7.3 Queries with Views
A view can make an arbitrarily complex query look like a simple table from the point of view of a person writing a query using the view. When multiple queries will share much underlying SQL, shared, reusable views can be a powerful mechanism to reduce complexity in application code. Unfortunately, simply hiding steps from the application developer does not reduce the underlying complexity of the steps to reach actual data. On the contrary, hiding complexity from the developer will more likely than not increase the difficulty of the tuning problem that the optimizer, whether automated or human, must overcome to find a fast execution plan. In this discussion, I refer to two types of queries important to the tuning problem:
- View-defining queries
-
These are the queries that underlie views (i.e., the queries used to create views with CREATE VIEW <ViewName> AS <ViewDefiningQuery>).
- View-using queries
-
These are queries you tune and that the database must actually execute. These queries reference views in their FROM clause (for example, SELECT ... FROM View1 V1, View2 V2,... WHERE ...).
|
When you tune SQL, views tend to add complexity in three ways:
You must translate a view-using query into an equivalent query against real tables to create and optimize a join diagram.
Queries against views often contain unnecessary or redundant nodes in the query skeleton. Each view carries with it a whole view-defining query, complete with a subtree that includes all view-defining nodes and joins. Use of the view implies use of the entire subtree. However, the developer using the view often needs only a few of the view columns and could skip a number of the nodes and joins in the view-defining query if she wrote the equivalent query against simple tables. When the application requires all the nodes in the view, the view-using query still might be hitting those nodes redundantly, joining to the same rows of the same underlying tables in multiple hidden contexts. An example of this will follow in Section 7.3.2.2.
Sometimes, view-using queries cannot be expressed simply as equivalent queries against simple tables. Usually, the cases in which the view-using query returns different results from a simple table query are rare corner cases. However, the correct results in the corner cases are usually not the results the view-using query gets! When a view-using query does not decompose well into a simple, perfectly equivalent simple query against tables, performance almost always suffers, and the corner cases that define the view-specific functional behavior are usually wrong. Nevertheless, to fix the performance with an almost equivalent simple query against tables does require at least a slight change in functionality, and you must exercise caution not to introduce a bug. (You will more often than not be fixing a bug, rather than creating one, but the new bugs will be noticed more!) An example of this will follow in Section 7.3.2.1.
7.3.1 Diagramming View-Using Queries
Diagramming view-using queries is relatively straightforward, though sometimes tedious:
Create a diagram of each view-defining query as if it were a standalone query. Each query diagram that defines a view should be normal, in the sense that it has a single root detail table and has only downward-hanging many-to-one joins from that top node, in a tree structure. If a view-defining query does not map to a normal query skeleton, the queries that use the view will most likely perform badly and return incorrect results. Treat the primary key of the root detail table for the view-defining query as the virtual primary key of the whole view.
Create a query diagram of the view-using query as if each view were just a simple table. A join to a view should have an arrow on the view end (and you should place the view on the lower end of the link) only if the join is to the virtual primary key of the view. Show filter conditions on the view in the view-using query symbolically, as the letter F, without bothering to work out the filter ratio yet. Draw a dotted circle around each view node.
Expand the view-using query diagram of Step 2, replacing each node that represents a view with the entire view-defining query diagram from Step 1 with a dotted curve around the view-defining query subtree. Any join from above will attach to the view-defining subtree at its root detail node. Joins that reach downward from the view can attach to any node of the view, depending on which table of the view-defining query provided the foreign key (in the view-defining SELECT list) of the join. Any filter condition on the view becomes a filter condition on the appropriate node of the view-defining query, depending on which node's column the filter condition restricts. Work out the actual filter ratio for each of these conditions in the usual way (expanding the symbolic F in the initial query diagram). As needed, combine filter ratios from the view-defining queries and from the view-using queries, when these two queries place distinct filters on the same nodes.
These rules probably strike you as abstract and complex, but an example should make the process much clearer. Consider these two view definitions:
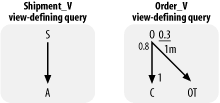
CREATE VIEW Shipment_V AS
SELECT A.Address_ID Shipment_Address_ID, A.Street_Addr_Line1
Shipment_Street_Address_Line1, A.Street_Addr_Line2
Shipment_Street_Address_Line2, A.City_Name Shipment_City_Name,
A.State_Abbreviation Shipment_State, A.ZIP_Code Shipment_ZIP,
S.Shipment_Date, S.Shipment_ID
FROM Shipments S, Addresses A
WHERE S.Address_ID = A.Address_ID
CREATE VIEW Recent_Order_V AS
SELECT O.Order_ID, O.Order_Date, O.Customer_ID,
C.Phone_Number Customer_Main_Phone, C.First_Name Customer_First_Name,
C.Last_Name Customer_Last_Name,
C.Address_ID Customer_Address_ID, OT.Text Order_Status
FROM Orders O, Customers C, Code_Translations OT
WHERE O.Customer_ID = C.Customer_ID
AND O.Status_Code = OT.Code
AND OT.Code_Type = 'ORDER_STATUS'
AND O.Order_Date > SYSDATE - 366
Step 1 calls for query diagrams of these two view-defining queries, as shown in Figure 7-33. These query diagrams were created by following the method described in Chapter 5 and using the same filter ratio and join ratio statistics as for the related example shown in Figure 5-5.
Figure 7-33. Query diagrams for the example view-defining queries
The view-using query, then, is:
SELECT OV.Customer_Main_Phone, C.Honorific, OV.Customer_First_Name,
OV.Customer_Last_Name, C.Suffix, OV.Customer_Address_ID,
SV.Shipment_Address_ID, SV.Shipment_Street_Address_Line1,
SV.Shipment_Street_Address_Line2, SV.Shipment_City_Name,
SV.Shipment_State, SV.Shipment_Zip, OD.Deferred_Shipment_Date,
OD.Item_Count, ODT.Text, P.Product_Description, SV.Shipment_Date
FROM Recent_Order_V OV, Order_Details OD, Products P, Shipment_V SV,
Code_Translations ODT, Customers C
WHERE UPPER(OV.Customer_Last_Name) LIKE :last_name||'%'
AND UPPER(OV.Customer_First_Name) LIKE :first_name||'%'
AND OD.Order_ID = OV.Order_ID
AND OV.Customer_ID = C.Customer_ID
AND OD.Product_ID = P.Product_ID(+)
AND OD.Shipment_ID = SV.Shipment_ID(+)
AND OD.Status_Code = ODT.Code
AND ODT.Code_Type = 'ORDER_DETAIL_STATUS'
ORDER BY OV.Customer_ID, OV.Order_ID Desc, SV.Shipment_ID, OD.Order_Detail_ID
Proceeding to Step 2, create the initial query diagram as if the views were simple tables, as shown in Figure 7-34.
Figure 7-34. Unexpanded diagram of the view-using query
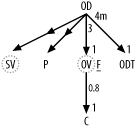
Replace each view node in Figure 7-34 with the earlier query diagrams for the view-defining queries in Figure 7-33, with each view-defining query skeleton surrounded by a dotted curve to show the boundaries of the view. Attach the view-defining query skeletons to the rest of the full query diagram at the appropriate table nodes, depending on which table in the view definition contains the joining key. Normally, any joins into the view from above will be to the root detail table of the view-defining query. However, master-table nodes that hang down from the view (for example, the node labeled C in Figure 7-34) can attach to any node of the view-defining skeleton, depending on which table contains the foreign key that points to that master node. Add explicit, numerical filter ratios to any nodes of the query skeleton that have filters either in the view-defining query or in the view-using query. In Figure 7-34, the filter ratio 0.3 next to node O comes from the filter in the view-defining query, while the filter ratio 0.0002 next to node C comes from the view-using query conditions on the customer's first and last names.
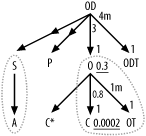
The result for the example should look like Figure 7-35, in which I have added an asterisk to the leftmost C node to clarify the distinction between the two otherwise identically labeled nodes. Again, I borrow the same statistics for the filter on customer name as in the similar example shown earlier in Figure 5-5, to arrive at the filter ratio of 0.0002 next to the C within the rightmost view skeleton.
Figure 7-35. Expanded diagram of the view-using query
This completes the diagram you need to proceed to actual tuning of the view-using query, to determine whether either the view-defining query or the view-using query must change to enable the optimum plan.
7.3.2 Tuning Queries with Views
Normally, the optimum execution plan for the view-using query is exactly the execution plan you would find for the corresponding query diagram against simple tables. However, there are four special problems you might have to resolve:
Some joins to complex views are hard to express precisely as simple joins to simple tables. In particular, outer joins to views that have joins in the view-defining queries are complex to express with simple joins. This problem affects the example, and I will explain it in detail in Section 7.3.2.1.
Some views reference precisely the same rows of the same table as another table in the view-using query, making redundant work for the database that you should eliminate. This happens for the nodes labeled C* and C in Figure 7-35, and I'll discuss this issue further too.
The virtue of views, from the perspective of development simplicity, is hiding complexity, but this very virtue makes it all too easy to code redundant joins that would be obvious, and would actually require more work to code, if developers used only simple tables.
Nodes within view-defining queries, and the joins to reach them, are often unnecessary to the required view-using query result.
Using views limits your ability to fully control the execution plan. If you change a view-defining query to improve the execution plan of a view-using query, you might unintentionally harm performance of other queries that use the same view. You can always create a new view just for the use of a single query, but that defeats the code-sharing advantage of views. In general, SQL hints and other changes in the view-using query cannot control how the database accesses tables in the view-defining query. You sometimes must eliminate the use of views to get the execution plan you need.
7.3.2.1 Outer joins to views
Returning to the earlier example, consider what it means to have an outer join to the view Shipment_V, which itself is an inner join between tables Shipments and Addresses. Since the database must behave as if there were a real table with precisely the rows the view would find, the join finds the inner case for Shipment_IDs that exist in Shipments and point to shipments that have an Address_ID that successfully joins to Addresses. When the database cannot successfully join to both Shipments and Addresses, the join to the view is entirely an outer join (to both tables), even if the initial join to Shipments could succeed. When searching for a nested-loops plan, the database cannot know whether the outer join finds the inner case until it joins successfully to both tables in the view-defining query.
Unfortunately, this is all too complex for most automated code to handle, so your database might simply give up on a nested-loops plan. Instead, the database code recognizes that no matter how complex the underlying logic might be, it cannot go wrong functionally if, in tricky cases like this, it gets every row from the view-defining query and treats the result like a real table. For the outer join to the view, the database normally performs a sort-merge join or a hash join to that temporarily created table. This is safe enough functionally, but it is usually a disaster for performance, unless the view-defining query is fast as a standalone query.
|
Similar problems result for all sorts of joins into views that have UNIONs or GROUP BYs in the view-defining queries. However, joining from these views, when they contain the table you would choose as the driving table of the query, usually works fine.
Consider, again, the view-using query from the previous subsection. If you merge the view-defining query for Shipment_V into the view-using query, to resolve the performance problem with the outer join, you might expect this result:
SELECT OV.Customer_Main_Phone, C.Honorific, OV.Customer_First_Name,
OV.Customer_Last_Name, C.Suffix, OV.Customer_Address_ID,
A.Address_ID Shipment_Address_ID,
A.Street_Addr_Line1 Shipment_Street_Address_Line1,
A.Street_Addr_Line2 Shipment_Street_Address_Line2,
A.City_Name Shipment_City_Name, A.State_Abbreviation Shipment_State,
A.ZIP_Code Shipment_ZIP, OD.Deferred_Ship_Date, OD.Item_Count,
ODT.Text, P.Prod_Description, S.Shipment_Date
FROM Recent_Order_V OV, Order_Details OD, Products P, Shipments S,
Addresses A, Code_Translations ODT, Customers C
WHERE UPPER(OV.Customer_Last_Name) LIKE :last_name||'%'
AND UPPER(OV.Customer_First_Name) LIKE :first_name||'%'
AND OD.Order_ID = OV.Order_ID
AND OV.Customer_ID = C.Customer_ID
AND OD.Product_ID = P.Product_ID(+)
AND OD.Shipment_ID = S.Shipment_ID(+)
AND S.Address_ID = A.Address_ID(+)
AND OD.Status_Code = ODT.Code
AND ODT.Code_Type = 'ORDER_DETAIL_STATUS'
ORDER BY OV.Customer_ID, OV.Order_ID Desc, S.Shipment_ID, OD.Order_Detail_ID
Unfortunately, this does not produce quite the same result as the original query, because of the peculiarity of the outer join to the view. Specifically, the original query returns a null Shipment_Date from the view whenever the entire view, including the join to Addresses, fails to join to Order_Details. Therefore, whenever the shipment does not have a valid, nonnull Address_ID, the original query returns null for Shipment_Date, even though the join to Shipments, by itself, is valid.
Almost certainly, this peculiar behavior is not what the developer intended and is not functionally necessary, so the form just shown will likely work fine, even better than the original in this corner case. However, any change in functionality, for a performance fix, is dangerous. Therefore, before making a change such as the one just described that merges the view-defining query into the main SQL statement, make certain the new corner-case behavior is correct and warn developers that the change might cause regression tests to return changed results. In the unlikely event that you really need the original behavior, or if you just want to play safe without investigating whether the original corner-case behavior was correct, you can perfectly emulate the original query functionality with this:
SELECT OV.Customer_Main_Phone, C.Honorific, OV.Customer_First_Name,
OV.Customer_Last_Name, C.Suffix, OV.Customer_Address_ID,
A.Address_ID Shipment_Address_ID,
A.Street_Addr_Line1 Shipment_Street_Address_Line1,
A.Street_Addr_Line2 Shipment_Street_Address_Line2,
A.City_Name Shipment_City_Name, A.State_Abbreviation Shipment_State,
A.ZIP_Code Shipment_ZIP, OD.Deferred_Ship_Date, OD.Item_Count,
ODT.Text, P.Prod_Description,
DECODE(A.Address_ID, NULL, TO_DATE(NULL),
S.Shipment_Date) Shipment_Date
FROM Recent_Order_V OV, Order_Details OD, Products P, Shipments S,
Addresses A, Code_Translations ODT, Customers C
WHERE UPPER(OV.Customer_Last_Name) LIKE :last_name||'%'
AND UPPER(OV.Customer_First_Name) LIKE :first_name||'%'
AND OD.Order_ID = OV.Order_ID
AND OV.Customer_ID = C.Customer_ID
AND OD.Product_ID = P.Product_ID(+)
AND OD.Shipment_ID = S.Shipment_ID(+)
AND S.Address_ID = A.Address_ID(+)
AND OD.Status_Code = ODT.Code
AND ODT.Code_Type = 'ORDER_DETAIL_STATUS'
ORDER BY OV.Customer_ID, OV.Order_ID Desc,
DECODE(A.Address_ID, NULL, TO_NUMBER(NULL), S.Shipment_ID),
OD.Order_Detail_ID
This query includes two changes that cause the query to return results as if the join to Shipments produced the outer case whenever the join to Addresses produced the outer case. Without the view, the query will treat the join to Shipments independently from the join to Addresses. However, the DECODE expressions in both the end of the SELECT list and the middle of the ORDER BY list cause the inner case of the first join to emulate the outer case of the join (producing NULL in place of Shipment_Date and Shipment_ID) whenever the join to Addresses finds the outer case.
Occasionally, you will have some functional need to use a view in place of simple tables. The most common reason for this is to work around limitations in autogenerated SQL. Functionally, you might require some bit of complex SQL syntax that the SQL generator cannot handle. The common workaround is to bury that complexity in a view-defining query that you create manually and have the SQL generator simply treat the view as if it were a simple table, hiding the complexity from the SQL-generator code. In these cases, you might not be able to eliminate use of a view, such as I suggest in the earlier solutions. Your alternate approach is to extend use of the view, burying more of the SQL in the view definition. For example, since the previous problem involved an outer join to a view, you could solve the problem by pulling the outer join into the view-defining query. With this solution, you would replace use of Shipment_V with OrderDetail_V, using this view-defining query:
CREATE VIEW Order_Detail_V AS
SELECT A.Address_ID Shipment_Address_ID,
A.Street_Addr_Line1 Shipment_Street_Address_Line1,
A.Street_Addr_Line2 Shipment_Street_Address_Line2,
A.City_Name Shipment_City_Name, A.State_Abbreviation Shipment_State,
A.ZIP_Code Shipment_ZIP, S.Shipment_Date, S.Shipment_ID,
OD.Deferred_Ship_Date, OD.Item_Count, OD.Order_ID,
OD.Order_Detail_ID, OD.Product_ID, OD.Status_Code
FROM Shipments S, Addresses A, Order_Details OD
WHERE OD.Shipment_ID = S.Shipment_ID(+)
AND S.Address_ID = A.Address_ID(+)
The view-using query, using the extended view, then becomes:
SELECT OV.Customer_Main_Phone, C.Honorific, OV.Customer_First_Name,
OV.Customer_Last_Name, C.Suffix, OV.Customer_Address_ID,
ODV.Shipment_Address_ID, ODV.Shipment_Street_Address_Line1,
ODV.Shipment_Street_Address_Line2, ODV.Shipment_City_Name,
ODV.Shipment_State, ODV.Shipment_Zip, ODV.Deferred_Ship_Date,
ODV.Item_Count, ODT.Text, P.Prod_Description, ODV.Shipment_Date
FROM Recent_Order_V OV, Order_Detail_V ODV, Products P,
Code_Translations ODT, Customers C
WHERE UPPER(OV.Customer_Last_Name) LIKE :last_name||'%'
AND UPPER(OV.Customer_First_Name) LIKE :first_name||'%'
AND ODV.Order_ID = OV.Order_ID
AND OV.Customer_ID = C.Customer_ID
AND ODV.Product_ID = P.Product_ID(+)
AND ODV.Status_Code = ODT.Code
AND ODT.Code_Type = 'ORDER_DETAIL_STATUS'
ORDER BY OV.Customer_ID, OV.Order_ID Desc, ODV.Shipment_ID, ODV.Order_Detail_ID
7.3.2.2 Redundant reads in view-using queries
Now, consider the case of the joins in Figure 7-35 to nodes labeled C* and C. These nodes represent the same table, with identical join clauses, so any execution plan that hits both nodes is redundant, reading the same table rows and probably the same index entries twice. The second, redundant read in every case should avoid physical I/O, because the first read, likely less than a millisecond earlier, should place the table or index block safely at the head of the shared cache. If the execution plan is highly filtered before it reaches the second, redundant node, the excess logical I/Os might be negligible, but for large queries or queries that filter most rows only after such redundant reads, the costs of the extra logical I/Os are important.
If the developer wrote the query originally against simple tables, this sort of error would be unlikely; he would have to go out of his way to include the redundant join, and the redundancy would be obvious in code review. With views, however, these errors are easy to make and are well hidden.
How do you fix the redundant join to Customers? You have three options:
Add new columns as needed to the SELECT list of the view-defining query and use them in place of the column references to the redundant table in the view-using query. This is safe for other queries that use the same view, since it only adds columns and does not change the view-defining query diagram.
Eliminate the redundant join from the view-defining query and use only the columns from the simple table node in the view-using query. However, this is dangerous if there are other view-using queries that might require the view columns you eliminated.
Eliminate the use of the view from the view-using query, replacing it with equivalent, nonredundant joins to simple tables.
7.3.2.3 Unnecessary nodes and joins
Consider the join to node OT in the recent view-using query. The original view-defining query appears to include that join to support queries of the order status, but the view-using query does not even refer to the order status, so you might question whether this node is necessary. If you did not happen to notice the seemingly unused node, you could diagnose the unused node if you noticed a join, in the execution plan, to the primary-key index of this table with no read of the table itself. Such index-only reads of primary-key indexes usually point to unnecessary joins.
Safely eliminating these unnecessary joins is not simple, because they sometimes have functional side effects. Since this is an inner join, it is at least possible that, even with no filter on the node, the join itself eliminates rows the query should not return. This can result either by eliminating rows where Orders.Status_Code IS NULL or where Status_Code points to invalid status codes that fail to find a match in the Code_Translations table. The latter possibility is unlikely or should be eliminated by repairing referential integrity. However, null foreign keys are common, and if the column can be null, you should consider adding an explicit Status_Code IS NOT NULL condition before eliminating the join, to emulate the implicit filtering function of the inner join. More likely, the developer using the view did not even think about the implicit filtering function of the view, and the implicit filter was entirely unintentional and undesirable. Therefore, before emulating the old behavior in a base-table-only query that eliminates the unneeded join, check whether the old behavior was even correct. If your change will subtly change behavior, even for the better, warn testers that regression test results might change for this corner case.






