5.2 Good Practices
We'll start by describing many good things that you (or someone in your organization) ought to be doing.
You'll notice, we expect, that the following lists read largely like texts on how to secure an operating system or network. They are indeed a start in that direction. We don't want to leave the impression, however, that our lists are comprehensive. We invite you to read more detailed descriptions of how to secure your operating system separately. After all, many of the elements that we cite can?and have?been turned into entire volumes by themselves! [1]
[1] A more complete list of books and documents are available in Appendix A, but some of the best known ones on the subject of Unix are Practical Unix & Internet Security (now in its third edition) by Simson Garfinkel, Gene Spafford, and Alan Schwartz, as well as the Unix Security Checklist from AusCERT (www.auscert.org.au/).
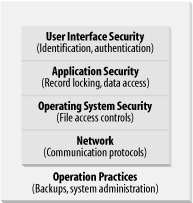
Still, these lists (which are directly derived from our experiences in assessing business applications) should stand you in good stead. We've layered the principles, starting with guidelines for networks and progressing up through operations procedures. (Figure 5-2 shows the layers more graphically.) One caution, however: make sure to consider the list as whole, and don't get caught in the trap of thinking that only one aspect of security is relevant to your job function.
Figure 5-2. Layers of security and operational practices
5.2.1 Batten Down the Network Environment
The security of most modern applications begins with the network on which they operate. One measure of a well-run data center is that the operations manager should know the business purpose for every packet of data that traverses the network. Don't laugh! We've seen examples of data centers that are that tightly configured. It's good for reliable operations as well as for the security of the environment.
- Allow essential network services only
-
When you're deploying a business application in a production data center, you should only allow, onto and out of the network, those network protocols or services that are vital to that application. This may require some careful network design and segmentation, but the results are well worth the effort. Aside from being more secure than a network that supports a large array of general-purpose network protocols, a well-designed and well-partitioned production network usually provides operational performance advantages over a flatter network: each application's data tends to be isolated to fewer network segments.
- Make use of secure protocols
-
The choice of the network protocols used by the application itself should have been made during the design and/or implementation phase of the development process. You also need to take care in selecting the network protocols to be used for operational tasks. For example, if the application is a vital business application in which all data sent and received by the servers is encrypted, choosing to use an unsecure network protocol such as telnet for console access to the application servers would be an egregious error.
|
- Separate data from management
-
One of the best things you can do, from a network perspective, is to completely segregate your production data from your administrative or management network traffic. (Unfortunately, this principle is rarely seen in practice.) There are many advantages to this separation, and heightened security is near the top of the list.[2] While implementing separation of this kind, make sure that no administrative network protocols are permitted on the production data segments.
[2] Another major advantage is performance, because management traffic (e.g., data backups) does not consume production bandwidth.
- Monitor for unauthorized activity
-
In any production computing environment, it makes sense to monitor the network for unauthorized activity. Because you should already be allowing only those protocols essential to your business applications, a good starting point is to monitor external (to your production network segment(s)) network interfaces for any attempts to send unauthorized network protocols in or out. Because these network protocols are (by policy) forbidden, any attempts to use them will likely stand out like the proverbial sore thumb.[3] We discuss the topic of event monitoring in more detail later in this section.
[3] Remain calm. What appears to be an attempt at unauthorized access may simply be the result of a poorly configured computer or a misinformed user.
- Deploy multiple layers of security
-
As we discussed in Chapter 2, conventional wisdom rightly says that you should exercise what's known in security circles as defense in depth. That means you make use of multiple layers of security, requiring an attacker to thwart each one before getting to the core of the application. This approach both adds to the difficulty of the attack and improves the likelihood that the attacker will be detected. The defense in depth strategy is a particularly strong one to use when you're configuring networks. For example, in addition to employing a well-maintained network firewall, consider also enforcing your policies on any and all network devices that have the ability to restrict network protocols (routers, in particular.). Don't worry about the fact that their filtering rule sets may be redundant with your firewall!
- Log network events
-
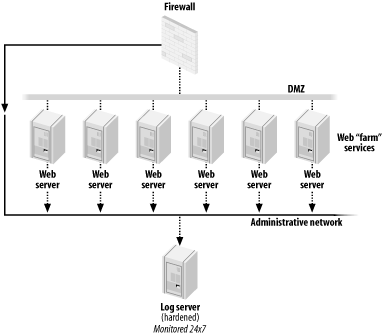
The topic of event logging, as you will see, starts at the network level and proceeds up through the operating system and application levels. In each case, the purpose of logging events as they occur is to provide a degree of accountability. That accountability can be used to monitor for possible unauthorized activity (see the sidebar Event Logging and Figure 5-3), as well as to allow us to perform forensic analyses of the system after unauthorized activity is detected.
Event LoggingIf you want to get the very best information for a forensic analyst to use later, you'll make sure that every single electronic component of a business application logs all of the events that it sees. Quite often, though, that degree of logging is simply not feasible, for a number of different reasons: sometimes the components cannot perform logging and sometimes the act of logging presents an undue performance burden on the components. We suggest logging as much as you can get away with and ensuring that at least some events are being logged at the network layer, at the operating system layer, and at the application layer. That way, you have a good cross-section of logging. Starting here at the network layer, though, study the event logging capabilities of all of your network components?routers, switches, firewalls, etc.?and enable them at an appropriate level. There are three core principles of secure event logging (shown in Figure 5-3):
|
Figure 5-3. Log server network architecture
5.2.2 Secure the Operating System
Once you've addressed the security of the network, it's time to start looking at the security of the operating system on which you're going to place your application. In effect, the network and the operating system make up the foundation on which your application will sit. Without that solid foundation, your application is a sitting duck.
As with the networking principles summarized in the previous section, this list is pretty much motherhood-and-apple-pie and is by no means comprehensive. We invite and encourage you to dig deeper; we include references to additional information resources wherever feasible.
- Start with a secure baseline
-
The initial installation of an operating system is vitally important to its security over its lifecycle. The system needs to be organized, installed, and configured in a businesslike manner so that the operations staff has what amounts to a clean and tidy workplace to do its job. This means doing a baseline installation of the operating system, meticulously going through all of the available security features and capabilities, and optimally configuring each one to meet the needs of your application. Consider using a secure configuration guide and/or checklist while you're doing this.
Another attribute of success during this step is that your process should be repeatable. If you're installing multiple systems, consider an automated process for ensuring that your baseline secure configuration is accurately and consistently replicated across each system. Most modern operating systems either come with this capability or have third-party tools available to facilitate it. Note that a secure baseline configuration such as this is primarily made up of the various operating system configuration settings. Going through this exercise now has the added benefit of easing the standardization of other, more operationally focused settings such as standard logging configurations, etc. We discuss things like the installation of security patches in later items.
- Make good use of file access control
-
Most modern operating systems have a rather rich set of file and directory access control features. These generally include, at a minimum, the ability to set read and write access for every file and directory on the system. Some operating systems support access control lists whereby you can explicitly (or implicitly) specify the users that are authorized to access a particular file or resource. Take the time to study what access control features your operating system provides, and make good use of them. Use them to protect your application, its configuration, and your users' data (if applicable) against unauthorized disclosure or modification.
This is the time to apply the principle of least privilege that we discussed back in Chapter 2. Each file, folder, device, etc., should be configured so that only the users or processes that absolutely need to access it are allowed to access it, and only to the level of access that is absolutely necessary. For example, if a configuration file needs to be readable to the application (and not necessarily to the user), then set it to that and no more.
- Allow essential network services only
-
While configuring the network profile of your operating system, you'll no doubt be faced with the decision of which network services to allow and which to disable. As a rule of thumb, your server should only allow those services that are absolutely necessary to the running and maintenance of the application that will run on the system, and only on the necessary network interface(s). Anything more represents a potential security risk to the system and its application.
To be fair, even essential services likely represent some level of risk, so they need to be chosen carefully by the application designers and need to be watched closely by the operations team. In addition, for those essential services, we suggest augmenting the network security settings by restricting access to the necessary network services on each application server, to only those systems and networks that have a requirement to use them. For example, a database server might have a need for a front-end web server to submit database queries to it. In that case, enable the database network service, but restrict its access to only the front-end server(s). No other computer on any other network should have the ability to submit database queries. Moreover, this policy should be enforced by every network component, as well as by the database server's operating system configuration itself. These all are just additional components of that layered security architecture we've been talking about.
- Remove what is not essential
-
We've addressed disabling all unnecessary network services. Well, let's go one step further?particularly if this application server is going to sit on a network segment that's accessible to a general population (for example, to the Internet itself). If a network component or system tool is not absolutely required, consider removing it entirely from the system, not merely disabling it. For example, does the application server have a need for default-installed operating system games, user management tools, language compilers, and so on? If they are on the system, there's a chance that they could be misused by someone who has found a way to break into the system; do you really want an attacker to have access to a C compiler and an FTP client? Take the opportunity away entirely and remove them. This practice is commonly referred to as hardening a system, or setting it up to be a bastion host.

Hardening is often a slightly dicey process that involves trial-and-error testing in a carefully controlled and documented environment. Reliability and repeatability, in addition to security, should be the principal goals.
- Install all current security patches
-
While we recognize that keeping up with operating system security patches can be a daunting task, it's also the case that no other security operations task is as important to the overall security of your application. The underground community of attackers spends a great deal of time searching for unpatched computers across the entire Internet. Automated network vulnerability scanners make unpatched computers stand out like a lame antelope in a herd. Don't give your adversary this foothold. Establish a reliable, rapid, and priority-based regimen for installing security patches as your product vendors release them.
At the time of this writing, many operating systems are being distributed with the capability of automatically and periodically retrieving and applying security patches. This practice no doubt has significant merit for desktop computer systems (and perhaps even some servers), but do treat it with great caution in production server environments. As we discuss in the later section, Section 5.2.4, you should carefully test any proposed change to a production configuration before applying it to the production systems. Pay careful attention to how important it is to apply a patch in a timely manner; some patches should be installed as soon as possible, while others can safely wait until the next maintenance window in the production environment.
- Log operating system events
-
In the previous section, we talked about the need for event logging at the network level. Almost all modern operating systems also have capabilities for logging system events?many of which are highly relevant to the security of the system. However, it's been our experience in production data center environments that very few of these capabilities are used, and when they are, they're often not implemented securely. Log as many of the system events as you can feasibly log, again sending the event logs to a dedicated log server if possible. If an incident takes place, you'll be thankful that you have good accountability on your systems.
Now that we have given you a rather complex list of ways to batten down the operating system, we are going to complicate matters a little more. You may not think in these terms, but the security of a program or system that does not change can nevertheless decay over time. Here's a thought experiment: shrink-wrap a workstation, power it off, and put it in the closet. Power it up again in six months. It will be demonstrably less secure. It's especially important to remember this when you're trying to evaluate the existence or severity of vulnerabilities; when you're making choices about which secure coding techniques you should be applying; or when you're deciding how often to apply batches of patches.
5.2.3 Deploy the Application With Due Care
The next logical step in this progression up the stack involves setting up the application itself so that it's safe and sound in the operating system environment.
- Make appropriate use of file access control
-
In the previous section, we talked about file access control as it pertains to securing the operating system. Be equally diligent in using whatever file access control tools are at your disposal to protect the application and its associated files. Typically, you'll have to protect the application program itself, configuration files and/or shell scripts used for various administrative tasks, and user data. In setting the file access controls, consider the scenario of the user and of the application administrator or operator. What does the user need to execute, read, or write to in order to run the application? Pay equal attention to the administrator's access (if applicable). In setting the file access controls, give each of those categories of users the level of access that they need?and no more.
- If feasible, install in a compartmentalized environment
-
Some operating systems have features that allow you to run applications in highly compartmentalized operating environments. On Unix systems, for example, you can use the chroot command for this purpose. Other operating systems have other means of doing this, particularly operating systems that provide virtualization of subsystems and multilevel security (MLS) features. Such features enable the application to run in an area where it's isolated from the operating system itself, as well as from any other applications on the host system. The result is that a security compromise of any single component of the system, including the application, should not compromise the security of the host operating system or any other applications. In particular, running network-based applications in an isolated environment is well worth the time and effort it takes to configure one.
- Turn on event logging
-
Be sure to enable all reasonable event logging within the application, just as you did for the network components and the operating system. It's important that the application maintain a level of accountability of events, on top of what the network and the operating system are already tracking. The top reason for logging events at the application level is that application logging can provide you with the highest level of accountability possible. For example, it has often been our experience that network intrusion detection systems and/or firewalls will sound the alarm that a possible intrusion has taken place. But application event logging lets the security analyst determine whether the alarm is an actual intrusion or a false alarm. If you can't determine exactly what took place inside the application under (potential) attack, you may not be able to verify with confidence that the alarm was a false alarm?and that invariably leads to unnecessary time spent chasing the event to closure.
- Apply the same standards to third-party code
-
In addition to taking the time to securely install and configure your application, be sure to hold any third-party code that you are using to the same high standards?if not higher. Closely examine and verify that any third-party code, libraries, etc., are making appropriate use of things, such as file access control mechanisms. Doing so requires a high level of understanding of the third-party software and how it works. While this is not an easy task by any means, you will undoubtedly benefit from this understanding at some point. There will, no doubt, be situations in which you simply don't have access to the source code for a third-party application or library that you must use, so review of the code itself is not always possible.
5.2.4 Ensure Sound Operations Practices
In the preceding sections, we've discussed how to securely set up and configure your operating system and application. Now it's time to ensure that the basic operations practices are sound from a security perspective. In Chapter 6, we'll supplement this discussion by mentioning several international standards for secure operations practices and procedures.
- Manage privileges
-
In just about every business application, there are multiple categories of access required for developers, administrators, operators, and users. Each of these categories of accounts requires different levels of access to the different components of the application. Further, each operating system has different features and capabilities for configuring and managing system privileges and access levels. For example, some operating systems let you define access roles, such as backup operators who need to be able to read system information, application information, and user data for the purpose of backing up the information, but who don't need to modify any of that information. Study the capabilities of your environment, and make the most use of them (as possible and feasible for your application). Role-based access can be especially useful: it enables you to give each person just the level of access that he requires to do his job, and nothing more.
- Conduct operations tasks securely
-
In the course of running a production computer system and its applications, the operations staff is likely to need varying amounts and types of access to the computer itself. Most data centers have their own practices for doing this. In most cases, they have a standardized set of tools and network protocols that they use for their job tasks; that way, the operations staff has a consistent set of interfaces to handle for their day-to-day activities. Any security flaws in these practices can expose your application and its operating system to security risks.
For example, using a network protocol such as telnet (not a secure protocol by any stretch of the imagination) to connect to each computer under the operational control of the data center operations staff runs the risk of exposing the system's administrative username and password to an intruder on the network. In such a case, an isolated security compromise can spread rapidly through the entire data center, thereby putting all of the systems in the center at risk.
- Manage configurations
-
One of the things that the operations staff generally oversees in a data center environment is configuration management of the production systems. Operations people live and die by tasks like this, and we don't presume to know their jobs better than they do. Nevertheless, it's important that the configuration management processes and procedures take into account the security aspects of the configurations under their control, not just the operational readiness and stability of the systems. We've seen far too many production systems that were many months out of date with applying current security patches, for example. Ironically, this appears to us to proportionately worsen as the importance of the application increases, because many operations staff are seemingly wary of installing security patches for fear that they will disrupt business flow. To exacerbate the problem, the operations staff are often unaware of the security patch level of the systems under their control. No doubt they can tell you what version of the operating system and application is running, but security patches often escape unnoticed. It's vital that these operations processes and procedures incorporate security configuration maintenance of the operating system as well as of the application.
- Keep up to date with patches
-
This may appear to be a repeat of the previous principle, but it really isn't. Configuration management pertains to far more than just patch maintenance. However, the issue of patch maintenance is so important that it deserves its own mention. In our years of handling security incidents, we no longer are surprised when we find a site that was broken into as a result of failing to keep one or more critical security patches up to date.
There are many categories of security patches. The most dangerous type of vulnerability is one that enables an attacker to exploit the problem across a network connection and gain administrative access to the target computer system. While it isn't sufficient to only patch these categories of vulnerabilities, they should be treated with the highest possible priority.
Consider again the SYN flood attacks and the patches that were released by the operating system vendors back in 1996. Notifications were broadcast to the world that the TCP design vulnerability existed, and most vendors promptly patched their systems. Sites that didn't promptly install the patches were exposed to potentially major denial of service attacks, combined with a vast armada of eager attackers who had just read the advisories and wanted to see how well the attack tools worked.
Most security advisories explain in detail the nature of the attack; whenever you see one that affects your system and that is exploitable across a network, go to great pains to get that patch installed in your systems as quickly as possible.
- Manage users and accounts
-
Inadequate user and/or account management is a common operational flaw, particularly on dedicated application servers. Many database systems, for example, identify and authenticate their users directly, in such a way that an application user may not even need a system-level login capability on the underlying server. In these cases, it's common for the system and application user accounts to get out of sync, or for one to be more stringently maintained than the other, possibly resulting in a loss of control of the account management process. Further, in many such situations, user accounts?regardless of whether they are at a system level or at an application level?are in no way coordinated with other systems within an enterprise, or even with any central Human Resources database or process. The result is that business applications contain user accounts for people who no longer work for the company or should no longer have access to those particular applications.
We urge you to seek out any central user account management service that your enterprise may provide to reduce the risk we've described. If your enterprise does not have such a service available to internal applications, then it's vital that you at least initiate and maintain operational processes and procedures whereby your user accounts are coordinated on an ongoing basis with the Human Resources organization. While this may seem like unnecessary administrative overhead, it's all part of good sound operational management of an application, and it should be considered vital to its security.
- Treat temporary employees and contract workers appropriately
-
The difficulties of account management are exacerbated in application environments where temporary employees and/or contractors must operate. Unfortunately, many organizations use shared accounts for all temps or for all employees of a particular contractor. The convenience of this kind of practice is not justified by the near-complete lack of accountability that it creates. The fact is that accounts for temporary and contract employees should be treated with caution, and should provide the company with a sufficiently high degree of accountability to allow all of their actions to be tracked properly. The extra effort that this requires will pay for itself a thousand times over if/when a security incident occurs that involves (or even might involve) one of your temps or contractors.
- Test your configurations
-
Test environments and practices are vital parts of a sound configuration management process. The reasons for this are numerous, starting with the fact that it's a good practice to verify configurations (and changes) in an environment that can't possibly adversely impact the business processes supported by the production version of the application. Although this sounds like common sense, we've often been surprised to find production applications that go through no such testing. We've seen environments in which changes to applications are directly applied?sometimes even by the developers themselves?directly onto the production systems. How do you suppose such a site would react if, for example, the SYN flood patch was applied to the production system, only to find out that something in the timing of the new TCP stack session handler caused the application to fail catastrophically?
If you think a test environment is a luxury that can't be afforded for your application, then consider the cost of a configuration change taking the application down for a day or more. If that cost is acceptable, then perhaps you can get by without a formal test environment for your application. Even in this kind of situation, at least consider a virtual test environment using an emulation system such as Vmware that enables you to set up multiple virtual computers on one system. An entire application system, complete with multiple supporting hosts, likely can be set up very quickly and easily in this manner to facilitate quick, easy, and inexpensive testing of the application before you place it into a production environment. However you accomplish it, make sure to incorporate a configuration testing process; it's not a luxury for any but the most trivial and inconsequential of applications.
- Set up checks and balances
-
A practice of checks and balances is another important aspect of creating a sound configuration management system. At the most fundamental level, developers should develop the software; someone else should test the software; and a third should install and operate the tested software. This separation of responsibilities helps ensure that the production environment has the most stable and carefully tested software possible for a given application. In some environments (e.g., in the financial sector), formal checks and balances practices are required by law; in others, they are simply sound practices. As with the configuration testing environments we described in the previous item, the checks and balances do not need to be elaborate or highly formal.
- Conduct tape backups securely
-
Virtually every data center on earth has years of experience performing tape backups for vital business applications and their data. Nevertheless, we've often seen tape backup processes that, while robust from the standpoint of backing up the application or data successfully, expose the business to unnecessary security risks. For example, in one environment that we assessed, a data center performed its nightly tape backups and then placed the backup tapes in a box that was picked up on a daily basis by an off-site backup storage service vendor. On the surface, this would appear to be a well-thought-out process, but it turned out that the box containing the backup tapes was placed in the building's lobby at a particular time every day, and then the vendor picked up the box without having to sign in to the building's access control security. There was nothing stopping anyone who knew how the system worked from walking into the lobby and taking the tapes and all of the data on them at will.
In a situation like this, encrypting the data can help reduce the risk, as can a process of having the vendor identify himself to local security personnel and sign for the tapes daily. Better yet, do both of these things to ensure that your backups are secure and are properly accounted for.
- Keep your incident response plan ready
-
Earlier, we discussed the principle of defense in depth, as well as the principle of protect, detect, and react. In each case, we stressed multiple layers of security planning. Incident response is a crucial part of that overall planning, and it's important that you do an adequate job of it.[4] Further, you should test the incident response plan periodically to ensure that it's adequate and that all personnel are trained and know what needs to be done during an incident.
[4] For a thorough treatment, see Incident Response by Kenneth R. van Wyk and Richard Forno, 2001, O'Reilly and Associates.
We can't bear to leave this topic without explaining a concept that ties together many of the topics we've just covered. Bit rot is our shorthand for the notion that the quality of software will decay over time even if no changes are made to the program itself. It happens all the time: a program that used to work perfectly well suddenly starts misbehaving because the environment around the program has changed. (This could be the behavior of a compiler, perhaps, or the value of an environment variable, or even the amount of disk space available on the system.) Small interactions between the program and its environment, which previously went unnoticed, now suddenly become significant. This phenomenon goes a long way toward explaining the reluctance of systems operations staff to introduce any changes to their production systems?doesn't it?
5.2.5 Other Good Practices
We've addressed a full range of good practices from the network perspective through the application; we've also looked at operational practices. There are a handful of other good practices that we recommend that don't fall into any of these categories:
- Undertake threat and risk analyses
-
The U.S. Government commonly undertakes threat analyses of important application systems prior to deployment, as well as periodically reverifying the threats that the application is likely to face. In this context, threat analysis is the process of examining who is likely to attack a system and how they are likely to attack it. The next logical step in the process is to perform a risk analysis to understand what the business impact could be of an attack.
There are numerous reasons why these steps are advisable for just about any application system you might deploy. First, they help during the design and implementation of the application by guiding the designer on what defenses to put in place to protect the application. Next, they help in periodically validating both changes to the threat level and type, and changes in the business impact to the organization should a security incident take place.
- Maintain currency
-
Every person directly involved in the design, implementation, deployment, or operation of a business application should spend the time to understand and maintain an up-to-date understanding of security technologies, both offensive as well as defensive. This is not to say that everyone needs to be a security expert, but it's highly advisable that everyone maintain a fundamental understanding of security technology. The concept here also extends beyond security technology specifically, of course.
- Conduct periodic independent reviews
-
In the previous section, we recommended a series of checks and balances for operational practices. We also strongly advise you to get independent reviews periodically on the security of a business application. The rationale for doing such independent reviews is quite simply to have another set of eyes looking at the application and its operating environment.
Security reviews or assessments can take many different forms, depending on your needs as well as the capabilities and service offerings of the vendor(s) in question. They can range from a rather simple remote network probing of your application for well-known vulnerabilities?often referred to as a penetration test?all the way up through in-depth reviews of every aspect of the security of the application. Naturally, there are pros and cons to each approach, and your choice will depend on your needs, the value of the business application, and your budget. But, whichever approach you decide on, you should ensure that the process your provider uses is open to you and your staff to observe and learn from.
- Monitor security events
-
We've already discussed the advantages of securely implementing event logging at a network, operating system, and application level. It's equally important, although often overlooked, to ensure that those logs are actually being reviewed on an ongoing basis for security anomalies that may indicate unauthorized access on the system. We've actually seen production business environments that went to great lengths to collect event logging data, yet had no process in place for reviewing the logs for problems. The rationale, most often, was that the logs would be used for their forensic value when and if they were needed. To that we'd argue that the organizations may well not even be aware of unauthorized activity, making the forensic value of the collected logging data moot. You log the event data for good reasons?to attempt to detect unauthorized activity and to analyze what took place when responding to the activity. The questions of how and how often to review the logs should also be considered. The answers to these questions are driven by the value of the business application. For some applications, it's completely justifiable to monitor (or outsource the monitoring) of the event logs around the clock, while for other applications, a daily or weekly review of the logs is sufficient.
In making this decision, think back to the principle of checks and balances we discussed in the previous section. In some environments, the existing operations staff is called on to do the monitoring, while in others, a separate security team does the monitoring. We believe that separating these tasks is the most prudent business choice, but that's not always feasible in all environments. Examine which solution works best for you, but don't take the decision lightly. It's rarely a good idea to let the fox guard the hen house.
- Consider intrusion detection systems
-
Closely related to the monitoring of security events is the topic of intrusion detection systems (IDS). As you might expect, there are many issues to consider in deciding whether an IDS is right for you.[5] One consideration is that most IDS systems, particularly when coupled with enterprise-level event correlation tools, can be effective tools for sifting through the reams of event log data that we discussed earlier. They may actually help reduce the amount of labor needed to do the daily reviews of the event logs.
[5] See Stephen Northcutt's book Network Intrusion Detection (described in Appendix A) for a full discussion.
- Seek independent opinions
-
It's advisable to seek the opinions of independent experts, particularly when you are designing and deploying an application, for many of the same reasons why it's advisable to have independent reviews done periodically on the application and its environment.






