versioning handles the versioning of the package?it checks to see if the installation you are using is the latest, by comparing /data/internal/version.txt with the AmphetaDesk server's mirror.
- /lib/AmphetaDesk/WebServer.pm
-
AmphetaDesk::WebServer provides a subclass of the HTTP::Daemon module used to serve the pages the system creates. As the author says in the comments, "This package is here merely to provide a subclass for HTTP::Daemon so that we can override the product_tokens routine and set our own Server name."
- /lib/AmphetaDesk/WWW.pm
-
AmphetaDesk::WWW provides functions that work to retrieve data from the Net.
- /lib/Text/Template.pm
-
The classic Text::Template module, written by Mark-Jason Dominus, deals with replacing text in templates. As the user interface to AmphetaDesk is written in templates, this module is required to make it work.
- /lib/XML/Simple.pm
-
Our old friend from Chapter 8, XML::Simple is a simple XML parser. AmphetaDesk uses it to make sense of the feeds it retrieves.
- /templates/default
-
The templates directory and its subdirectories hold the template files that AmphetaDesk parses through Text::Template. It is here that we find index.html?the page that displays the feeds' content ? which we will now customize.
11.4.2 index.html
AmphetaDesk works by first downloading the feed and then using Channels.pm to convert it to a common data structure. This lessens the load on the next section, the templates, as they need to give the address of the data they want within only one structure, and not two different versions for 1.0 and 2.0.
If you open index.html in a text editor, you will find, about halfway down, the following code:
foreach my $item (@{$data->{item}}) {
# check to see if mod_content is used, which is a module to RSS 1.0
# allowing more data in a feed as well as embedded HTML. this is NOT
# a full implementation, as it'll only support CDATA's. if it does
# exist, then we stick the data into our $item->{description}.
my $rdf_value = $item->{"content:items"}{"rdf:Bag"}{"rdf:li"}{"content:item"}{"rdf:value"}
if defined($item->{"content:items"}{"rdf:Bag"}{"rdf:li"}{"content:item"}{"rdf:value"});
$item->{description} = $rdf_value if defined($rdf_value);
# display the actual item.
$OUT .= qq{ };
$OUT .= qq{<tr><td width="15" bgcolor="#ffffff"> </td><td bgcolor="#ffffff" align="left">};
$OUT .= qq{<a href="$item->{link}" target="$link_target">} if $item->{link};
$OUT .= qq{$item->{title}} if $item->{title};
$OUT .= qq{</a>} if $item->{link};
$OUT .= qq{ $item->{description} } if $item->{description};
$OUT .= qq{</td></tr>\n};
}
As you can see, this will step through each item in the feed, take the contents of the link, title, and description elements, and output some HTML with the form:
<a href="LINK" target="_blank">TITLE</a> DESCRIPTION
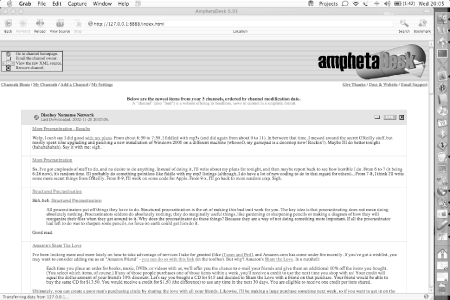
Those links are surrounded by some table markup to make them look pretty, as shown in Figure 11-1.
Figure 11-1. A screenshot of AmphetaDesk displaying a feed
Adding code to this template to allow it to display your module is therefore quite straightforward. Note the section of the code that does the work:
$OUT .= qq{<a href="$item->{link}" target="$link_target">} if $item->{link};
$OUT .= qq{$item->{title}} if $item->{title};
$OUT .= qq{</a>} if $item->{link};
$OUT .= qq{$item->{description} } if $item->{description};
$OUT .= qq{</td></tr>\n};
By slipping in our own code, we can take the value we want from our module. In this case, I'd like to allow people to buy one of the books in my feed from the popular online store Amazon.com.
By experimentation, I know that the URL http://www.amazon.com/exec/obidos/ASIN/ followed by the ISBN number will lead to the correct page. This seems to be a good use for the book:isbn element.
I also know that people using my module might not have included a description element. So, I will want to get book:openingPara in there somewhere.
No problem:
$OUT .= qq{<a href="$item->{link}" target="$link_target">} if $item->{link};
$OUT .= qq{$item->{title}} if $item->{title};
$OUT .= qq{</a>} if $item->{link};
$OUT .= qq{<a href="http://www.amazon.com/exec.obidos/ASIN/$item->{"book:isdn"}">
Buy At Amazon</a>} if $item->{"book:isdn"};
$OUT .= qq{$item->{description} } if $item->{description};
$OUT .= qq{<blockquote>$item->{"book:openingPara"}</blockquote> } if $item->{"book:openingPara"};
$OUT .= qq{</td></tr>\n};
Note that whereas $item->{title} produces the value of the title element, if you want to bring in a namespaced element, you need to wrap it in quotes:
$item->{"book:openingPara"}
If you save index.html and refresh it in your browser, you will find that the template will now display mod_Book information. Cool, huh?
You can now add support for your own modules in the same way. Be sure to pass any changes you make back to Morbus Iff at http://www.disobey.com/amphetadesk. He will likely include it in the next release, and you will have made the RSS world a better place for it.






