2.1 Basic Networking
A computer network is essentially nothing more than the notion of two or more independent computers "connected" to each other in some fashion. This, liberally applied, can be used to describe two fax machines, two digital phones, a few personal computers (and perhaps a TiVo), or, more generally, a local area network, a wide area network, or even the Internet itself.
There's a tremendous amount of physical infrastructure behind establishing these connections. Most of us are familiar with both physical and wireless networks (in particular, the 10/100/1000Base-T physical and various 802.11 wireless technologies). Consider the wireless router connected to the switch, connected to the DSL modem, connected to the service provider's network, and then the various connections that lead to (for example) the local Amazon.com server. It's hard to say which is more amazing?that a packet ever gets to the destination or that a response finds its way back.
Just sorting out the basic components of a network can be a very conceptually difficult area, so let's turn to the time honored standby, the International Standard Organization's Open System Interconnect (OSI) model (see Table 2-1). Perhaps one of the best diagrams for discussing networking fundamentals, the OSI reference model is a conceptual, seven-tiered "stack" showing the relationship between the different components of a network.
|
Layer |
Example(s) |
|---|---|
|
Physical layer |
RJ-45 connectors, CAT5 |
|
Data Link layer |
Ethernet (IEEE 802.2) |
|
Network layer |
IP, IPX |
|
Transport layer |
TCP, UDP |
|
Session layer |
Socket connections |
|
Presentation layer |
Byte ordering |
|
Application layer |
HTTP, FTP, SMTP, POP3, IMAP, etc. |
The OSI model is regarded as a theoretical tool, not a practical system for working with (or building) a network, but it's worth noting for purposes of understanding the complexity of the underlying system. It's beyond the scope of this text to cover this model in detail, but when working with web services, it's more or less assumed that all the layers beneath the application layer "just work." When things go wrong, it can be useful to walk through the model to understand exactly where things are going awry.
|

Note that the application layer as described by the OSI isn't the same thing as an application. Applications, be they servers or desktop clients, generally rely on the underlying application layer (sometimes referred to as a protocol) for the actual communication.
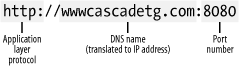
A uniform resource identifier (URI), as shown in Figure 2-1, contains the minimum information an application needs to access information on the Internet. The port is often assumed for certain protocols (e.g., port 80 is the default for HTTP). Given a URI, most system libraries allow for access to network resources as input and output streams of bytes.
Figure 2-1. Uniform resource identifier
Libraries sometimes provide application developers with a more friendly view of data transmitted over a network. For example, the Java servlet APIs provide programmatic access to HTTP requests, abstracting away the lower level details of the data transfer. These libraries allow a developer to avoid writing custom code for every network connection, instead focusing on the portion of the network transfer relevant to the application.
2.1.1 Streams of Bytes
Using the Apache Axis TCPMonitor application, we can monitor the raw bytes exchanged when the O'Reilly web site is accessed by a web browser (see Figure 2-2). The top pane shows the various connection data, the middle pane shows the data sent to the O'Reilly web server, and the bottom pane shows the data returned (you can see the various HTTP headers and the start of the actual HTML). For more information on the Apache Axis TCPMonitor application, see http://ws.apache.org/axis/java/user-guide.html.
Figure 2-2. Raw bytes from accessing oreilly.com
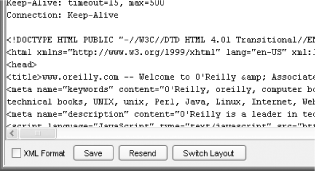
In the remainder of this book, we'll focus on the application layer and code built on it. Instead of accessing raw bytes, we'll use libraries that digest these network streams and provide additional services.
Viewing the textual structure seen in the sent and returned bytes shown in Figure 2-2, it's easy to imagine building your own server or client to send and receive this sort of data. By establishing common protocols for communication, it's possible to decouple the server and client applications, allowing for incremental replacement of either the server or the client over time. Using HTTP as an example, it's possible to upgrade your browser without upgrading every server on the Internet (and vice versa). This separation is a critical aspect of web services.
Sometimes, standards for interaction become confusing as protocols and systems are chained together. For example, SOAP, formerly known as Simple Object Access Protocol,[1] relies on HTTP, the Hypertext Transfer Protocol, to exchange data. Alternatively, SOAP can send data via SMTP, the Simple Mail Transport Protocol. It's easy to see how the already complex OSI reference model can begin to feel a bit simplistic when a SOAP service is layered on top of HTTP, which might then in turn be layered on top of SSL for encryption.
[1] SOAP is officially no longer an acronym for anything.
A Multitude of StandardsThe various different standards, while potentially helpful for developers, also can lead to confusion. For example, visiting the http://www.xml.com/ web site, you see the following topics listed as "Essentials":
Admittedly, many of these are germane primarily to XML manipulation, not web services per se, but this is representative of the profusion of XML/web service "standards" and specifications. There are literally dozens of competing documents purporting to be standards for a variety of web service related topics, including security, business processes, and many more. Most of these standards are designed to allow for libraries and tools that help developers to avoid "getting dirty" by messing around with the underlying byte streams, or to avoid vendor lock-in. The challenge is to determine which standards are relevant for a given situation. |
The complexities of the network are typically reduced for the application programmer into streams of bytes. Unfortunately, a stream of bytes delivered over the network isn't predictable or reliable, and so any networked application must still deal with network vagaries.
2.1.2 Network Vagaries
At the core, network vagaries boil down to three main points:
Latency, or the delay until the first bit arrives
Bandwidth, or the total bits sent over a period of time
Reliability, or the notion that bits sent are bits received
As you can see in Table 2-2, different physical connections have different characteristics. For example, a burned and priority-mailed DVD, while featuring terrible latency, is a comparatively high-bandwidth solution. The same is true for protocols: if you compare HTTP and SMTP (two of the underlying transports possible for SOAP), SMTP offers superior reliability but greater latency than HTTP.
|
Latency |
Bandwidth |
Reliability | |
|---|---|---|---|
|
Dial-up |
Poor |
Poor |
Moderate |
|
DSL/cable |
Good |
Good |
Good |
|
Cell phone PDA |
Poor |
Poor |
Poor |
|
802.11x laptop |
Good |
Moderate |
Moderate |
|
Colocated server |
Excellent |
Excellent |
Excellent |
|
Handwritten letter |
Poor |
Poor |
Excellent |
|
A file copied to a floppy |
Poor |
Poor |
Excellent |
|
A burned and priority-mailed DVD |
Terrible |
Excellent |
Excellent |
As developers, we tend to make assumptions about networks that simply aren't correct?for instance, about the nature of the client's needs or capabilities or that the network is even available at all (a form of reliability). The following quote is from "The Eight Fallacies of Distributed Computing," by Peter Deutsch, which can be found at http://today.java.net/jag/Fallacies.html:
Essentially everyone, when they first build a distributed application, makes the following eight assumptions. All prove to be false in the long run and all cause big trouble and painful learning experiences.
- The network is reliable
- Latency is zero
- Bandwidth is infinite
- The network is secure
- Topology doesn't change
- There is one administrator
- Transport cost is zero
- The network is homogeneous
This book assumes that you understand how your underlying network works (and how to secure your network using, for example, firewalls). If you wish to provide web services, you may need to punch a hole through your firewall or set up port forwarding to ensure that the IP address exposed to the Internet is forwarded to the particular machine on the local network providing the service.
If your application is going to principally use HTTP-based web services, you probably don't need to worry about the network configuration (assuming you can successfully browse the Internet). Many web services are assigned the standard HTTP port (80), but some services use alternate ports (e.g., 8080). If you have trouble connecting to a web service, you should check to make sure that the port is not blocked by a firewall.
Throughout this book, we'll assume a simple network, running on a 192.168.1.x subnet. The network is connected to the to the Internet by a port-forwarded firewall/router connected to a DSL line. This is likely simpler than the production network you'll be using, but it will work for our purposes.






