2.1 Caching in the Database
All relational databases use some variant of the same general caching scheme to minimize physical I/O, which involves accessing disk storage, in favor of pure logical I/O, or memory-only data access. (Any data access is logical I/O. Memory-only I/O is pure logical I/O, while I/O from disk is both logical and physical I/O.) Figure 2-1 illustrates this basic caching approach.
Figure 2-1. Data caching
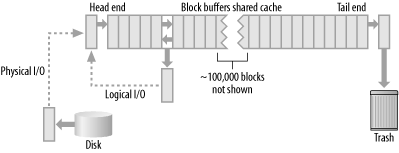
The long, horizontally stretched gray rectangle (which would be really long if it included the 100,000 blocks excised from the middle) represents a large segment of memory available to all the database sessions at once. This memory segment, known as block buffer cache, contains uniform-sized (usually 2KB-16KB, depending on the database configuration) blocks of data copied from disk. The blocks contain recently accessed data from the database tables and indexes. The narrow gray rectangles represent these individual blocks.
With minor variations, the cache is populated and maintained as follows: every time the database must access a block of data not already in cache, it requests a read from disk (physical I/O) and places the newly populated block at the head end of the buffer list. Since the list length is fixed while the database runs, adding a block at the head end forces the block at the tail end of the list to fall off (i.e., to no longer be cached).
|

When, more commonly, the database finds a data block it needs already in the cache (requiring pure logical I/O), it removes that block from its current location and relocates it to the head of the list. Since a block involved in a logical I/O is just moved rather than added to the list, no block is pushed off the tail of the list. Again, the database handles the logical block move by pointers; it doesn't physically copy the data within memory.
Since blocks move back to the head of the list with every logical I/O, the cache ends up ordered from most recently used (MRU) blocks at the head end, to least recently used (LRU) blocks at the tail end. Frequently, touched blocks are defined to be hot, while rarely touched blocks are cold. However, how hot or cold a block is depends on whether you are talking about it being touched by logical I/O or by physical I/O. The most frequently used blocks are hot from the point of view of logical I/O, though they might be cold from the point of view of physical I/O if they never leave the cache.
The block that falls off cache as a result of a physical I/O is the LRU block on the list. For this reason, the caching algorithm I'm describing is often called an LRU caching algorithm, and it is a common approach to caching throughout programming, not just for relational databases. The theory is that the hottest data will cycle to the head of the list and therefore live longer on the list. Really hot data might never leave the list at all. Keeping the most frequently used data in the cache enables rapid access to that data, which in turn enables queries to run faster than they would otherwise.
|
The LRU caching scheme has several important implications for tuning:
The MRU blocks are the fastest to access, because they will be in the cache. It is a myth, though, that cached access is effectively free. When you count the full processing-time costs tied to logical I/O, it is from 30 to 200 times faster than physical I/O. However, this is not so fast that you can ignore logical I/O, because caching is usually so good that logical I/O happens on the order of 100 times more often than physical I/O. You can still have serious performance problems from the CPU costs of unnecessary logical I/O, even after you eliminate all physical I/O. If you work to reduce logical I/O, physical I/O will mostly take care of itself, as long as you have a reasonably sized cache.
It takes several minutes without logical I/O for a block on a typical, well-configured system to migrate from the head of the list to the tail and fall off, so the hottest any block can be in terms of physical I/O is one I/O every few minutes. With more frequent access than that, the block becomes well cached and sees less physical I/O.
Table rows and index entries that share a block with other data that is frequently accessed benefit from their proximity to that hot data. The more effectively you arrange for hot data to clump together within tables and indexes, the more effective the cache is.
End users benefit from recent access of hot data by other end users, since a database cache is a shared cache, usually finding most (often 99% or more) of the data they want without physical I/O.
You will do little physical I/O on blocks that you access repeatedly within the same query, even if these blocks are normally cold, because your query itself will make them hot, and therefore cached, for most of the query.
Small tables and indexes (tables with fewer than 10,000 rows and indexes with fewer than 90,000 entries) tend to be almost perfectly cached. Occasionally, a small table or index is touched so infrequently that it is not well cached. However, infrequent access implies that any resulting slow performance will not add up to a large problem. Even when a query against a small object requires physical I/O, not much physical I/O will be performed, because the first few physical I/Os will place the entire object in the cache for the duration of the query. I use the term self-caching to describe the process by which a query to normally cold blocks makes those blocks hot for the duration of the query. Self-caching lets you safely ignore potential physical I/O to small tables and indexes, even in the uncommon case in which small objects are cold.
Even the largest indexes tend to be at least moderately well cached, because indexes are much more compact than tables, and because access plans involving these indexes tend to hit mostly the hotter parts of the indexes.
Only large tables (tables holding over 1,000,000 rows) tend to be poorly cached, unless you systematically touch only some hot subset of a table. Minimizing the number of different blocks that you hit in the largest tables, to avoid excessive physical I/O, is particularly important to performance.
All else being equal (i.e., given alternatives that require the same number of logical I/Os), favor the alternative that drives to hotter blocks. This is often the alternative that goes through an index, since index blocks and table blocks reached by indexed access tend to be hotter than random table blocks.






