Oracle Instance Options?Loading
The second key Oracle architectural issue the DBA must determine is how many Oracle instances will form the data warehouse for the purpose of loading data? This definition may seem less clear than the previous one regarding queries, but actually it's a much simpler question: Will the data warehouse data be loaded in one step or two?
There are only two options here (shown in Figure 2-4):
Option 1? Load the data from the source directly into the query tables
Option 2? Load the data from the source into a staging area first, then into the query tables
Figure 2-4. Instance Options for Two Data Loading Paradigms
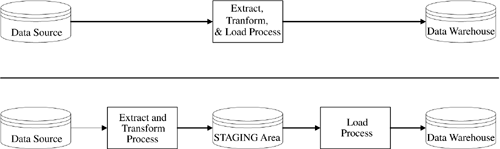
The first method requires direct access to the live data warehouse tables, which very often is quite undesirable. For example, the data load process may involve numerous complex extract, transform, and load (ETL) operations that can consume significantly more time than simply loading the data. Since many data warehouses have very limited batch windows in which to load their data, both the extract and transform operations may need to be performed outside those batch windows. So, it is not uncommon to separate the overall ETL process through the use of a staging area.
Staging tables typically hold up to a few batch cycles' worth of data. For example, a data warehouse fact table might have a billion rows and load 10 million new records per night. Assuming that a batch loading cycle is successfully completed at least once every three days, the staging tables would hold anywhere from 10?30 million rows. Once a batch cycle completes, the staging area tables are simply truncated.
The staging approach offers several interesting advantages. First, the DBA can implement referential integrity (i.e., foreign keys) and other database constraints to enforce the data's accuracy. These constraint mechanisms do not seriously degrade the load time for tables under 100 million rows. This is key since it's easier to define such value checks once in the database rather than expecting each and every program to properly code all such validations.
Second, if the transform or extract process aborts or errors out, the DBA can simply truncate the staging tables and restart the requisite batch jobs. This ability to simply reset and restart is sufficient reason to embrace this method. In essence, it's like having a super-commit or rollback mechanism for the data loading process.
Third, the DBA can better manage disk space allocations. The staging tables are sized for one to N batch cycles' worth of data, whereas the data warehouse fact tables are sized for much longer time intervals (e.g., weekly, monthly, or quarterly). Additionally, only a handful of simpler load programs require access to the actual data warehouse fact tables. The bulk of the more complex extract and transform programs don't access the actual data warehouse fact tables, merely the staging tables.
Finally, the staging approach also offers an extremely wide range of database implementations. Keep in mind that all the options discussed below go hand in hand with your prior database architecture decisions for queries.
Next, there are options to consider if the data warehouse and staging tables will be in the same instance, including (shown in Figure 2-5):
Option 1? DW and STAGING in a single database, with a single instance, on a single server
Option 2? DW and STAGING in a single database, with multiple instances, on a single server
Option 3? DW and STAGING in a single database, with multiple instances, on multiple servers
Figure 2-5. Instance Options for Combined Warehouse and Staging
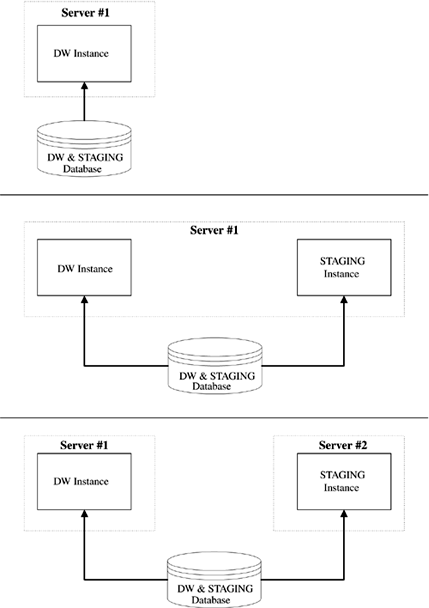
Note that the second option does not make much sense unless you have a very large database server with an OS that supports partitioning of the hardware. Also note that both the second and third options require the use of OPS/RAC.
The first option, combining the data warehouse and staging table access in a single instance accessing a common database on a single database server, offers the greatest simplicity. This is probably the best-known and most widely used Oracle software architecture out there. But, combining such radically different tables in one database instance has some severe tuning drawbacks. How do you best size the INIT.ORA parameters that control the SGA to simultaneously support reporting and data loading needs? You sure don't want to have to shut down and restart the database to change those parameters every time you switch between these needs. And what if these needs overlap? How do you set those parameters to best suit concurrently running reports and loading data, especially when reports are highly affected by database buffer cache hit ratios, and data loads tend to saturate that cache? Thus, loading data while running reports within a single database instance will just make the reports run that much slower. Of course, there is also the issue of sharing other server resources during concurrent report and data load execution, but the decreased database buffer cache hit ratio will be the most noticeable.
The second option, separating the data warehouse and staging table access across multiple instances accessing a common database on a single database server, solves the problems of the first option, but introduces issues of its own. Since many server operating systems limit the total amount of shared memory that can be allocated for the SGA, splitting the database instances would require defining smaller, fixed SGA memory allocations whose cumulative size fits within that limit. For example, some 32-bit operating systems limit the total SGA size to 1.7 GB. So, the DBA might allocate 1.2 GB to the DW SGA and 500 MB to the STAGING SGA. But in effect, that translates to 500 MB of wasted (i.e., lost) memory when reports are running and data loads are not, and, an enormous 1.2 GB of waste when data loads are running and reports are not. Plus, the programs that promote data from the STAGING instance to the DW instance would have to communicate over an Oracle DBLINK, which is not as fast as the inter-instance operations of the first option.
Moreover, all the ETL programs (refer back to Figure 2-4) would have to be designed and deployed correctly. The extract and transform programs should connect to and process against the STAGING instance, period, whereas the load programs should connect to and process against the DW instance while reading data from the STAGING instance via an Oracle DBLINK. Otherwise, two-phase commits (2PCs) will enter the performance equation and slow data loading operations down by orders of magnitude.
The correct SQL to connect to and process against the DW instance while reading data from the STAGING instance via an Oracle DBLINK without 2PCs is:
INSERT INTO WAREHOUSE_TABLE SELECT * FROM STAGING_TABLE@STAGING_INSTANCE
The incorrect SQL to connect to and process against the STAGING instance while writing data to the DW instance via an Oracle DBLINK with 2PCs is:
INSERT INTO WAREHOUSE_TABLE@DW_INSTANCE SELECT * FROM STAGING_TABLE
The third option, separating the data warehouse and staging table access across multiple instances accessing a common database across multiple database servers, solves the OS limits for shared memory problem, but requires two or more servers and increases network traffic between them. The primary advantage is that both the DW and STAGING servers' capacity can be selected to best match their respective roles. However, in the long run, buying two smaller servers will generally cost more than buying one larger server with the same overall capacity. Furthermore, the network connections between those servers should be ultra-high?speed, and preferably dedicated.
There are yet more options if the data warehouse and staging tables will be separate instances, including (shown in Figure 2-6):
Option 1? DW and STAGING in separate databases, with multiple instances, on a single server
Option 2? DW and STAGING in separate databases, with multiple instances, on multiple servers
Figure 2-6. Instance Options for Separate Warehouse and Staging
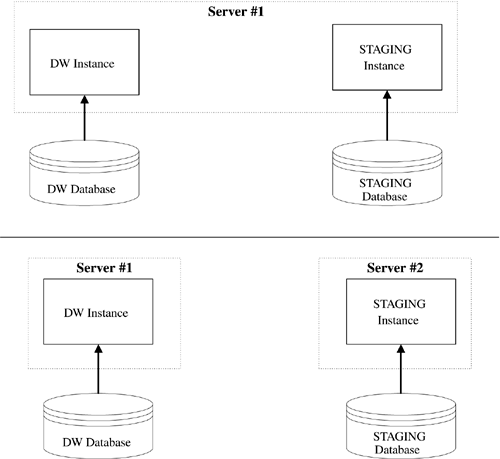
Note that the first option does not make much sense unless you have a very large database server with an OS that supports partitioning of the hardware.
The first option in Figure 2-6 is similar to the second option in Figure 2-5, but it does not require the use of OPS/RAC. It too suffers from the limited shared memory allocation among multiple SGAs problem. Likewise, this method also requires proper coding and execution of the ETL code to eliminate 2PCs.
The second option in Figure 2-6 is similar to the third option in Figure 2-5, but it does not require the use of OPS/RAC. It too requires buying more than one server, which may cost more than a single server with sufficient capacity. Likewise, it too requires the network connection between the servers to be ultra-high?speed, and preferably dedicated.







