7.1 Abnormal Join Diagrams
If your query contains only simple tables (not views), no subqueries, and no set operations such as UNION, you can always produce some sort of query diagram by applying the methods of Chapter 5. However, sometimes a diagram has abnormal features that fail to match the usual join-tree template described earlier. I will describe these anomalies one by one and discuss how to handle each one.
To illustrate the anomalies, I will show partial query diagrams, in which the parts of the diagram that are not significant to the discussion are hidden behind gray clouds. This focuses attention on the part that matters, and makes clearer the generality of the example. As a convention, I will show links to parts of the join skeleton hidden behind the clouds in gray when they are not significant to the discussion. The number of gray links or even the existence of gray links is not significant to the examples, just illustrative of the potential existence of added joins in real cases. Occasionally, I will have black links to hidden parts of the query skeleton. The existence of the black links is significant to the discussion, but the hidden part of the query skeleton is not.
7.1.1 Cyclic Join Graphs
How do you handle join skeletons that do not map to a simple tree but contain links that close a loop somewhere in the skeleton? There are several cases for which you might encounter such a diagram. In the following sections, I will discuss four cases with distinct solutions.
|

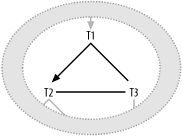
7.1.1.1 Case 1: Two one-to-one master tables share the same detail table
Figure 7-1 illustrates the first case, in which a single foreign key joins to primary keys in two different master tables.
Figure 7-1. Case 1 for a cyclic query diagram
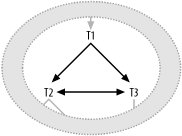
In this case, you can infer that the SQL itself looks something like this:
SELECT ... FROM ...T1, ... T2, ... T3, ... WHERE ... T1.FKey1=T2.PKey2 AND T1.FKey1=T3.PKey3 AND T2.PKey2=T3.PKey3 ...
Here, I have named the single foreign key that points to both tables from T1 FKey1, and I have named the primary keys of T2 and T3 PKey2 and PKey3, respectively. With all three of these joins explicit in the SQL, the cyclic links are obvious, but note that you could have left any one of these links out of the query, and transitivity (if a=b and b=c, then a=c) would imply the missing join condition. If one of these joins were left out, you might diagram the same query in any of the three forms shown in Figure 7-2.
Figure 7-2. The same cyclic query, missing one of the three transitive join conditions
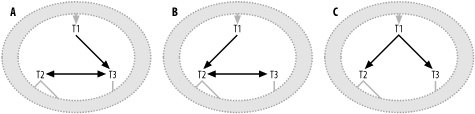
Note that in versions A and B of this query you can infer the missing arrow from the fact that the link between T2 and T3 has an arrowhead on both ends, and an arrow at both ends implies a one-to-one join. Version C, on the other hand, looks exactly like a plain-vanilla join tree, and you would not realize that it had cyclic joins unless you happened to notice that T1 used the same foreign key to join to both T2 and T3.
When you have one-to-one tables, cyclic joins like the one in Figure 7-1 are common. These are not a functional problem, though I will later describe issues to consider whenever you encounter a one-to-one join. Instead of being a problem, you can see such joins as an opportunity. If you have already reached T1, it is useful to have the choice of either T2 or T3 next, since either might have the better filter ratio or provide access to good filters lower down the tree. If you reach either T2 or T3 in the join order before you reach T1, it is also useful to have the option to join one-to-one to the other (from T2 to T3, or from T3 to T2). This enables you to reach any filter the other table might have, without joining to T1 first. Without the horizontal link, you could join from T2 to T3 or vice versa, only through T1, at likely higher cost.
Some optimizers are written cleverly enough to use transitivity to fill in a missing join condition even if it is left out and take advantage of the extra degrees of freedom that are provided in the join order. However, to be safe, it is best to make all three joins explicit if you notice that two joins imply a third by transitivity. At the least, you should make explicit in your SQL statement any join you need for the optimum plan you find.
There exists a special case in which the one-to-one tables shown as T2 and T3 are the same table! In this case, each row from T1 joins to the same row of T2 twice, a clear inefficiency. The obvious cause, having the same table name repeated twice in the FROM clause and aliased to both T2 and T3, is unlikely, precisely because it is too obvious to go unnoticed. However, a join to the same table twice can happen more subtly and be missed in code review. For example, it can happen if a synonym or simple view hides the true identity of the underlying table behind at least one of the aliases in the query. Either way, you are clearly better off eliminating the redundant table reference from the query and shifting all column references and further downward joins to the remaining alias.
7.1.1.2 Case 2: Master-detail tables each hold copies of a foreign key that points to the same third table's primary key
Figure 7-3 shows the second major case with cyclic joins. Here, identical foreign keys in T1 and T2 point to the same primary key value in T3.
Figure 7-3. A cyclic join that implies denormalization
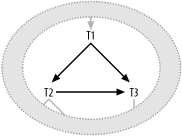
This time, the SQL looks like this:
SELECT ... FROM ...T1, ... T2, ... T3, ... WHERE ... T1.FKey1=T2.PKey2 AND T1.FKey2=T3.PKey3 AND T2.FKey2=T3.PKey3 ...
In this SQL statement, I name the foreign keys that point from T1 to T2 and T3 FKey1 and FKey2, respectively. By transitivity, the foreign-key column T2.FKey2 has the same value as T1.FKey, since both join to T3.PKey3. I name the primary keys of T2 and T3 PKey2 and PKey3, respectively. The most likely explanation for T1 and T2 joining to the same table, T3, on its full primary key is that T1 and T2 contain redundant foreign keys to that table. In this scenario, the FKey2 column in the detail table T1 has denormalized data from its master table T2. This data always matches the FKey2 value in the matching master row of T2.
|
Chapter 10 covers the pros and cons of denormalization in cases like this. Briefly, if the normalization is justifiable, it is possible that the extra link in the query diagram will buy you access to a better execution plan. However, it is more likely that the denormalization is a mistake, with more cost and risk than benefit. Eliminating the denormalization would eliminate the foreign key FKey2 in T1, thus eliminating the link from T1 to T3 and making the query diagram a tree.
7.1.1.3 Case 3: Two-node filter (nonunique on both ends) between nodes is already linked through normal joins
Figure 7-4 shows the third major case with cyclic joins. This time, you have normal downward arrows from T1 to T2 and T3, but you also have some third, unusual join condition between T2 and T3 that does not involve the primary key of either table.
Figure 7-4. A cyclic join with a two-node filter
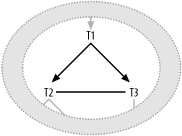
|
The SQL behind Figure 7-4 looks like this:
SELECT ... FROM ...T1, ... T2, ... T3,... WHERE ... T1.FKey1=T2.PKey2 AND T1.FKey2=T3.PKey3 AND T2.Col2<IsSomeHowComparedTo>T3.Col3 ...
For example, if T1 were on the Orders table, having joins to Customers, T2, and Salespersons, T3, a query might request orders in which customers are assigned to different regions than the salesperson responsible for the order:
SELECT ... FROM Orders T1, Customers T2, Salespersons T3 WHERE T1.Customer_ID=T2.Customer_ID AND T1.Salesperson_ID=T3.Salesperson_ID AND T2.Region_ID!=T3.Region_ID
Here, the condition T2.Region_ID!=T3.Region_ID is technically a join, but it is better to view it as a filter condition that happens to require rows from two different tables before it can be applied. If you ignore the unusual, arrow-free link between T2 and T3, you will reach T1 before you can apply the two-node filter on Region_ID. The only allowed join orders, which avoid directly following the unusual join between T2 and T3, are:
- (T1, T2, T3)
- (T1, T3, T2)
- (T2, T1, T3)
- (T3, T1, T2)
Any join order other than these four (such as (T2, T3, T1)) would create a disastrous many-to-many explosion of rows after reaching the second table, almost a Cartesian product of the rows in T2 and T3. All of these join orders reach T1 by the first or second table, before you have both T2 and T3. These join orders therefore follow only the two ordinary many-to-one joins between the detail table T1 and its master tables T2 and T3.
The unusual, two-node filter acts like no filter at all when you reach the first of the two filtered tables, then it acts like an ordinary filter, discarding some fraction of rows, when you reach the second of the two tables. Viewed in this way, handling this case is fairly straightforward: consider the filter to be nonexistent (or at least not directly accessible) until you happen to join to one of the filtered tables as a matter of course. However, as soon as you have joined to either end of the two-node filter, the other node suddenly acquires a better filter ratio and becomes more attractive to join to next.
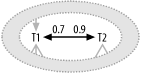
Figure 7-5 shows a specific example with a two-node filter, in which the fraction of rows from the ordinary joins from T1 to T2 and T3 that meet the additional two-node filter condition is 0.2. In this case, you would initially choose a join order independent of the existence of the two-node filter, following only ordinary join links. However, as soon as you happened to join to either T2 or T3, the other would have its former filter ratio (1.0 for T2 and 0.5 for T3) multiplied by 0.2, becoming much more attractive for future joins.
Figure 7-5. A two-node filter with explicit two-node filter ratio
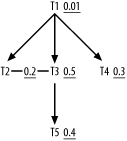
Follow the normal procedure to tune Figure 7-5, ignoring the two-node filter between T2 and T3 until you reach one of those tables as a matter of course. The driving table is T1, followed by T4, the table with the best ordinary filter downstream of T1. T3 has the next best ordinary filter available, with the filter ratio 0.5, so it follows next in the join order. Now, you have a choice between T2 and T5 next in the join order, but T2 has at last seen the two-node filter activated, since you just reached T3, so it has a more effective filter ratio, at 0.2, than T5 has, and you join to T2 next. The final best join order is (T1, T4, T3, T2, T5).
|
7.1.1.4 Case 4: Multipart join from two foreign keys is spread over two tables to a multipart primary key
Finally, Figure 7-6 shows the fourth major case with cyclic joins. Here are two unusual joins to T3, neither using the whole primary key of that table nor the primary keys of the tables on the other ends of these joins. If such cases of failing to join to the whole primary key on at least one end of each join are "wrongs," then Case 4 is usually a case in which two wrongs make a right!
Figure 7-6. A cyclic join with two unusual joins
In a situation such as that shown in Figure 7-6, the SQL typically looks like this:
SELECT ... FROM ...T1, ... T2, ... T3, ... WHERE ... T1.FKey1=T2.PKey2 AND T1.FKey2=T3.PKeyColumn1 AND T2.FKey3=T3.PkeyColumn2 ...
Such SQL typically arises when you have a two-part primary key on T3 and the two-part foreign key is somehow distributed over two tables in a master-detail relationship.
A concrete example will clarify this case. Consider data-dictionary tables called Tables, Indexes, Table_Columns, and Index_Columns. You might choose a two-part primary key for Table_Columns of (Table_ID, Column_Number), where Column_Number designates the place that table column holds in the natural column order of the table1 for the first column, 2 for the second, and so on. The Indexes table would have a foreign key to Tables on the Table_ID column, and the Index_Columns table would also have a two-part primary key, (Index_ID, Column_Number). The Column_Number value in the Index_Columns has the same meaning as Column_Number in Table_Columns: the place the column holds in the natural order of table columns (not its place in the index order, which is Index_Position). If you knew the name of an index and wished to know the list of column names that make up the index in order of Index_Position, you might query:
SELECT TC.Column_Name FROM Indexes Ind, Index_Columns IC, Table_Columns TC WHERE Ind.Index_Name='EMPLOYEES_X1' AND Ind.Index_ID=IC.Index_ID AND Ind.Table_ID=TC.Table_ID AND IC.Column_Number=TC.Column_Number ORDER BY IC.Index_Position ASC
|
If the condition on Index_Name had a filter ratio of 0.0002, the query diagram, leaving off the join ratios, would look like Figure 7-7.
Figure 7-7. A concrete example of the fourth type of cyclic join
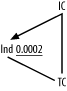
Here, two wrongs (i.e., two joins that fail to find a full primary key on either side) combine to make a right when you consider the joins to TC together, because combined they reach the full primary key of that table. You can transform the diagram of this uncommon case generically, as in Figure 7-8.
Figure 7-8. Combining multipart joins from foreign keys distributed across two tables
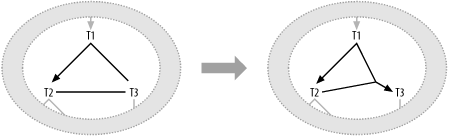
If you follow the rule of thumb to join either to or from full primary keys, the best join order for Figure 7-7 becomes clear. Drive from the filter on Ind and follow the upward link to IC. Only then, after reaching both parts of the primary key to TC, should you join to TC. This is, in fact, the best execution plan for the example. The rule of thumb in these cases is only to follow these unusual links into a multipart primary key once the database has reached all the upward nodes necessary to use the full primary key.
7.1.1.5 Cyclic join summary
The following list summarizes the way in which you should treat each of the four cyclic join types just described:
- Case 1: Two one-to-one master tables share the same detail table
-
This is an opportunity for tuning, increasing the degrees of freedom in the join order, but you should consider options spelled out later in this chapter for handling one-to-one joins.
- Case 2: Master-detail tables each hold copies of a foreign key pointing to the same third table's primary key
-
This too is an opportunity to increase the degrees of freedom in the join order, but the case implies denormalization, which is usually not justified. Remove the denormalization if you have the choice, unless the benefit to this or some other query justifies the denormalization. Chapter 10 describes further how to evaluate the trade offs involved in denormalization.
|
- Case 3: Two-node filter (nonunique on both ends) between nodes is already linked through normal joins
-
Treat this uncommon case as no filter at all until you reach one of the nodes. Then, treat the other node as having a better filter ratio for purposes of finding the rest of the join order.
- Case 4: Multipart join from two foreign keys is spread over two tables to a multipart primary key
-
Perform this join into the primary key only when you have both parts of the key.
7.1.2 Disconnected Query Diagrams
Figure 7-9 shows two cases of disconnected query diagrams: query skeletons that fail to link all the query tables into a single connected structure. In each of these cases, you are in a sense looking at two independent queries, each with a separate query diagram that you can optimize in isolation from the other query.
Figure 7-9. Disconnected query diagrams
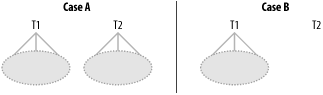
In Case A, I show a query that consists of two independent-appearing queries that each have joins. In Case B, I show an otherwise ordinary-looking query that has one of its tables (table T2) disconnected from the join tree (i.e., not joined to any other table). Each of the two cases maps to two independent queries being run within a single query. What happens when you combine independent, disconnected queries into a single query? When two tables are combined in a single query without any join condition, the database returns a Cartesian product: every possible combination of the rows from the first table with the rows from the second table. In the case of disconnected query diagrams, think of the query result represented by each independent query skeleton (or isolated node) as being its own virtual table. From this point of view, you can see that the database will return all combinations of rows from the two independent queries. In short, you'll get a Cartesian product.
When confronted with a Cartesian product such as the one shown in Figure 7-9, you should investigate the reason behind it. Once you learn the reason, you can decide which of the following courses of action to take, depending on which of four cases of disconnected queries you have:
- Case 1: Query is missing a join that would connect the disconnected parts
-
Add the missing join.
- Case 2: Query combines two independent queries, each returning multiple rows
-
Eliminate this Cartesian product by running the independent queries separately.
- Case 3: One of the independent queries is a single-row query
-
Consider separating the queries to save bandwidth from the database, especially if the multirow independent query returns many rows. Execute the single-row query first.
- Case 4: Both of the independent queries are single-row queries
-
Keep the query combined, unless it is confusing or hard to maintain.
Before you turn a disconnected query into two separate queries, consider whether the developer might have inadvertently left a join out of the single query. Early in the development cycle, the most common cause of disconnected query diagrams is developers simply forgetting some join clause that links the disconnected subtrees. When this is the case, you should add in the missing join condition, after which you will no longer have a disconnected tree. Whenever one of the tables in one tree has a foreign key that points to the primary key of the root node of the other tree, that join was almost certainly left out accidentally.
If each independent query returns multiple rows, the number of combinations will exceed the number of rows you would get if you just ran the two queries separately. However, the set of combinations from the two contains no more information than you could get if you ran these separately, so the work of generating the redundant data in the combinations is just a waste of time, at least from the perspective of getting raw information. Thus, you might be better off running the two queries separately.
Rarely, there are reasons why generating the combinations in a Cartesian product is at least somewhat defensible, from the perspective of programming convenience. However, you always have workarounds that avoid the redundant data if the cost is unjustified.
|
If one of the independent queries returns just a single row, guaranteed, then at least the Cartesian product is safe and is guaranteed to return no more rows than the larger independent query would return. However, there is still potentially a small network cost in combining the queries, because the select list of the combined query might return the data from the smaller query many times over, once for each row that the multirow query returns, requiring more redundant bytes than if you broke up the queries. This bandwidth cost is countered somewhat with network-latency savings: the combined query saves you round trips to the database over the network, so the best choice depends on the details. If you do not break the up queries, the optimum plan is straightforward: just run the optimum plan for the single-row query first. Then, in a nested loop that executes only once, run the optimum plan for the multirow query. This combined execution plan costs the same as running the two queries separately. If, instead, you run the plan for the multirow query first, a nested-loops plan would require you to execute the plan for the single-row query repeatedly, once for every row of the other query.
Combining a single-row query with a multirow query is sometimes convenient and justified. There is a special case, matching the right half of Figure 7-9, in which the single-row query is simply a read of the only row of isolated table T2, which has no joins at all. A Cartesian product with an isolated table is sometimes useful to pick up site parameters stored in a single-row parameters table, especially when these parameters show up only in the WHERE clause, not in the SELECT list. When the query does not return data from the parameters table, it is actually cheaper to run the correctly combined query than to run separate queries.
An even rarer case guarantees that both isolated queries return a single row. It is fully justified and safe, from the performance perspective, to combine the queries in this case, which lacks any of the dangers of the other cases. However, from the programming and software-maintenance perspective, it might be confusing to combine queries like this, and the savings are generally slight.
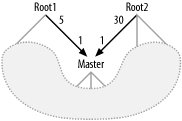
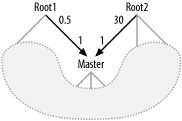
7.1.3 Query Diagrams with Multiple Roots
Figure 7-10 shows an example of a query diagram that violates the one-root expectation. This case is akin to the previous case (disconnected query diagrams). Here, for each row in the Master table shown that satisfies the query condition, the query will return all combinations of matching details from Root1 and Root2. Given the detail join ratios, you can expect all combinations of 5 Root1 details with 30 Root2 details, for 150 combination rows for each matching Master row. These 150 combination rows contain no more original data than the 5 Root1 details combined with the 30 Root2 details, so it is faster to read these 5 and 30 rows separately, avoiding the Cartesian product. While disconnected query diagrams generate a single large Cartesian product, multiple root nodes generate a whole series of smaller Cartesian products, one for each matching master row.
Figure 7-10. Query diagram with multiple roots
There are four possible causes of a query diagram with multiple roots. The following list details these causes, and describes their solutions:
- Case 1: Missing condition
-
The query is missing a condition that would convert one of the root detail tables into a master table, making a one-to-many join one-to-one.
Solution: Add the missing join condition.
- Case 2: Many-to-many Cartesian product
-
The query represents a many-to-many Cartesian product per master-table row between detail tables that share a master table. This appears in the guise of detail join ratios greater than 1.0 from a single shared master to two different root detail tables.
Solution: Eliminate this Cartesian product by separating the query into independent queries that read the two root detail tables separately.
- Case 3: Detail join ratio less than 1.0
-
One of the root detail tables joins to the shared master table with a detail join ratio less than 1.0.
Solution: Although this is not a problem for performance, consider separating the query parts or turning one of the query parts into a subquery, for functional reasons.
- Case 4: Table used only for existence check
-
One of the root detail tables supplies no data needed in the SELECT list and is included only as an existence check.
Solution: Convert the existence check to an explicit subquery.
7.1.3.1 Case 1: Missing join conditions
Most often, the appearance of a second root node points to some missing join condition that would convert one of the root nodes to a master node. Figure 7-11 shows this transformation, where the join from Master to Root1 has been converted to a one-to-one join by the addition (or recognition) of some extra condition on Root1 (renamed R1) that ensures that the database will find at most one row in R1 for every row in Master. This is particularly likely when R1 contains time-interval detail data (such as a varying tax rate) that matches a master record (such as taxing entity) and the addition of a date condition (such as requesting the current tax rate) makes the join one-to-one.
Figure 7-11. Repairing a query with multiple root nodes
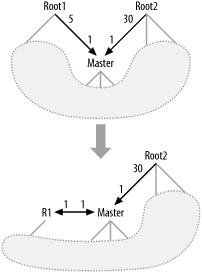
Often, the condition that makes the join one-to-one is already there, and you find a combination of a many-to-one join and an apparent filter that just cancels the detail join ratio.
|
Alternatively, the condition that makes the join one-to-one might be missing from the query, especially if development happens in a test system where the one-to-many relationship is hidden.
|
Whether the condition that makes the join one-to-one was missing or was just not recognized as being connected with the join, you should include the condition and recognize it as part of the join, not as an independent filter condition. Such a missing join condition is particularly likely when you find that the foreign key for one of the root tables pointing downward to a shared master table is also part of the multipart primary key of that root table.
7.1.3.2 Case 2: Breaking the Cartesian product into multiple queries
Figure 7-12 shows another solution to the multiroot-query-diagram problem. This solution is akin to running explicitly separate queries in the disconnected query diagram (discussed earlier), breaking up the Cartesian product and replacing it with the two separate sets. In the example, this replaces a query that would return 150 rows per Master row with two queries that, combined, return 35 rows per Master row. Whenever you have one-to-many relationships from a master table to two different detail root tables, you can get precisely the same underlying data, with far fewer rows read and with separate queries, as illustrated. Since the result takes an altered form, you will also need to change the underlying application logic to handle the new form.
Figure 7-12. Resolving the Cartesian product with separate queries
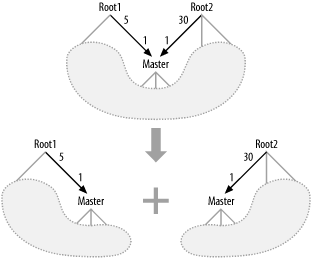
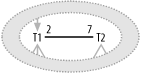
7.1.3.3 Case 3: Root detail tables that are usually no more than one-to-one
Figure 7-13 shows a case of multiple roots in which performance of the query, unaltered, is not a problem. Since the detail join ratio from Master to Root1 is 0.5, you see no Cartesian explosion of rows when you combine matching Root1 with Root2 records for the average matching Master record. You can treat Root1 as if it were a downward join, even favoring it as if it had a filter ratio enhanced by 0.5 for the filtering join, following the special-case rules in Chapter 6 for detail join ratios less than 1.0.
Figure 7-13. A Cartesian product with a low detail join ratio
Although this query is no problem for tuning, it might still be incorrect. The one-to-zero or one-to-many join from Master to Root1 evidently usually finds either the one-to-zero or the one-to-one case, leading to a well-behaved Cartesian product. However, as long as the join is ever one-to-many, you must consider that the result might return a Cartesian product with repeats for a given row of Root2. Since this case is rare, it is all too likely that the query was actually designed and tested to return results that map one-to-one with rows from Root2, and the application might not even work in the other rare case.
|
For example, if the application will alter Root2 data after reading it out with this query and attempt to post the alterations back to the database, the application must consider which copy of a repeated Root2 row should get posted back to the database. Should the application warn an end user that it attempted to post inconsistent copies? If the application aggregates Root2 data from the query, does it avoid adding data from repeated Root2 rows?
7.1.3.4 Case 4: Converting an existence check to an explicit subquery
One solution to the functional problem that Figure 7-13 represents is already shown in Figure 7-12: just break up the query into two queries. Another solution, surprisingly often, is to isolate the branch to Root1 into a subquery, usually with an EXISTS condition. This solution works especially easily if the original query did not select columns from Root1 (or any of the tables joined below it through hidden gray links in Figure 7-13). In this relatively common special case, you are really interested only in whether a matching row in Root1 exists and perhaps matches some filter conditions, not in the contents of that row or the number of matches (beyond the first) that might exist. Later in this chapter, you will see how to diagram and tune queries with subqueries like this.
7.1.4 Joins with No Primary Key
I use join links without arrows on either end to show joins that involve no primary key on either side of the join. In general, these represent unusual many-to-many joins, although in some cases they might usually be many-to-zero or many-to-one. If they are never many-to-many, then you simply failed to recognize the unique condition and you should add an arrow to the unique side of the join. If they are at least sometimes many-to-many, you have all the same problems (and essentially the same solutions) you have with query diagrams that have multiple root nodes. Figure 7-14 shows a many-to-many join between T1 and T2, where the detail join ratio on each end is greater than 1.0. (Master join ratios exist only on the unique end of a link, with an arrow, so this link has two detail join ratios.)
Figure 7-14. A many-to-many join
This case turns out to be much more common than the previous examples of abnormal join diagrams. Although it shares all the same possible problem sources and solutions as the case of multiple root nodes, the overwhelming majority of many-to-many joins are simply due to missing join conditions. Begin by checking whether filter conditions already in the query should be treated as part of the join, because they complete specification of the full primary key for one end of the join. Example 5-2 in Chapter 5 was potentially such a case, with the condition OT.Code_Type='ORDER_STATUS' needed to complete the unique join to alias OT. Had I treated that condition as merely a filter condition on alias OT, the join to OT would have looked many-to-many. Even if you do not find the missing part of the join among the query filter conditions, you should suspect that it was mistakenly left out of the query.
This case of missing join conditions is particularly common when the database design allows for multiple entity types or partitions within a table and the developer forgets to restrict the partition or type as part of the query. For example, the earlier example of a Code_Translations table has distinct types of translation entities for each Code_Type, and leaving off the condition on Code_Type would make the join to Code_Translations many-to-many. Often, testing fails to find this problem early, because even though the database design might allow for multiple types or partitions, the test environment might have just a single type or partition to begin with, a state of affairs developers might take for granted. Even when there are multiple types or partitions in the real data, the other, more selective part of the key might, by itself, be usually unique. This is both good and bad luck: while it prevents the missing join condition from causing much immediate trouble, it also makes the problem much harder to detect and correct, and lends a false sense that the application is correct. Finding and correcting the missing join condition might help performance only slightly, by making the join more selective, but it can be a huge service if it fixes a really pernicious hidden bug.
By direct analogy with query diagrams that have multiple root nodes, the solutions to many-to-many joins map to similar solutions to diagrams with multiple root nodes.
7.1.5 One-to-One Joins
You have probably heard the joke about the old fellow who complains he had to walk five miles to school every morning uphill both ways. In a sense, one-to-one joins turn this mental picture on its head: for the heuristic rules of which table to join next, one-to-one joins are downhill both ways! As such, these joins create no problem for tuning at all, and these are the least troublesome of the unusual features possible in a query diagram. However, they do sometimes point to opportunities to improve database design, if you are at a point in the development cycle when database design is not yet set in stone. It is also useful to have a standard way to represent one-to-one joins on a query diagram, so I will describe ways to represent these cases.
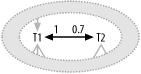
7.1.5.1 One-to-one join to a subset table
Figure 7-15 shows a typical one-to-one join embedded in a larger query. While many-to-many joins have detail join ratios on both ends, one-to-one joins have master join ratios on both ends. The master join ratios in the example show that the join between T1 and T2 is really one-to-zero or one-to-one; the one-to-zero case happens for 30% of the rows in T1.
Figure 7-15. A typical one-to-one join
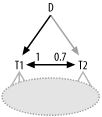
Since this is an inner join, the one-to-zero cases between T1 and T2 make up a hidden join filter, which you should handle as described at the end of Chapter 6. Also note that this might be a case of a hidden cyclic join, as often happens when a master table joins one-to-one with another table. If you have a detail table above T1, as implied by the gray link upward, and if that detail table joins to T1 by the same unique key as used for the join to T2, then you have, by transitivity, an implied join from the detail table to T2. Figure 7-16 shows this implied link in gray. Refer back to cyclic joins earlier in this chapter for how to handle this case.
Figure 7-16. An implied link making a cyclic join
Whether or not you have a cyclic join, though, you might have an opportunity to improve the database design. The case in Figure 7-16 implies a set of entities that map one-to-one with T1 and a subset of those same entities that map one-to-one with T2, with T2 built out of T1's primary key and columns that apply only to that subset. In this case, there is no compelling need to have two tables at all; just add the extra columns to T1 and leave them null for members of the larger set that do not belong to the subset! Occasionally, there are good reasons why development prefers a two-table design for convenience in a situation like this. However, from the perspective of tuning, combining these two comparably sized tables is almost always helpful, so at least give it some thought if you have any chance to influence the database design.
7.1.5.2 Exact one-to-one joins
Figure 7-17 shows an especially compelling case for combining the tables into a single table, when possible. Here, the master join ratios are each exactly 1.0, and the relationship between the tables is exactly one-to-one. Both tables, therefore, map to the same set of entities, and the join is just needless expense compared to using a combined table.
Figure 7-17. A precise one-to-one join
The only reason, from a performance perspective, to separate these tables is if queries almost always need just the data from one or the other and rarely need to do the join. The most common example of this is when one of the tables has rarely needed data, compared to the other. In that case, especially if the rarely needed data takes up a lot of space per row and the tables are large, you might find that the better compactness of the commonly queried table, resulting in a better cache-hit ratio, will (barely) justify the cost of the rarely needed joins. Even from a functional or development perspective, it is likely that the coding costs of adding and deleting rows for both tables at onceand, sometimes, updating both at onceare high. You might prefer to maintain a single, combined table. Usually, when you see an exact one-to-one join, it is a result of some bolted-on new functionality that requires new columns for existing entities, and some imagined or real development constraint prevented altering the original table. When possible, it is best to solve the problem by eliminating that constraint.
7.1.5.3 One-to-one join to a much smaller subset
At the other end of the spectrum, you have the case shown in Figure 7-18, a one-to-zero or one-to-one join that is almost always one-to-zero. Here, the case for separating the tables is excellent. The tiny subset of entities represented by T2 might have different optimization needs than the superset represented by T1. Probably, T1 is usually queried without the join to T2, and, in these cases, it is useful that it excludes the inapplicable columns in T2 and has only the indexes that make sense for the common entities. Here, the hidden join filter represented by the small master join ratio on the T2 side of the join is excellent. It is so good, in fact, that you might choose to drive from an unfiltered full table scan of T2 and still find the best path to the rest of the data. Such an execution plan would be hard to approximate, without creating otherwise useless indexes, if you combined these tables into a single table.
Figure 7-18. A one-to-zero or one-to-one join between very different-sized tables
Here, the key issue is not to neglect to take into account the hidden join filter from T1 to T2, either driving from the T2 side of the query or reaching it as soon as possible to pick up the hidden filter early.
7.1.5.4 One-to-one joins with hidden join filters in both directions
Figure 7-19 shows a rare case of a [zero or one]-to-[zero or one] join, which filters in both directions. If one-to-one joins are downhill in both directions, then [zero or one]-to-[zero or one] joins are steeply downhill in both directions. However, unless data is corrupt (i.e., one of the tables is missing data), this rare case probably implies that yet a third table exists, or should exist, representing a superset of these two overlapping sets. If you find or create such a table, the same arguments as before apply for combining it with one or both of the subset tables.
Figure 7-19. A [zero or one]-to-[zero or one] join
7.1.5.5 Conventions to display one-to-one joins
It helps to have agreed-upon conventions for laying out query diagrams. Such conventions aid tuning intuition by presenting key information uniformly. Single-ended arrows always point down, by convention. Figure 7-20 shows two alternatives that work well for one-to-one joins that lie below the root detail table. The first alternative emphasizes the two-headed arrow, placing neither node above the other. The second alternative emphasizes the usual downward flow of reference links from the root detail table. Either alternative works well, as long as you remember that both directions of a one-to-one join are, in the usual sense, downward.
Figure 7-20. Diagramming one-to-one joins lying under a root detail table
For this case, in which both joined tables are below the root, keep in mind that if the one-to-one tables actually share a common primary key, then the link from above into T1 could probably just as easily be to T2, by transitivity, unless it is to some alternate unique key on T1 not shared by T2. This is the implied cyclic-join case illustrated with form B in Figure 7-2.
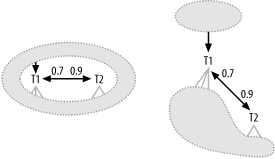
Figure 7-21 illustrates alternate diagrams for one-to-one joins of tables that both qualify as root detail tables (i.e., they have no joins from above), where at least one of the directions of the one-to-one join shows a master join ratio less than 1.0. Again, you can emphasize the one-to-one link with a horizontal layout, or you can emphasize which table is larger (and which direction of the join is "more downhill") by placing the node with the larger master join ratio higher. The node with the larger master join ratio represents a table with more rows in this [zero or one]-to-[zero or one] join.
Figure 7-21. Alternate diagram methods for [zero or one]-to-[zero or one] root detail tables
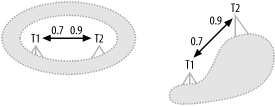
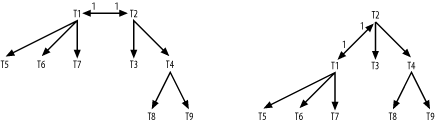
Figure 7-22 illustrates a case similar to Figure 7-21, but with nodes that are perfectly one-to-one (tables that always join successfully). Again, you can emphasize the equal nature of the join directions by laying the nodes out horizontally. Alternatively, you can just choose a direction that makes a more balanced-looking tree, which fits better on the page, placing the node with deeper branches at the top. The choice in this case matters least, as long as you remember that both join directions are virtually downhill, regardless of how you lay out the diagram.
Figure 7-22. Alternate diagram methods for exact one-to-one root detail tables
7.1.6 Outer Joins
Almost always, the sense and purpose of an outer join is that it prevents loss of desired information from the joined-from table, regardless of the contents of the outer-joined table. Abnormal outer joins, which I describe in the following sections, generally imply some contradiction of this reason behind the outer join.
7.1.6.1 Filtered outer joins
Consider Figure 7-23, with an outer join to a table with a filter condition. In the outer case, the case where a T1 row has no matching T2 row, the database assigns null to every T2 column in the result. Therefore, except for T2.SomeColumn IS NULL, almost any filtering condition on T2 would specifically exclude a result row that comes from the outer case of the outer join.
Figure 7-23. Outer join to a filtered node
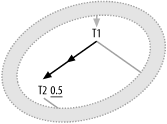
Even conditions such as T2.Unpaid_Flag != 'Y' or NOT T2.Unpaid_Flag = 'Y', which you might expect to be true for the outer case, are not.
|
Since most filters on the outer table discard the outer case of an outer join, and since the whole purpose of an outer join is to preserve such cases, you need to give careful attention to any filter on an outer table. One of the following scenarios applies, and you should take the time to determine which:
The filter is one of the rare filters, such as SomeColumn IS NULL, that can return TRUE for null column values inserted in the outer case, and the filter is functionally correct.
The developer did not intend to reject the outer case, and the filter condition must be removed.
The filter condition was meant to reject the outer case, and the join might as well be an inner join. When this is the case, there is no functional difference between the query with the join expressed as an outer or as an inner join. However, by expressing it formally as an inner join, you give the database more degrees of freedom to create execution plans that might perform this join in either direction. When the best filter is on the same side of the join as the formerly-outer-joined table, the added degrees of freedom might enable a better execution plan. On the other hand, converting the join to an inner join might just enable the optimizer to make a mistake it would have avoided with an outer join. Outer joins are one way to constrain join orders when you consciously wish to do so, even when you do not need to preserve the outer case.
The filter condition was intended, but it should be part of the join! With the filter condition made part of the join, you order the database: "For each detail-table row, provide the matching row from this table that fits this filter, if any; otherwise, match with an all-null pseudorow."
Single-Table Outer Join ConditionsIn the old-style Oracle notation, you make the filter condition part of the join by adding (+). For example, a two-part outer join to the Code_Translations table used in earlier examples would look like this: WHERE ... AND O.Order_Type_Code=OTypeTrans.Code(+) AND OTypeTrans.Type(+)='ORDER_TYPE' In the newer-style ANSI join notation, which is the only outer join notation allowed in DB2, the filter condition migrates into the FROM clause to become an explicit join condition: FROM ... Orders O ...
LEFT OUTER JOIN Code_Translations OTypeTrans
ON O.Order_Type_Code=OTypeTrans.Code
AND OTypeTrans.Type='ORDER_TYPE'
In the original outer-join notation on SQL Server, the database simply assumes that the filter condition is part of the join: WHERE ... AND O.Order_Type_Code*=OTypeTrans.Code AND OTypeTrans.Type='ORDER_TYPE' Note that this makes the problem just discussed impossible for old-style SQL Server outer joins; the database has made the filter part of the join automatically. Also note that in the rare case in which the filter is truly a filter, you must either convert to a new-style outer join to get the desired result, or convert the join into an equivalent NOT EXISTS subquery, as I explain next. |
Let's consider the first scenario in further depth. Consider the query:
SELECT ...
FROM Employees E
LEFT OUTER JOIN Departments D
ON E.Department_ID=D.Department_ID
WHERE D.Dept_Manager_ID IS NULL
What is the query really asking the database in this case? Semantically, this requests two rather distinct rowsets: all employees that have no department at all and all employees that have leaderless departments. It is possible that the application actually calls for just two such distinct rowsets at once, but it is more likely that the developer did not notice that such a simple query had such a complex result, and did not intend to request one of those rowsets.
Consider a slightly different example:
SELECT ... FROM Employees E
LEFT OUTER JOIN Departments D
ON E.Department_ID=D.Department_ID
WHERE D.Department_ID IS NULL
On the surface, this might seem to be a bizarre query, because the primary key (Department_ID) of Departments cannot be null. Even if the primary key could be null, s






