17.3 Advanced Regular Expression Syntax
As you delve more deeply into using regular expressions, and especially if you work with multilingual data, there are some advanced aspects to regular expressions that you'll find helpful.
17.3.1 Using Backreferences
You've already learned about subexpressions. A backreference is a way that you can reference the value of text matching a preceding subexpression. Think about the problem of searching specifically for 10-digit phone numbers that are inconsistent in their use of separator characters:
906.387-5359 989 313-5351
Each of these numbers uses a separator between the first two digit groups that differs from that used between the second two digit groups. What sort of expression would you write to detect this sort of mismatch? One with backreferences.
The key issue in the mismatched separator example we've just described is that to solve the problem, to identify phone-numbers with mismatched separators, you need the ability within an expression to refer to characters matched by earlier parts of that expression. In this case, you need the ability to refer to the first separator from the position of the second. Backreferences let you do this.
The following regular expression includes parentheses around the first bracket expression, which corresponds to the first separator. The parentheses define a subexpression:
[0-9]{3}([-. ])[0-9]{3}\1[0-9]{4}The subexpression ([-. ]) is the first subexpression, so you refer to it using the notation \1. Later in the expression, where you would otherwise expect to see a second occurrence of the bracket expression [-. ], you see \1, which references the value matched by the first subexpression.
The words matched by are critical here. The backreference \1 is not equivalent to [-. ]. Rather, the backreference is equivalent to that part of the text that is matched by [-. ]. If the first separator is a hyphen, then \1 will be equivalent to a hyphen. A specific value for \1 won't be known until you execute a regular expression query, and even then it will change from row to row, as the regular expression is applied to one phone number after another.
The following query uses REGEXP_SUBSTR to extract the first phone number from the free-text, comment column. Only 10-digit phone numbers without parentheses around area codes are considered. That first phone number is then tested using NOT REGEXP_LIKE, to see whether both separators are the same.
SELECT emp_id, text
FROM employee_comment
WHERE NOT REGEXP_LIKE(
REGEXP_SUBSTR(text, '[0-9]{3}[-. ][0-9]{3}[-. ][0-9]{4}'),
'[0-9]{3}([-. ])[0-9]{3}\1[0-9]{4}');
EMP_ID TEXT
---------- --------------------------------------------
7369 126 Varnum, Edmore MI 48829, 989 313-5351
7844 989-387.5359If the separators in a given phone number differ, then REGEXP_LIKE returns FALSE, causing NOT REGEXP_LIKE to return TRUE, with the result that the row containing the phone number is included in the result set.
|

Oracle allows you up to nine backreferences, numbered \1 through \9. These refer to the first up-to-nine subexpressions, counting from left to right.
Backreferences are particularly important in performing regular expression search-and-replace operations. In fact, most of our own backreference usage falls into this category.
Remember all those phone number searches from our earlier examples in this chapter? Remember how creative our users were when it came to formatting phone numbers? Imagine for a moment that you want to unify the phone number format across all those free-form text entries. You want all phone numbers to be in the form 999-9999, with a hyphen separating digit groups. If there's an area code, you want that in parentheses, in the form (999) 999-9999. This is a hard problem, or it would be, if you had to write PL/SQL to solve it. Using regular expressions, it's not such a hard problem at all. You can solve it with one UPDATE statement using a nested call to Oracle's REGEXP_REPLACE function.
Begin by resurrecting the seven-digit portion of the phone number expression from Section 17.1.5:
[0-9]{3}[-. ][0-9]{4}Enclose the pattern for each digit group within parentheses, making two subexpressions:
([0-9]{3})[-. ]([0-9]{4})You can now reference the first three digits as \1, and the last four digits as \2. What's more, you can use these two backreferences in the replacement text that you provide to REGEXP_REPLACE:
SELECT emp_id, REGEXP_REPLACE(
text, '([0-9]{3})[-. ]([0-9]{4})', '\1-\2') text
FROM employee_comment;
EMP_ID TEXT
---------- ------------------------------------------
7369 126 Varnum, Edmore MI 48829, 989 313-5351
7499 90 McConnell Court
Cedar Lake MI 48812
Home: 989-387-4321
Cell: (237) 438-3333
. . .The REGEXP_REPLACE function call in this statement finds each occurrence of the pattern matched by the second parameter, and replaces it with text from the third parameter. The backreferences are what make this operation truly exciting. Using backreferences, you can reference the text to be replaced from your replacement string, giving you great power to move and reformat text.
You're not done though. Now it's time to worry about that area code. Following is the area code pattern developed earlier in this chapter:
([0-9]{3}[-. ]|\([0-9]{3}\) )?All the seven-digit phone numbers, whether following an area code or not, should fit the following pattern, which allows only a hyphen as a separator:
[0-9]{3}-[0-9]{4}Put the two patterns together, and you have:
([0-9]{3}[-. ]|\([0-9]{3}\) )?[0-9]{3}-[0-9]{4}For this particular replacement, you want to leave seven-digit phone numbers alone, because you've already fixed those. To this end, remove the ? to make the area code required:
([0-9]{3}[-. ]|\([0-9]{3}\) )[0-9]{3}-[0-9]{4}Your next step is to put parentheses around each element of the phone number that you care about. There already are parentheses around the area code, but that subexpression also encompasses whatever separator character follows the area code. The following expression factors the separator out of the area code subexpression:
([0-9]{3}|\([0-9]{3}\))[-. ][0-9]{3}-[0-9]{4}The semantics of this expression differ slightly from the previous. When the area code is enclosed in parentheses, this expression allows not only a space to follow, but also a period or a hyphen. We could work around this by approaching parenthetically enclosed area codes as a completely separate problem, to be solved using a separate UPDATE statement, but we've chosen to be flexible and loosen up our pattern just a bit to make our work easier. Sometimes you need to do that.
Next, put parentheses around the elements in the pattern that you wish to manipulate. The seven-digit phone number is ok as it is, so you can enclose that entire portion of the pattern, making it one subexpression:
([0-9]{3}|\([0-9]{3}\))[-. ]([0-9]{3}-[0-9]{4})Dealing with the area code gets a bit tricky, and you'll see why in a moment. For now, look at the expression so far, and realize that \1 refers to the area code, and \2 to the remainder of the phone number. Following is a new SQL query that feeds the results of the earlier REGEXP_REPLACE function, the one to fix seven-digit numbers, into a second REGEXP_REPLACE call, this time to correctly format area codes:
SELECT emp_id,
REGEXP_REPLACE(
REGEXP_REPLACE(
text, '([0-9]{3})[-. ]([0-9]{4})', '\1-\2'),
'([0-9]{3}|\([0-9]{3}\))[-. ]([0-9]{3}-[0-9]{4})',
'(\1) \2') text
FROM employee_comment;
EMP_ID TEXT
---------- -----------------------------------------------
7369 126 Varnum, Edmore MI 48829, (989) 313-5351
7499 90 McConnell Court
Cedar Lake MI 48812
Home: (989) 387-4321
Cell: ((237)) 438-3333
. . .
Finding an Anti-PatternSometimes you need to find occurrences of text that match one pattern but not another. The problem of finding phone numbers with mismatched separators is an example of this requirement: first you need to find a phone number, and then you need to test it, to see whether it's properly formatted. Earlier, we showed a query that tested only the first phone number found in a comment. The following query illustrates a technique you can use to test all phone numbers in a comment: SELECT emp_id, text
FROM employee_comment
WHERE REGEXP_LIKE(text,
'[0-9]{3}[-. ][0-9]{3}[-. ][0-9]{4}')
AND REGEXP_LIKE(
REGEXP_REPLACE(text,
'[0-9]{3}([-. ])[0-9]{3}\1[0-9]{4}','***'),
'[0-9]{3}[-. ][0-9]{3}[-. ][0-9]{4}');The first REGEXP_LIKE identifies comments containing at least one occurrence of our phone number pattern, without regard to whether the separators match. The nested invocation of REGEXP_REPLACE then replaces all good phone numbers, those with matching separators, with a string of three asterisks. Any remaining phone number patterns found by the enclosing REGEXP_LIKE must, therefore, represent phone numbers with mismatched separators. In this way, you can find phone numbers with mismatched separators regardless of whether they come first in their respective comment field. For more on this technique, which you can extend to similar problems, read Jonathan Gennick's article "Regular Expression Anti-Patterns" at http://gennick.com/antiregex.htm. |
We realize this query is becoming difficult to follow. Please stick with us, and study this query until you understand it. Notice the output, in particular the cell-phone number, which now reads ((237)) 438-3333. Oops! Doubled parentheses are not at all what you wanted to see around an area code. What happened?
The reason you see doubled parentheses is because of what \1 refers to. If you carefully study the regular expression feeding into the outermost call to REGEXP_REPLACE, you'll see that the first subexpression includes any parentheses that may already be around an area code. The replacement text rebuilds the area code by using (\1) to enclose it within parentheses. Take an area code already within parentheses, enclose it again, and you end up with results such as ((237)).
We fell into the pit we've just described while writing this chapter. We're telling you the story now for a couple reasons. One, you wouldn't otherwise easily understand why we went with the solution we're about to show you. Two, we want you to know that the thought-process to a successful regular expression is rarely a straight line from problem to solution. You'll often go down a path only to encounter a problem, forcing you to backtrack a bit and try again. Indeed, we backtracked and changed course at least three times while developing this example. Don't be dissuaded if your first attempt at a regular expression solution doesn't quite have the effect you're after. Expect to do a certain amount of experimenting and testing whenever you write anything but the simplest of expressions.
The following expression is the key to resolving the doubled parentheses problem:
(([0-9]{3})|\(([0-9]{3})\))[-. ]([0-9]{3}-[0-9]{4})In this expression, we've made each of the two alternate area code possibilities into its own subexpression. Both those subexpressions are nested within a larger subexpression. Subexpressions are numbered, from left to right, beginning at \1, based on the order in which each opening parenthesis is encountered. In this expression, \1 will be the area code inclusive of any parentheses that might be present. \2 corresponds to the area code without parentheses, if one is found. Otherwise, \2 will be NULL. Likewise, \3 corresponds to an area code enclosed within parentheses, but does not include those parentheses. The following query uses (\2\3) to generate the area code in the correct format. It may seem odd to use both backreferences, but the technique works in this case, because one will always be NULL.
SELECT emp_id,
REGEXP_REPLACE(
REGEXP_REPLACE(
text, '([0-9]{3})[-. ]([0-9]{4})', '\1-\2'),
'(([0-9]{3})|\(([0-9]{3})\))[-. ]([0-9]{3}-[0-9]{4})',
'(\2\3) \4') text
FROM employee_comment;
EMP_ID TEXT
---------- ---------------------------------------------
7369 126 Varnum, Edmore MI 48829, (989) 313-5351
7499 90 McConnell Court
Cedar Lake MI 48812
Home: (989) 387-4321
Cell: (237) 438-3333
. . .Now that all the kinks have been worked out of the expression, it's a relatively simple matter to use it in an UPDATE statement:
UPDATE employee_comment
SET text =
REGEXP_REPLACE(
REGEXP_REPLACE(
text, '([0-9]{3})[-. ]([0-9]{4})', '\1-\2'),
'(([0-9]{3})|\(([0-9]{3})\))[-. ]([0-9]{3}-[0-9]{4})',
'(\2\3) \4');And there you have it. With one statement, and a little bit of regular expression magic, you can consistently format all those randomly formatted phone numbers in a free-format comment column.
|
Coming from Perl?If you come to Oracle with experience writing regular expressions in Perl, we want to warn you that you won't necessarily be able to take a Perl regular expression and drop it into Oracle. There are many differences in how the two platforms support regular expressions. Perl handles string literals differently than Oracle. Perl permits \x for embedding arbitrary byte codes into a string, supports character sequences such as \n for newline, and provides for the use of the $ to dereference variables from within a string. Regular expressions that depend on Perl's syntax for string literals won't translate directly to Oracle. Perl also supports a great deal of Perl-specific regular expression syntax. You have lazy-quantifiers, for example, enabling non-greedy, regular expressions. Conversely, Perl does not support some of the Portable Operating System Interface (POSIX) syntax, such as the [= =] notation used to specify equivalence classes. For a fuller discussion of these issues, including recommendations on Oracle equivalents to Perl-specific syntax, refer to the section "Differences Between Perl and Oracle" in Jonathan Gennick and Peter Linsley's Oracle Regular Expressions Pocket Reference (O'Reilly). |
17.3.2 Using Named Character Classes
Earlier, in our phone number examples, we used bracket expressions such as [0123456789] and [0-9] to create matching sets to match any of the digits, zero through nine. Oracle also supports named, character classes, which provide you with a handy and reliable way to create commonly used matching sets. For example, you can use [:digit:] within a bracket expression to represent the set of all digits. Instead of using [0-9] in the following expression:
([0-9]{3}[-. ]|\([0-9]{3}\) )?[0-9]{3}[-. ][0-9]{4}You can use [[:digit:]] to match any character defined as a digit:
([[:digit:]]{3}[-. ]|\([ [:digit:]]{3}\) )?[ [:digit:]]{3}[-. ][ [:digit:]]{4}Table 17-3 gives a list of valid, character class names, which you must always enclose within a bracket expression. You can include other characters within the same bracket expression. For example, you can write [[:digit:]A-F] to create a matching set of all digits plus the letters A-F.
|
Class |
Description |
|---|---|
|
[:alnum:] |
Alphanumeric characters (same as [:alpha:] + [:digit:]) |
|
[:alpha:] |
Alphabetic characters only |
|
[:blank:] |
Blankspace characters, such as space and tab. |
|
[:cntrl:] |
Nonprinting, or control characters |
|
[:digit:] |
Numeric digits |
|
[:graph:] |
Graphical characters (same as [:punct:] + [:upper:] + [:lower:] + [:digit:]) |
|
[:lower:] |
Lowercase letters |
|
[:print:] |
Printable characters |
|
[:punct:] |
Punctuation characters |
|
[:space:] |
Whitespace characters, such as space, form-feed, newline, carriage return, horizontal tab, and vertical tab |
|
[:upper:] |
Uppercase letters |
|
[:xdigit:] |
Hexadecimal characters |
There are pros and cons to using named character classes, but mostly pros:
You don't need to worry about the underlying code points used to represent characters in whatever character set you are using. A matching set defined as [A-Za-z] might include characters other than those letters. A matching set defined as [[:alpha:]] will contain only letters.
You can easily accommodate characters from many languages. For example, [:digit:] matches not only the English 0-9, but also the Arabic-Indic
 -
-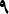 . This is important in multilingual environments.
. This is important in multilingual environments.You don't need to worry about inadvertently omitting a character from a matching set. Quick! If I want to match all punctuation, and use [.,;:!], have I forgotten anything? That worry goes away when using [[:punct:]].
You can more easily include characters that would otherwise be difficult to type from the keyboard. The [:cntrl:] class, for example, represents nonprinting, control characters.
The only downside we can think of to using named character classes, and you could argue that it's not even a downside, is that if you do use a class such as [:digit:], and you really do care only about 0-9, you may prefer the results from [0-9] instead. In practice though, we have yet to regret using a named character class whenever one fits the problem at hand.
17.3.3 Specifying Collation Elements
Oracle has always been strong in its support of multilingual data, and that strength now extends to regular expressions. When working with languages other than English, you'll sometimes encounter characters that appear to be two letters, because they are composed of two glyphs. For example, Spanish, at least old-Spanish, treats ch and ll as single letters.
Dealing with letters such as ch can sometimes be problematic. The following example shows one attempt to extract a word beginning with either the letter ch or ll from a string. We use the XSPANISH sort, because that sort works by the old rules under which ch and ll are each treated as one letter. We build our regular expression as follows:
- (^| )
-
A word is preceded by either the beginning of a line, or by a space.
- [chll]
-
We want our word to begin with either ch or ll. This bracket expression is our first attempt to define a matching set containing those two characters.
- [^[:space:][:punct:]]+
-
The first letter of our word must be followed by one or more non-space, non-punctuation characters. We could use * instead + to include one-letter words in our search.
Using the expression we've just described, we specify 'i' as the match parameter to get a case-insensitive search. Look carefully at the results:
ALTER SESSION SET NLS_SORT=XSPANISH; SELECT TRIM(REGEXP_SUBSTR( 'El caballo, Chico come la tortilla.', '(^| )[chll][^[:space:][:punct:]]+',1,1,'i')) FROM dual; caballo
This result isn't what we want at all. The problem here is that our use of [chll] results in a matching set composed of three letters, c, h, and l, any of which is deemed a valid match. Hence, our query found caballo rather than Chico. Collation element syntax lets you deal with this situation. To treat a multicharacter collation element as a single letter, enclose it within [. and .]. Then you must enclose that within a bracket expression. The result is that [.ch.] is recognized as the single letter ch, and [.ll.] is recognized as the single letter ll:
ALTER SESSION SET NLS_SORT=XSPANISH; SELECT TRIM(REGEXP_SUBSTR( 'El caballo, Chico come la tortilla.', '(^| )[[.ch.][.ll.]][^[:space:][:punct:]]+',1,1,'i')) FROM dual; Chico
Technically, any single character is a collation element. Thus, [a] and [[.a.]] are equivalent. In practice, you only need use collation element syntax when a collation element consists of multiple characters that linguistically represent one character.
|
Table 17-4 provides a list of collation elements recognized by Oracle. The elements in the table are valid only for the specified NLS_SORT settings.
|
NLS_SORT |
Multicharacter collation elements |
|---|---|
|
XDANISH |
aa AA Aaoe OE Oe |
|
XSPANISH |
ch CH Chll LL Ll |
|
XHUNGARIAN |
cs CS Csgy GY Gyly LY Lyny NY Nysz SZ Szty TY Tyzs ZS Zs |
|
XCZECH |
ch CH Ch |
|
XCZECH_PUNCTUATION |
ch CH Ch |
|
XSLOVAK |
dz DZ Dz d ch CH Ch |
|
XCROATIAN |
d lj LJ Lj nj Nj NJ |
 D
D D
D17.3.4 Defining Equivalence Classes
An equivalence class is a set of characters that would all be the same except for their case or the way they are accented. You can create such a class by using [= and =] to surround a letter when you wish to match all accented and unaccented versions of that letter. The resulting equivalence class reference must always be within a bracket expression.
For example:
SELECT REGEXP_SUBSTR('eéëèÉËÈE' '[[=É=]]+')
FROM dual;
eéëèÉËÈE
SELECT REGEXP_SUBSTR('eéëèÉËÈE', '[[=e=]]+')
FROM dual;
eéëèÉËÈE
A Regular Expression StandardRegular expressions are widely used, especially in the world of Unix and Linux. Perl, for example, has probably done more than any other tool or utility to popularize their use. Today, regular expressions are everywhere. They are supported by Perl, Python, Java, and other programming languages. You'll find regular expression support in database management systems such as Oracle and MySQL. You'll even find regular expression support in popular email clients such as The Bat!, or in programmer-oriented text editors such as MultiEdit. As ubiquitous as regular expressions have become, you may be surprised to find that regular expression syntax is not well-standardized. The POSIX standard defines a regular expression syntax, which you can read about at:
Oracle follows the POSIX standard quite closely. However, other implementations may not. Perl's metacharacters and implementation is different from Python's, is different from Java's, is different from Oracle's, is different from MySQL's. Superficially, the syntax is very similar from one platform to the next. In practice though, you should not blindly port, say, a Perl regular expression to Oracle. Take the time to study, understand, and to thoroughly test any regular expression that you decide to port to Oracle. If you're specifically interested in porting Perl regular expressions to Oracle, Jonathan Gennick and Peter Linsley's Oracle Regular Expressions Pocket Reference (O'Reilly) contains a good section describing some of the differences between those two platforms. |
It doesn't matter which version of a letter you specify between the [= and =]. All equivalent accented and unaccented letters, whether uppercase or lowercase, will match.
|






