Introduction
Perl provides three fundamental data types: scalars, arrays, and hashes. It's certainly possible to write many programs without complex records, but most programs need something more sophisticated than simple variables and lists.
Perl's three built-in types combine with references to produce arbitrarily complex and powerful data structures. Selecting the proper data structure and algorithm can make the difference between an elegant program that does its job quickly and an ungainly concoction that's glacially slow to execute and consumes system resources voraciously.
The first part of this chapter shows how to create and use plain references. The second part shows how to create higher-order data structures out of references.
References
To grasp the concept of references, you must first understand how Perl stores values in variables. Each defined variable has associated with it a name and the address of a chunk of memory. This idea of storing addresses is fundamental to references because a reference is a value that holds the location of another value. The scalar value that contains the memory address is called a reference. Whatever value lives at that memory address is called its referent. See Figure 11-1.
Figure 11-1. Reference and referent

The referent could be any built-in type (scalar, array, hash, ref, code, or glob) or a user-defined type based on one of the built-ins.
Referents in Perl are typed. This means, for example, that you can't treat a reference to an array as though it were a reference to a hash. Attempting to do so raises a runtime exception. No mechanism for type casting exists in Perl. This is considered a feature.
So far, it may look as though a reference were little more than a raw address with strong typing. But it's far more than that. Perl takes care of automatic memory allocation and deallocation (garbage collection) for references, just as it does for everything else. Every chunk of memory in Perl has a reference count associated with it, representing how many places know about that referent. The memory used by a referent is not returned to the process's free pool until its reference count reaches zero. This ensures that you never have a reference that isn't validno more core dumps and general protection faults from mismanaged pointers as in C.
Freed memory is returned to Perl for later use, but few operating systems reclaim it and decrease the process's memory footprint. This is because most memory allocators use a stack, and if you free up memory in the middle of the stack, the operating system can't take it back without moving the rest of the allocated memory around. That would destroy the integrity of your pointers and blow XS code out of the water.
To follow a reference to its referent, preface the reference with the appropriate type symbol for the data you're accessing. For instance, if $sref is a reference to a scalar, you can say:
print $$sref; # prints the scalar value that the reference $sref refers to $$sref = 3; # assigns to $sref's referent
To access one element of an array or hash whose reference you have, use the infix pointer-arrow notation, as in $rv->[37] or $rv->{"wilma"}. Besides dereferencing array references and hash references, the arrow is also used to call an indirect function through its reference, as in $code_ref->("arg1", "arg2"); this is discussed in Recipe 11.4. If you're using an object, use an arrow to call a method, $object->methodname("arg1", "arg2"), as shown in Chapter 13.
Perl's syntax rules make dereferencing complex expressions trickyit falls into the category of "hard things that should be possible." Mixing right associative and left associative operators doesn't work out well. For example, $$x[4] is the same as $x->[4]; that is, it treats $x as a reference to an array and then extracts element number four from that. This could also have been written ${$x}[4]. If you really meant "take the fifth element of @x and dereference it as a scalar reference," then you need to use ${$x[4]}. Avoid putting two type signs ($@%&) side-by-side, unless it's simple and unambiguous like %hash = %$hashref.
In the simple cases using $$sref in the previous example, you could have written:
print ${$sref}; # prints the scalar $sref refers to
${$sref} = 3; # assigns to $sref's referent
For safety, some programmers use this notation exclusively.
When passed a reference, the ref function returns a string describing its referent. (It returns false if passed a non-reference.) This string is usually one of SCALAR, ARRAY, HASH, or CODE, although the other built-in types of GLOB, REF, IO, Regexp, and LVALUE also occasionally appear. If you call ref on a non-reference, it returns an empty string. If you call ref on an object (a reference whose referent has been blessed), it returns the class the object was blessed into: CGI, IO::Socket, or even ACME::Widget.
Create references in Perl by using a backslash on things already there, or dynamically allocate new things using the [ ], { }, and sub { } composers. The backslash operator is simple to use: put it before whatever you want a reference to. For instance, if you want a reference to the contents of @array, just say:
$aref = \@array;
You can even create references to constant values; future attempts to change the value of the referent cause a runtime exception:
$pi = \3.14159; $$pi = 4; # runtime error
Anonymous Data
Using a backslash to produce references to existing, named variables is simple enough for implementing pass-by-reference semantics in subroutine calls, but for creating complex data structures on the fly, it quickly becomes cumbersome. You don't want to be bogged down by having to invent a unique name for each subsection of the large, complex data structure. Instead, you allocate new, nameless arrays and hashes (or scalars or functions) on demand, growing your structure dynamically.
Explicitly create anonymous arrays and hashes with the [ ] and { } composers. This notation allocates a new array or hash, initializes it with any data values listed between the pair of square or curly brackets, and returns a reference to the newly allocated aggregate:
$aref = [ 3, 4, 5 ]; # new anonymous array
$href = { "How" => "Now", "Brown" => "Cow" }; # new anonymous hash
Perl also implicitly creates anonymous data types through autovivification. This occurs when you indirectly store data through a variable that's currently undefined; that is, you treat that variable as though it holds the reference type appropriate for that operation. When you do so, Perl allocates the needed array or hash and stores its reference in the previously undefined variable.
undef $aref;
@$aref = (1, 2, 3);
print $aref;
ARRAY(0x80c04f0)
See how we went from an undefined variable to one with an array reference in it without explicitly assigning that reference? Perl filled in the reference for us. This property lets code like the following work correctly, even as the first statement in your program, all without declarations or allocations:
$a[4][23][53][21] = "fred"; print $a[4][23][53][21]; fred print $a[4][23][53]; ARRAY(0x81e2494) print $a[4][23]; ARRAY(0x81e0748) print $a[4]; ARRAY(0x822cd40)
Table 11-1 shows mechanisms for producing references to both named and anonymous scalars, arrays, hashes, functions, and typeglobs. (See the discussion of filehandle autovivification in the Introduction to Chapter 7 for a discussion of anonymous filehandles.)
|
Reference to |
Named |
Anonymous |
|---|---|---|
|
Scalar |
\$scalar |
\do{my $anon} |
|
Array |
\@array |
[ LIST ] |
|
Hash |
\%hash |
{ LIST } |
|
Code |
\&function |
sub { CODE } |
|
Glob |
*symbol |
open(my $handle, ...); $handle |
Figure 11-2 and Figure 11-3 illustrate the differences between named and anonymous values. Figure 11-2 shows named values, and Figure 11-3 shows anonymous ones.
Figure 11-2. Named values
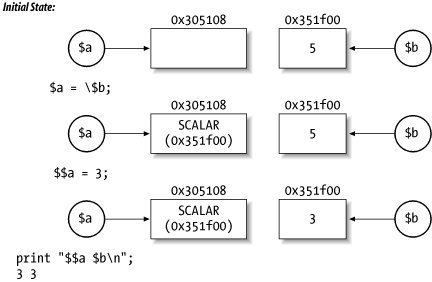
Figure 11-3. Anonymous values
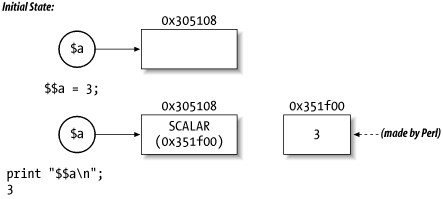
In other words, saying $a = \$b makes $$a and $b the same piece of memory. If you say $$a = 3, then $b is set to 3, even though you only mentioned $a by name, not $b.
All references evaluate to true when used in Boolean context. That way a subroutine that normally returns a reference can indicate an error by returning undef.
sub cite {
my (%record, $errcount);
...
return $errcount ? undef( ) :  record;
}
$op_cit = cite($ibid) or die "couldn't make a reference";
record;
}
$op_cit = cite($ibid) or die "couldn't make a reference";
Without an argument, undef produces an undefined value. But passed a variable or function as its argument, the undef operator renders that variable or function undefined when subsequently tested with the defined function. However, this does not necessarily free memory, call object destructors, etc. It just decrements its referent's reference count by one.
my ($a, $b) = ("Thing1", "Thing2");
$a = \$b;
undef $b;
Memory isn't freed yet, because you can still reach "Thing2" indirectly using its reference in $a. "Thing1", however, is completely gone, having been recycled as soon as $a was assigned \$b.
Although memory allocation in Perl is sometimes explicit and sometimes implicit, memory deallocation is nearly always implicit. You don't routinely have cause to undefine variables. Just let lexical variables (those declared with my) evaporate when their scope terminates; the next time you enter that scope, those variables will be new again. For global variables (those declared with our, fully-qualified by their package name, or imported from a different package) that you want reset, it normally suffices to assign the empty list to an aggregate variable or a false value to a scalar one.
It has been said that there exist two opposing schools of thought regarding memory management in programming. One school holds that memory management is too important a task to be left to the programming language, while the other judges it too important to be left to the programmer. Perl falls solidly in the second camp, since if you never have to remember to free something, you can never forget to do so. As a rule, you need rarely concern yourself with freeing any dynamically allocated storage in Perl,[1] because memory managementgarbage collection, if you wouldis fully automatic. Recipe 11.15 and Recipe 13.13, however, illustrate exceptions to this rule.
[1] External subroutines compiled in C notwithstanding.
Records
The predominant use of references in Perl is to circumvent the restriction that arrays and hashes may hold scalars only. References are scalars, so to make an array of arrays, make an array of array references. Similarly, hashes of hashes are implemented as hashes of hash references, arrays of hashes as arrays of hash references, hashes of arrays as hashes of array references, and so on.
Once you have these complex structures, you can use them to implement records. A record is a single logical unit comprising various different attributes. For instance, a name, an address, and a birthday might compose a record representing a person. C calls such things structs, and Pascal calls them RECORDs. Perl doesn't have a particular name for these because you can implement this notion in different ways.
The most common technique in Perl is to treat a hash as a record, where the keys of the hash are the record's field names and the values of the hash are those fields' values.
For instance, we might create a "person" record like this:
$person = { "Name" => "Leonhard Euler",
"Address" => "1729 Ramanujan Lane\nMathworld, PI 31416",
"Birthday" => 0x5bb5580,
};
Because $person is a scalar, it can be stored in an array or hash element, thus creating groups of people. Now apply the array and hash techniques from Chapter 4 and Chapter 5 to sort the sets, merge hashes, pick a random record, and so on.
The attributes of a record, including the "person" record, are always scalars. You can certainly use numbers as readily as strings there, but that's no great trick. The real power play happens when you use even more references for values in the record. "Birthday", for instance, might be stored as an anonymous array with three elements: day, month, and year. You could then say $person->{"Birthday"}->[0] to access just the day field. Or a date might be represented as a hash record, which would then lend itself to access such as $person->{"Birthday"}->{"day"}. Adding references to your collection of skills makes possible many more complex and useful programming strategies.
At this point, we've conceptually moved beyond simple records. We're now creating elaborate data structures that represent complicated relationships between the data they hold. Although we can use these to implement traditional data structures like linked lists, recipes in the second half of this chapter don't deal specifically with any particular structure. Instead, they give generic techniques for loading, printing, copying, and saving generic data structures. The final program example demonstrates creating binary trees.
See Also
Chapters 8 and 9 of Programming Perl; perlref(1), perlreftut(1), perllol(1), and perldsc(1)







