5.2 Resource Description Framework
This system of defining everything with URIs, and using this to describe the relationships between things, has been formalized in a system known as the Resource Description Framework (RDF). In this section, we'll look at enough RDF to give us a head start on the rest of the book. For a much deeper insight into RDF, take a look at Shelley Powers' Practical RDF (O'Reilly).
Because RDF is quite abstract ? its ability to be written in different ways notwithstanding ? in this chapter we are going to look at what the RDF developers call the "data model," which we can call "the really simple version, in pictures."
5.2.1 Resources, PropertyTypes, and Properties
As before, within the data model anything (an object, a person, a document, a concept, a section of a document, etc.) can have a URI. In RDF we call anything addressable with a URI a resource.
Some resources can be used as properties of other resources. For example, the concept of "Author" has a URI of its own (all concepts can), and other resources can have a property of "author". Such resources are called PropertyTypes.
A property is the combination of a resource, a PropertyType, and a value. For example, "The Author of Content Syndication with RSS is Ben Hammersley." The value can be a string ("Ben Hammersley" in the previous example), or it can be another resource?for example, "Ben Hammersley (resource) has a home page (PropertyType) at http://www.benhammersley.com (resource)."
5.2.2 Nodes and Arcs
RDF's data model uses diagrams, called RDF graphs, to show the relationships between resources, PropertyTypes, and properties. Within these diagrams, the RDF world is split into nodes and arcs.
The resources and the values are the nodes, identified by their URIs. The PropertyTypes are the arcs, representing connections between nodes. The arcs themselves are also described by a URI.
Figure 5-1 is an RDF graph that shows the previous managingEditor example as three nodes, connected by two arcs ? two separate RDF triples. By convention, the subject is at the blunt end of the arrow, the property (or predicate) is the arrow itself, and the object is at the pointy end of the arrow.
Figure 5-1. A simple RDF graph

In Figure 5-1, the subject node on the left, representing the URI http://www.example.org/example.rss, has a relationship with the object node on the right, representing the URI editor@oreilly.com, and this relationship is defined by the URI http://purl.org/rss/1.0/modules/rss091#managingEditor. The subject node also has a relationship with another object node, representing the URI http://purl.org/rss/1.0/channel, and that relationship is defined by the URI http://www.w3.org/199/02/22-rdf-syntax-ns#type.
What makes things interesting with RDF is that, as we've said before, a node can be both a subject and an object in a chain of node, arc, node, arc, node, and so on (or, to put it another way, resource, PropertyType, resource, PropertyType, resource, and so on). Consider the graph in Figure 5-2.
Figure 5-2. Taking a triple further
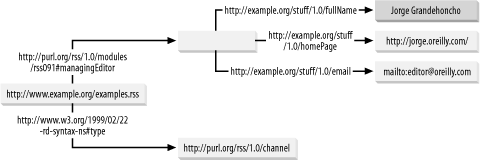
In this example, we've taken the RDF graph a step further. We've created a resource to represent the managing editor (you'll notice that the managing editor resource itself is anonymous ? we have not defined it with a URI yet, hence the empty rectangle?this is not a problem), but given resources of its own, with PropertyType arcs whose URIs represent the managing editor's full name, home page, and email address.
This allows us to make some definitive statements:
The channel (where the concept of "channel" is identified by the URI http://purl.org/rss/1.0/ and the channel itself is identified by the URI http://www.example.org/example.rss) has a resource called managingEditor (which is part of a concept defined by the URI http://purl.org/rss/1.0/modules/rss091#), which in turn has one resource of its own, identified as a "home page" in the context of the URI http://example.org/stuff/1.0/, which is itself identified with the URI http://jorge.oreilly.com/. It also has two properties, fullName and email, both in the context of the URI http://example.org/stuff/1.0/, with the values Jorge Grandehoncho and mailto:editor@oreilly.com, respectively.
Or to put it simply:
This channel has a managing editor whose name is Jorge Grandehoncho, whose home page is http://jorge.oreilly.com/, and whose email address is editor@oreilly.com.
You should bear two things in mind. First, the continuation of the RDF graph need not be constrained to one RDF document. The preceding example can be extended by including more RDF data at the network-retrievable version of the resource's URIs. So, while the RDF data for this book may refer to me solely by author, PropertyType, and a URI, the RDF at that URI could also refer to other things I have written, and those articles could contain RDF data that refers to the subjects of the articles. This distributed nature of RDF allows for vast fields of statements to be made definitively, and every additional set of RDF data increases the power of the whole considerably.
Second, and this will become key in Chapter 7, because the PropertyTypes ? the possible relationships between nodes ? are represented by a URI, anyone can develop a set of elements. RDF vocabularies, therefore, can be developed to describe anything. And, as long as the URI is unique, RDF parsers will not get confused. Your descriptive powers, therefore, are endless ? either an RDF vocabulary exists, or it is simple to make up your own.
Outside the scope of this book, there are also various languages for describing RDF vocabularies, or ontologies.
5.2.3 Fitting RDF with RSS
This system for creating definitive statements from metadata fits perfectly with the aims of RSS. RSS feeds are, at their core, collections of resources with implicit relationships, and RDF is designed to describe these relationships. Also, and most powerfully, RDF makes these relationships explicit in a way that allows for them to be used.
For example, the RDF graph can be travelled in any direction. The statement "This document (subject/resource) was written (predicate/PropertyType) by Ben Hammersley (object/resource)" can be read from the other end of the graph: "Ben Hammersley (subject/resource) wrote (predicate/PropertyType) this document (object/resource)."
So, you can query a database of RDF-based documents for "all the documents written by Ben Hammersley." If more triples are declared within the documents, you can query for "all the documents written by the man with the email address ben@benhammersley.com," or even "all the documents written by the man with the email address ben@benhammersley.com, and which are on the subject of dates." To take it even further, you can query for "all the documents written by the man with the email address ben@benhammersley.com, and which are on the subject of dates (in the context of small fruits, but not romantic encounters)." By taking different paths through an RDF graph, we can extract all sorts of data quite easily.
The ability of RDF to allow complex querying is one definite attraction, but the implications go further than that. Because RDF works just as well distributed as in a database, publishing an RDF version of RSS provides a remarkably useful entry point for the RDF world to access your site. Also, because the RDF vocabularies are easily definable, anyone can invent one. This makes RDF both wide ranging and fast growing, but in a way that does not require a single standards overlord. In the language of RSS 1.0, RDF is extensible.






