3.4 Connection Pooling
Connection pooling recycles a set of open connections to save time?a key requirement in enterprise-level database applications. Without connection pooling, your application might be able to support a large throughput but will provide poor scalability. For example, you might find that your system can easily handle 10 simultaneous clients performing 1,000 transactions/minute but falters with 1,000 clients performing 10 transactions/minute, even though the overall transaction throughput is the same.
The problem is that acquiring a database connection automatically imposes some overhead. This is because the process of establishing a connection requires several lower-level operations, including a verification of security credentials. If your system is characterized by a large number of clients that frequently connect, perform a single operation, and then disconnect, the overhead required to create connections can become a crippling bottleneck. This is typical in a large stateless distributed application, such as an ASP.NET web site or web service.
To counteract this effect, most database access frameworks support connection pooling. Connection pooling works by retaining a pool of available connections. When a client requests a connection, it's served directly from the available pool, rather than recreated. In a large system with a quick turnover of database connections, this automatic reuse can save CPU cycles and network bandwidth.
ADO.NET doesn't include a connection-pooling mechanism. However, most ADO.NET providers do implement some form of connection pooling. In the case of the SQL Server and Oracle providers, this connection pooling mechanism is written entirely in managed code. In the case of the OLE DB and ODBC providers, this connection pooling depends on a lower level and has a few limitations. Most providers enable connection pooling automatically. However, you may be able to use connection string parameters to configure pool size settings.
All forms of connection pooling work by examining the connection string. A connection is reused only if the connection string matches exactly. Most ADO.NET providers use a case-sensitive full-text matching algorithm. This means that even if you have the same connection string parameters, but they are in a different order, the connections isn't reused. (The ODP .NET provider from Oracle is one exception.) To ensure that your connections can be reused, store the connection string in a single location (such as a configuration file) and don't enter it directly in your code.
The following example demonstrates how connection pooling works with a single Connection object:
string conString1 = "Data Source=localhost;" + "Initial Catalog=Northwind;Integrated Security=SSPI"); string conString2 = "Data Source=localhost;" + "Initial Catalog=pubs;Integrated Security=SSPI"); SqlConnection con = new SqlConnection(); con.ConnectionString = conString1; con.Open(); // The initial pool is created (we'll call it pool A). con.Close() // The connection is returned to pool A. con.ConnectionString = conString2; con.Open(); // A new pool is created (pool B), because the connection strings differ. con.Close() // This connection is returned to pool B. con.ConnectionString = conString1; con.Open(); // The open connection from pool A is reused. This saves time. con.Close() // The connection is returned to pool A.
You'll notice several important factors in this example:
It doesn't matter whether you are using one Connection object or several Connection objects. When you call Close( ), the underlying connection is placed in the pool. When you call Open( ), the provider searches the pool for available connections.
Connections are reused only if the parameters match. This makes sense?in the previous example, you wouldn't reuse a connection to the Northwind database if the client thinks it is opening a connection to the pubs database. Similarly, a change in security information (for example, the user account and password) or the location of the database server would cause problems if connections were reused indiscriminately.
If no pool exists, it is created the first time you call Open( ). Depending on connection string settings, the pool may be initially populated with a set number of connections, or it may be limited to a certain maximum number.
3.4.1 SQL Server and Oracle Connection Pooling
With SQL Server, Oracle, and MSDE, connection pooling is implemented by the managed provider, unless you have specifically disabled it with a connection string parameter.
Both the SQL Server and Oracle .NET providers give you some control over connection pooling with the connection string parameters in Table 3-5. Note that if you require a minimum pool size, the application incurs a small performance overhead when the first client connects, and the initial pool of connections is created. Note also that the connections are created one after the other, ensuring that the database server isn't flooded with simultaneous requests when the pool is first created.
|
Parameter |
Description |
|---|---|
Connection Lifetime |
Specifies a time interval in seconds. If a connection is returned to the pool, and it is older than the specified Connection Lifetime, it is destroyed. The default is 0, which disables this behavior. This feature is useful primarily when you need to recycle a large number of connections at once, such as when you want to balance the load with a new server that has just been brought online. |
|
Connection Reset[1] |
If true (the default), the connection state is reset when a pooled connection is reused. This setting requires an extra round trip but makes for easier programming (and is recommended). State includes session-level SET statements and the currently selected database. |
Enlist |
When true (the default), the connection is enlisted in the current transaction context of the creation thread. |
Max Pool Size |
The maximum number of connections allowed in the pool (defaults to 100). |
Min Pool Size |
The minimum number of connections always retained in the pool (defaults to 0). |
Pooling |
When true (the default), the connection object is drawn from the appropriate pool or, if necessary, is created and added to the appropriate pool. |
[1] This property isn't supported by the Oracle .NET provider.
As with all forms of connection pooling, every pool is divided into multiple transaction-specific pools (and one pool for connections that aren't currently enlisted in a transaction). Fortunately, this process is managed transparently, and threads associated with a particular transaction context automatically receive a connection from the appropriate pool. However, it does mean that using client-initiated transactions can reduce the efficacy of connection pooling.
3.4.2 OLE DB and ODBC Connection Pooling
OLE DB connection pooling doesn't need to be explicitly enabled because it uses the built-in OLE DB session pooling features. However, OLE DB connection pooling doesn't support explicit configuration of thresholds and pool sizes. Thus, it is technically possible to actually achieve better performance by disabling connection pooling and implementing COM+ object pooling in its place. However, this is a complex task, and isn't recommended unless you are comfortable with terms such as manual transaction enlistment.[2] Microsoft provides OLE DB developer documentation that includes more information about this low-level process. The first step is to disable OLE DB resource pooling and automatic transaction enlistment by including OLE DB Services=-4 in the connection string.
[2] If you'd still like to dive right into to this topic, try the excellent OLE DB developer documentation on MSDN at http://msdn.microsoft.com/library/en-us/oledb/htm/oledb_providers_overview.asp.
The ODBC .NET provider uses the connection pooling that's implemented by the ODBC driver. You can configure pooling settings for ODBC drivers using the Connection Pooling tab in the Data Sources window.
3.4.3 Connection Pooling and Application Domains
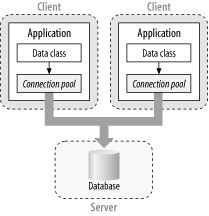
One caveat applies with the managed connection pooling mechanisms in the SQL Server and Oracle providers: connections can be pooled only in a single application domain. In other words, if your system is made up of Windows clients that use your custom data access class locally, they can't share a pool of connections. Instead, they each have their own local pool of connections, which is far less useful. Figure 3-1 shows this situation.
Figure 3-1. Direct database access: no connection pooling
To allow connection pooling, you need to host the custom data class out-of-process on a separate server, using ASP.NET, web services, or .NET remoting. In the case of ASP.NET and web services, the ASP.NET worker threads share a common pool of connections. With remoting, every component host shares a connection pool. Figure 3-2 diagrams this approach.
Figure 3-2. Using a remote data class: connection pooling is possible

Of course, that doesn't mean you should replace local data classes with a more complex architecture based on web services or remoting. In fact, if you do, you could actually harm performance in a small-scale system. Communicating with an out-of-process component is an order of magnitude slower than communicating with a local in-memory object. When you also factor in the time taken to send a call over a network or serialize a message to XML, the latency becomes a noticeable drag on performance.
What you are faced with is a tradeoff between sheer performance for small numbers and scalability. Using clients with local data classes ensures the best performance for small numbers of clients, but the system will reach a bottleneck as the number of users increases and, under a large enough load, start to perform horribly. Using connection pooling with remoting or web services gives you the chance to ensure optimal scalability for large numbers of clients. But performance as measured by application speed isn't the only issue. The maintainability, extensibility, reusability, consistency, and security of the system all need to be explored. Good architecture and design is about balance of these factors, and for many developers architecting mid-size systems, performance isn't a key driving factor.
3.4.4 Connection Pooling and Performance Counters
With large-scale distributed systems that handle thousands of clients, it's important to carefully choose the maximum connection pool size. Determining the correct size requires a little insight, some real-world experience, and a healthy dose of trial-and-error profiling. It depends on the number of clients, the pattern of usage, and the server hardware. This section will help with the insight.
To gauge the best pool size, you can use performance counters. By
default, .NET includes a set of performance counters that work with
the managed SQL provider. To work with them, choose Programs
![]() Administrative Tools
Administrative Tools ![]() Performance from the Start menu. Right-click on the graph, and choose
Add Counter. Under the .NET CLR Data group is a series of useful
counters for monitoring connection pool usage. The counters are
described in Table 3-6. All these counters provide
two options: a global total or a process-specific total (you simply
choose the corresponding application name).
Performance from the Start menu. Right-click on the graph, and choose
Add Counter. Under the .NET CLR Data group is a series of useful
counters for monitoring connection pool usage. The counters are
described in Table 3-6. All these counters provide
two options: a global total or a process-specific total (you simply
choose the corresponding application name).
|
Counter |
Description |
|---|---|
|
Current # connection pools |
Current number of pools. Each pool contains a group of connections that can be reused for different clients. Separate pools will be created for requests with different connection strings or for connections in different transaction contexts. |
|
Current # pooled and nonpooled connections |
The total number of connections, including those in the pool. |
|
Current # pooled connections |
The total number of connections currently in the pool. |
|
Peak # pooled connections |
The highest number of pooled connections that was reached since the .NET process was started. |
|
Total # failed commands |
The total number of SQL commands that have failed for any reason. Not directly related to connection pooling, but can suggest other problems. |
|
Total # failed connects |
The total number of connection attempts that have failed for any reason. Not directly related to connection pooling, but can suggest other problems. |
The .NET data counters can be added to the graph and logged through the MMC Performance snap-in, or you can use a dedicated testing tool such as Microsoft Application Center Test. In a typical test, you might measure the pool-usage statistics and record the performance of your application using a machine-specific counter simultaneously. This test allows you to see how the performance is affected by different numbers of users and usage patterns.
|








