8.3 Choosing the Next Table to Join
After you choose the driving table, the rest of the decisions for a robust execution plan consist of a series of choices amounting to "What's next?" When you ask this question, you have, effectively, a single cloud of already-joined nodes that you chose earlier in the join order and a series of nodes linked to that cloud that are eligible for the next join. If the query diagram is a typical tree structure, at most one node will be upward from the current cloud, and any number of nodes can be reachable downward. Figure 8-6 illustrates this typical case.
Figure 8-6. A typical decision point during join-order optimization
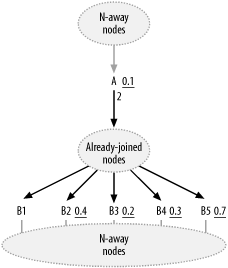
Consider the question "What's next?" for this point in the join order. The database has reached some number of rows, which I will call N. Joins to tables downward of the current join cloud will multiply the running rowcount by some fraction: the filter ratio times the master join ratio. Let F=R x M, where R is the filter ratio and M is the master join ratio (which is 1.0, unless shown otherwise). The larger the reduction in rows, which is 1-F, the lower the cost of the future joins, so nodes with high values of 1-F have high value to optimizing the rest of the query, when joined early. That reduction in rowcount has a cost too, based on the cost per row driving into the join, which I will call C. The benefit-to-cost ratio of a downward join under consideration is then (1-F)/C. If you assume a uniform cost per row read for all tables downward of the already-joined nodes, choosing the downstream node with the maximum value of (1-F)/C is the same as choosing the node with the minimum value of F.
How could this optimization be refined further? There are three opportunities for improvements, all reflected in Section 6.6 in Chapter 6:
Not all downstream nodes have equal cost per row joined, so C really does vary between nodes.
The full payoff for a join is sometimes not immediate, but comes after joining to nodes further downstream made accessible through that intermediate join.
Sometimes, the upstream node actually offers the best benefit-to-cost ratio, even while downstream nodes remain.
I will discuss these improvement opportunities one at a time to illustrate how they create the special rules that occasionally override the simpler rules of thumb.
8.3.1 Accounting for Unequal Per-Row Costs
Downstream nodes are nearly guaranteed to be smaller than the largest table already reached in the execution plan. As such, they are generally better cached and unlikely to have deeper indexes than the largest table already reached, so their impact on overall cost is typically minor. Even when the costs of reading downstream nodes vary considerably, the performance cost of assuming uniform costs for these nodes usually is minor compared to the overall costs of the query. Nevertheless, the possibility of significant join cost differences justifies the exception already mentioned in Chapter 6:
Prefer to drive to smaller tables earlier, in near-ties. After you choose the driving table, the true benefit-to-cost ratio of joining to the next master table is (1-F)/C. Smaller tables are better cached and tend to have fewer index levels, making C smaller and making the benefit-to-cost ratio tend to be better for smaller tables.
8.3.2 Accounting for Benefits from Later Joins
Occasionally, especially when nodes have no filter at all, the greatest benefit of a join is that it provides access to a further-downstream node that has a good filter. This gives rise to another exception described in Chapter 6:
In the case of near-ties, prefer to drive to tables earlier that allow you to reach other tables with even better filter ratios sooner in the execution plan. The general objective is to discard as many rows as soon in the execution plan as possible. Good (low) filter ratios achieve this well at each step, but you might need to look ahead a bit to nearby filters to see the full benefit of reaching a given node sooner.
A perfect account of these distributed effects of filters spread across nodes is beyond the scope of this book and beyond any optimization method meant for manual implementation. Fortunately, this limitation turns out to be minor; I have never seen a case when such a perfect account was necessary. Almost always, the preceding rough rule delivers a first solution that is optimum or close enough to optimum not to matter. Rarely, a little trial and error is worth trying when a case is right on the borderline. Such rarely needed trial and error is far easier and more accurate than the most elaborate calculations.
8.3.3 When to Choose Early Joins to Upstream Nodes
Upstream nodes can potentially offer the most effective benefit-to-cost ratio. For upstream nodes, you calculate F=R x D, where R is the node's filter ratio, as before, and D is the detail join ratio. However, unlike the master join ratio, which must be less than or equal to 1.0, the detail join ratio can be any positive number and is usually greater than 1.0. When it is large, F is typically greater than 1.0 and the benefit-to-cost ratio, (1-F)/C, is actually negative, making the upward join less attractive than even a completely unfiltered downward join (where 1-F is 0). When F is greater than 1.0, the choice is obvious: postpone the upward join until downward joins are exhausted. Even when the detail join ratio (D) is small enough that F is less than 1.0, an early upward join carries a risk: the detail join ratio might be much larger for other customers who will run the same application, or for the same customer at a later time. The early upward join that helps this one customer today might later, and at other sites, do more harm than good. Upward joins are not robust to changes in the data distribution.
Large detail join ratios carry another, more subtle effect: they point to large tables that will require the database to read multiple rows per joined-from row, making C higher by at least the detail join ratio, just to account for the higher rowcount read. If these upstream tables are particularly large, they will also have much larger values for C (compared to the downstream joins), owing to poorer caching and deeper indexes. Together, these effects usually make C large enough that the benefit-to-cost ratio of an upstream join is poor, even with very low detail-table filter ratios.
In Figure 8-6, the factor (F) for A is 0.2 (0.1 x 2), the same as the best downstream node, B3, but the cost (C) would be at least twice as high as for any downstream node, since the database must read two rows in A for every joined-from row from the already-joined nodes. Setting Cd (the detail-table per-row cost) equal to 2 / Cm (the worst-case per-row cost of a master-table join) gives you (1-0.2)/(2 x Cm) = (1-Fe)/Cm, where Fe is the filter ratio a worst-case downstream join would have if it had a benefit-to-cost ratio equal to the upstream join to A. Solving for Fe, you find 1-Fe=0.8/2, or Fe=0.6. Based on this calculation, you would certainly choose the joins to B3, B4, and B2 before the join to A. Even the join to B5 would likely be best before the join to A, since B5 would likely be better cached and have fewer index levels than A. Only the join to B1 would be safely postponed until after the join to A, if you had confidence that the F factor for A would never exceed 1.0 and you had no further filters available in nodes downstream of B1. By the time you reach a point where the upward join might precede a downward join, it often hardly matters, because by that point there are so few rows left after the earlier filters that the savings are miniscule compared with the costs of the rest of the query. In conclusion, the need even to consider upward joins early, with any detail join ratio of 2 or more, is slight.
However, detail join ratios are sometimes reliably less than 1.0, leading to the simplest exception to the rule that you should not consider upward joins early:
When choosing the next node in a sequence, treat all joins with a join ratio D less than 1.0 like downward joins. And, when comparing nodes, use D x R as the effective node filter ratio, where R is the single-node filter ratio.
When detail join ratios are near 1.0 but not less than 1.0, the case is more ambiguous:
Treat upward joins like downward joins when the join ratio is close to 1.0 and when this allows access to useful filters (low filter ratios) earlier in the execution plan. When in doubt, you can try both alternatives.
The key in this last case is how confident you are in the detail join ratio being close to 1.0. If it might be large later, or at another site, it is best to push the upward join later in the plan, following the simplest heuristic rule that postpones the upward joins until downward joins are complete. (Important exceptions to this rule are surprisingly rare.)






