7.1 Making Feeds Available
Before a user can subscribe to a feed, she needs some mechanism to know the feed is available. The most obvious mechanism for this is posting the feed's URL on a web page. Let's start by looking at the web page that lists the feeds. You can see these three feeds (a XML icon next to the text View RSS is a typical user interface element for indicating an RSS feed) in Figure 7-1.
Figure 7-1. Available feeds
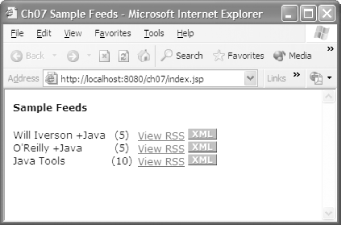
Clicking on the link for the O'Reilly +Java feed shows the feed being generated for a Google search for the term, O'Reilly +Java, as shown in Figure 7-2.
Figure 7-2. O'Reilly +Java RSS feed

Notice that the feed includes HTML tags embedded in the description and titles. The RSS specification is a bit ambiguous about embedded HTML, and it's easy to think of reasons why embedded HTML can be both a good and a bad thing. Unfortunately, there is absolutely no standardization of how HTML in feeds should be treated?which can potentially confuse XML parsers?and parsing HTML by hand is a tedious, error-prone operation. In this particular instance, the feeds are by definition coming from Google, and Google emits fairly consistent data, so the application passes the limited formatting (principally boldfacing certain terms) along to the user.
Let's look at the JSP page that generates these RSS files in Example 7-1.
Example 7-1. RSS JSP
<%@
page contentType="text/xml;charset=utf-8" language="java" %><%@
page import="com.cascadetg.ch07.FeedGenerator" %><%
response.setContentType("text/xml");
FeedGenerator myFeed = new FeedGenerator( );
String term = request.getParameter("term");
int size = 5;
if(request.getParameter("size") != null)
size = Integer.parseInt(request.getParameter("size"));
%><%= myFeed.getChannel(term, FeedGenerator.RSS_091, size) %>7.1.1 Examining RSS Feed Generation
As you look over Example 7-1, you can see that a bit of care is taken to avoid producing spurious return characters in the generated text: the %> and <% delimiters are placed directly next to each other. Also notice that the JSP page looks for two parameters: the search term (term) and the number of items (size) to return. After interpreting the incoming parameters, it is passed to a FeedGenerator object (notice that the default is RSS 0.91, not the latest 2.0 specification).
Our Java code relies on a third-party library, called Informa, to both parse and generate RSS files. You can download Informa from http://informa.sourceforge.net/. To install, simply place the informa.jar library in the CLASSPATH.
An overview of the FeedGenerator class can be found in Figure 7-3.
Figure 7-3. FeedGenerator class diagram
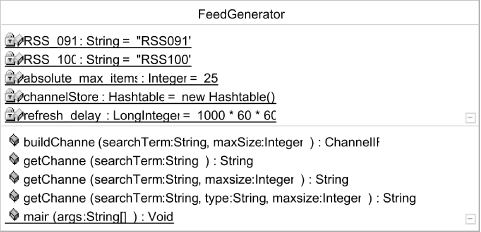
The code for the FeedGenerator class in Example 7-2 uses the Google web service code (as initially described in Chapter 4) to retrieve the results and generate a RSS feed using the Informa library. Depending on the needs of the application, one of three FeedGenerator.getChannel() methods can be used by client code to retrieve data. A java.util.Hashtable( ) caches data from Google, which ensures that the Google server isn't hit too often.
|

Example 7-2. RSS feed generation
package com.cascadetg.ch07;
import java.io.StringWriter;
import java.net.URL;
import java.util.Date;
import java.util.Hashtable;
import de.nava.informa.core.ChannelExporterIF;
import de.nava.informa.core.ChannelIF;
import de.nava.informa.exporters.RSS_1_0_Exporter;
import de.nava.informa.exporters.RSS_0_91_Exporter;
import de.nava.informa.impl.basic.ChannelBuilder;
// We'll be relying on the same straight-forward library as provided
// by Google and described in Chapter 4.
import com.google.soap.search.*;
// We'll be using the same tokens as described in Chapter 4 for
// authorizing the Google search
import com.cascadetg.ch04.DeveloperTokens;
public class FeedGenerator
{
/**
* We'll be using this as a repository of already retrived data
* from Google to avoid hitting the Google server too frequently.
*/
static Hashtable channelStore = new Hashtable( );
/**
* This is the refresh delay between checking for new data. Note
* that this is the most often we will be checking - if a user
* doesn't request the page after an hour, we aren't going to be
* out looking for the data.
*/
static long refresh_delay = 1000 * 60 * 60; // 1 hour
/** Absolute maximum number of items we'll return to avoid abuse. */
static int absolute_max_items = 25;
/**
* This is the main method for retrieving the data from Google and
* building it as an Informa RSS object.
*
* @param searchTerm
* is the String sent to Google as a query
* @param maxSize
* is the maximum number of items to return
*/
public ChannelIF buildChannel(String searchTerm, int maxSize)
{
ChannelIF final_channel = null;
// First, we need to make sure that the channel requested is
// not already in the channelStore cache. If it is in the
// cache, we will check to see how old it is. If it's older
// than the default refresh, we'll want to get it again
// anyways.
if (channelStore.get(searchTerm + "|" + maxSize) != null)
{
final_channel =
(ChannelIF)channelStore.get(searchTerm + "|" + maxSize);
if (final_channel.getLastUpdated( ).getTime( )
+ refresh_delay
> new Date( ).getTime( ))
{
return final_channel;
}
}
try
{
ChannelIF channel = null;
ChannelBuilder myBuilder = new ChannelBuilder( );
channel =
myBuilder.createChannel(
"Google Search '" + searchTerm + "'");
channel.setDescription(
"Popular Google results for " + searchTerm);
channel.setCreator("Google Watcher");
// Here, we set up the Google search.
GoogleSearch search = new GoogleSearch( );
// Set mandatory attributes
search.setKey(DeveloperTokens.googleKey);
search.setQueryString(searchTerm);
// Set optional attributes
search.setSafeSearch(true);
// Invoke the actual search. Note that this can be a
// potentially "expensive" call, as it can easily take 1-3
// seconds.
GoogleSearchResult result = search.doSearch( );
// Here, we take the search results and loop through,
// adding them as items to the Informa API. Note that we
// make checks to make sure that we aren't adding too
// many items.
if (result != null)
{
GoogleSearchResultElement[] mySearchElements =
result.getResultElements( );
for (int i = 0; i < mySearchElements.length; i++)
{
if (i > absolute_max_items - 1)
break;
if (i > maxSize - 1)
break;
myBuilder.createItem(
channel,
mySearchElements[i].getTitle( ),
mySearchElements[i].getSnippet( ),
new URL(mySearchElements[i].getURL( )));
}
}
// Finally, we set the timestamp for this channel and add
// it to the cache.
channel.setLastUpdated(new Date( ));
channelStore.put(searchTerm + "|" + maxSize, channel);
// Ok, everything looks good, so let's go ahead and return
// the channel.
return channel;
} catch (Exception e)
{
e.printStackTrace( );
}
// If channel is still null, odds are good that there was a
// failure loading some how. This might be as mundane as a
// network failure between the JSP server and Google, in which
// case there's no reason not to return the cached result if
// available as a backup.
// Worst case, we still leave channel set to null.
if (final_channel == null)
{
final_channel =
(ChannelIF)channelStore.get(searchTerm + "|" + maxSize);
}
return final_channel;
}The code in Example 7-3 shows additional methods, principally designed to ease the integration of the code in Example 7-2 into the application's JSP layer, and also a simple command-line implementation (useful when testing the application).
Example 7-3. RSS feed generation, Part II
/**
* A static constant we use to indicate that an RSS 1.0 feed is
* requested.
*/
public static final String RSS_100 = "RSS100";
/**
* A static constant we use to indicate that an RSS 0.91 feed is
* requested.
*/
public static final String RSS_091 = "RSS091";
/**
* A default invocation of a search, with RSS 1.0 and five results
* returned
*/
public String getChannel(String searchTerm)
{
return getChannel(searchTerm, RSS_100, 5);
}
/** A default invocation, with RSS 1.0 returned */
public String getChannel(String searchTerm, int maxsize)
{
return getChannel(searchTerm, RSS_100, maxsize);
}
/**
* A configurable request for channel as an XML document in the
* form of a String. If you wished to do additional formatting, you
* may (for example) want to parse and load this using JDOM or
* another XML technology.
*
* For best performance and ease of use in a JSP application, you'd
* be better off using the Informa API directly.
*/
public String getChannel(
String searchTerm,
String type,
int maxsize)
{
// We don't want to write the results to a file on disk - we
// just want to keep the results in-memory.
StringWriter myStringWriter = new StringWriter( );
try
{
ChannelExporterIF myExporter = null;
// Here, we set up a different exporter depending on the
// requested RSS version.
if (type.equals(RSS_091))
{
myExporter =
new RSS_0_91_Exporter(myStringWriter, "UTF-8");
} else
{
myExporter =
new RSS_1_0_Exporter(myStringWriter, "UTF-8");
}
// Here, we go off to our earlier method and actually do
// the 'heavy lifting' to build the channel.
ChannelIF myChannel = buildChannel(searchTerm, maxsize);
// Now, just write the results into the StringWriter.
myExporter.write(myChannel);
} catch (Exception e)
{
e.printStackTrace( );
}
return myStringWriter.toString( );
}
/**
* A command-line diagnostic, lets you retrieve a set of results
* and reports some simple timing data.
*/
public static void main(String[] args)
{
FeedGenerator myFeed = new FeedGenerator( );
long last_time = new Date( ).getTime( );
long timing = new Date( ).getTime( ) - last_time;
String term = "Mac OS X for Java Geeks";
System.out.println(myFeed.getChannel(term));
timing = new Date( ).getTime( ) - last_time;
System.out.print(timing + " ");
System.out.println(term);
last_time = new Date( ).getTime( );
System.out.println(myFeed.getChannel(term));
timing = new Date( ).getTime( ) - last_time;
System.out.print(timing + " ");
System.out.println(term);
last_time = new Date( ).getTime( );
System.out.println(myFeed.getChannel(term));
timing = new Date( ).getTime( ) - last_time;
System.out.print(timing + " ");
System.out.println(term);
last_time = new Date( ).getTime( );
term = "Google innovations";
System.out.println(myFeed.getChannel(term));
timing = new Date( ).getTime( ) - last_time;
System.out.print(timing + " ");
System.out.println(term);
last_time = new Date( ).getTime( );
System.out.println(myFeed.getChannel(term));
timing = new Date( ).getTime( ) - last_time;
System.out.print(timing + " ");
System.out.println(term);
last_time = new Date( ).getTime( );
}
}





