5.4 Case Studies
In trying to select the most appropriate real-world examples to illustrate our recommendations in this chapter, we found no shortage of sad stories of organizations that made important mistakes in deploying their business applications. In fact, our main difficulty was in paring down the examples and deciding which ones would best illustrate our recommendations. It is all too easy to design an otherwise solid application and yet deploy it in an unsecure fashion, thereby wasting all of the time and effort that it took to put together a seemingly secure application.
5.4.1 Case 1: Faulty Telephone Switch
A few years ago, we were asked to review the security of a telephone switch for a client in the financial sector, as one component of a broader security assessment. Our review focused on the Unix-based computer that controlled the switch. The first step was to look at how the system functioned; here's what we found:
The small number of authorized users of the console system, as it was called, sat at their desktop PCs and used a simple telnet application to connect to the phone switch console and do their jobs.
Each user supplied the Unix system with a single shared username (with no password) to log into the system and run the application.
The application itself then prompted each user to provide a unique username and password, thereby performing all user authentication within the application.
Before ever touching any of the client's systems, we could already see some major security flaws: unencrypted network access to a vital business application, shared usernames, application-centric authentication?and we were only getting started with the review! The client claimed that none of these flaws were actually problems; because only the users of this application were allowed to telnet to the console, the shared account on the Unix system was "locked" in a way that only enabled that account to run the phone switch software, nothing more. Moreover, the users had unique authentication once they were in the console software. Oh, really?
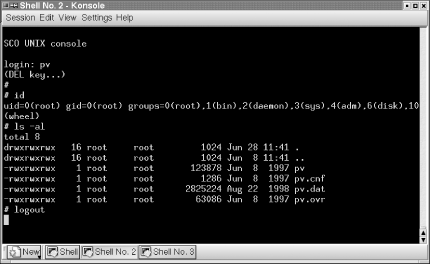
Once we'd acquired the basic information about how the program behaved, we asked to have access to a telnet session into the console system. The login banner displayed by the system revealed that the Unix version was from SCO, a popular commercial variant of Unix for PCs at the time. We entered the shared username, pressed the Enter key, and immediately started pressing the Delete key at the keyboard. The client laughed and told us there was no use trying to break out of the application?they'd already tried that. A second try and a few Delete keystrokes later, and we were rewarded with the "#" prompt, indicating that we now were logged into a general-purpose shell and had root access on the system. (Figure 5-4 shows the result.)
Why did we succeed where others failed? We had noticed during login that the system was SCO Unix, which we knew was derived from (at the time) AT&T's System 5 Unix. Having used System 5 in the distant past, we recalled that the default interrupt keystroke was the Delete key, not the Ctrl-C key pair popular with many other operating systems. The point here is that we knew exactly where this particular system was vulnerable. At the risk of quoting the great Chinese philosopher Sun Tzu one too many times, "Know your adversary like you know yourself and you need not fear the outcome of a thousand battles." Always assume that someone will examine your application with this level of vigor. At this point, our skeptical client started paying closer attention to what was going on.
The next step was to look around the application environment on the Unix system. It turned out that the application was apparently a third-party commercial application that had been installed onto the PC. Further, all of the files in the application account's home directory were configured so that they were readable and writable to any user on the system. Within these files, we noticed one file that contained the usernames and unencrypted passwords of each of the authorized users of the application.
The test ended at this point, at the client's request. By now, the flag had been captured one too many times.
Figure 5-4. Gaining shell access on the SCO Unix system
If ever there were a textbook example of how not to deploy an application, this one was it. Let's examine two key lessons that we can learn from this experience:
It appeared to us that the application itself had been badly ported from a single-user environment?probably MS-DOS?to a multiuser environment. In doing the port, the application developer had failed to learn and take advantage of the resources that the underlying operating system could have provided him. Instead, the installation was fatally flawed in every conceivable way, from the file access controls through the faulty shared account mechanism.
The client (and the person who ported the application to Unix) had only considered the security of the application to be within the application itself. In a matter of moments, we were able to thoroughly compromise the security of the application without ever confronting the security mechanisms?meager as they were?that the application provided. In fact, any security provided by the application was moot because of its egregiously poor operational deployment.
5.4.2 Case 2: Due Diligence Review from Hell
In another case, we were asked to perform a security review of a budding dot-com company on behalf of one of our clients, as part of a due diligence review process. The client was looking to enter into some undisclosed form of business relationship with the company under review, and wanted a reasonable level of assurance that entering the business relationship would not open our client to any major IT security problems.
The company under review politely endured this level of scrutiny, although it clearly wasn't their idea of a good time. This company's business involved providing a network-based application service to its customers. So, we set out to review the security of how this application was deployed.
Our first step was to examine the application itself. The application was run on a series of servers in a data center. The servers received information on a 24x7 basis from external information sources, processed the information, and then formatted the information in a business-like manner for delivery to the company's customers. Simple enough, we thought.
It wasn't until we started to dig a bit deeper into the company's operations practices that we found out how bad things were. The company did its own application development internally, which was just fine and completely expected. However, the development staff had no formal or informal process for configuration and change management. Indeed, they could?and regularly would?simply compile new software and copy it directly from their desktop PCs into the production servers in the data center. What's more, there was no tracking of the changes that were made.
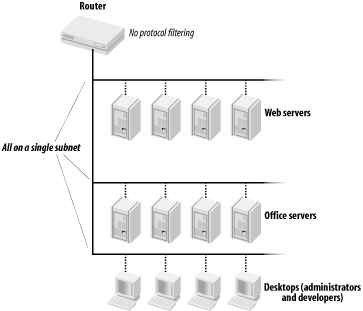
Next, we looked at the network environment. What we found was that the network was hierarchically flat. The developers were logically on the same network segment as the production servers in the data center. Further, the company's administrative systems, from its payroll to its office automation systems and email, were on the same logical network. And on top of this, there were absolutely no network filters or firewalls between the Internet, the production servers, the development PCs, and the administrative computers. (Figure 5-5 illustrates the overall network architecture.)
We quickly demonstrated that the current security provisions were grossly inadequate to the point of probable negligence to the company's shareholders.
Figure 5-5. Network architecture before addition of firewall
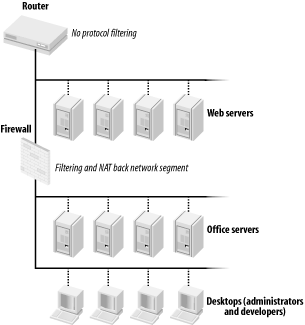
Needless to say, the environment was rapidly rearchitected and numerous security measures were deployed. (Figure 5-6 shows the new network architecture.) Most of these measures caused the company great consternation. But that's a story for another time.
Figure 5-6. Network architecture after addition of firewall
This case study teaches several lessons; the following are especially important:
The company had no discernible configuration management or software development discipline. This created, among other things, a complete lack of accountability of the production software. The fact that the software ran at all was amazing; the chances of its being secure, in any sense of the word, were zilch.[6]
[6] By the way, it seemed to us that the root cause of this whole mess might have been the dot-com gold rush clouding the collective judgment of the company's senior management. We doubt very much that the company's shareholders had even an inkling of what was under the hood.
There was no network compartmentalization between the production, development, and administrative portions of the company. As a result, any security compromise of the network could result in a complete compromise of the company's IT infrastructure. Because the company was thoroughly dependent on that infrastructure, the business impact of a security compromise likely would have been catastrophic to the company and its shareholders.
5.4.3 Case 3: Code Red Worm
The final case study for this chapter involves a company that had done a pretty good job of preparing its production e-commerce servers for certain types of attacks but had unfortunately neglected a couple of seemingly minor details.
Code Red was a worm that struck computers around the Internet in the summer of 2001. It worked by exploiting an implementation flaw?a buffer overflow?in Microsoft's IIS web server to propagate from machine to machine. The flaw had actually been discovered, and a patch made available from Microsoft, months before the worm's release. Nonetheless, in an all too familiar way, many companies were caught unprepared. As a result, the worm compromised innumerable IIS-based web servers. Plenty of major corporations spent a significant amount of time cleaning up their networks in the days following the worm's release.
This particular company had done many things right. It had patched all of the production servers to repair the vulnerability that the Code Red worm exploited. All of the firewalls and intrusion detection systems were verified to be up to date. What went wrong? There were several computers connected to the production network segment and used by the application development team. Because these were not production computers per se, they were considered to be outside the configuration management responsibilities of the data center operations staff. You can probably guess all too well what took place when the Code Red worm started attacking the Internet. It did indeed succeed at worming its way into this company's production network.
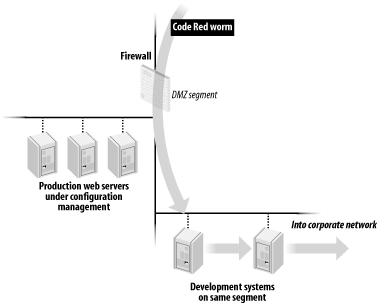
Although Code Red was not successful at breaking into any of the production computers, it didn't seem to care that the development systems were second-class citizens of sorts. It rapidly infected those systems and, from there, quickly found a passage into the company's internal network systems (see Figure 5-7), which were far less prepared for the attacks.
Figure 5-7. Effect of Code Red worm on company systems
For the company, the next 48 or so hours were the incident response team's worst nightmare. Massive business interruptions took place across the entire corporation's data networking environment. The response team was responding to fires far more slowly than new ones were igniting. Eventually, they did get things under control, but by then, catastrophic damage had been done.
This case study teaches several lessons. The following are especially important:
The business unit that ran the production e-commerce systems was principally concerned with the security of its application. It went so far as to ensure and verify that it was prepared, but unfortunately failed to see that the development systems connected to its production data network were, in essence, part of the application system?at least by association. The lesson here is that a network is truly only as secure as its weakest member. Malicious software makes no distinction between a production system and a development system.
The Code Red worm found its way onto many internal corporate networks, not only the externally connected DMZ hosts. The firewalling and filtering between the external and internal networks were clearly insufficient. The lesson here is that when you set up corporate network firewalls, you need to carefully and thoroughly scrutinize all complex data paths. Why was a web server on a DMZ segment permitted to establish an HTTP (TCP/80) socket to an internal system, and at so many sites?






