The Serial vs. Parallel Programming Debate
The final software architectural issue concerns ETL program execution models. Will the data loading processes be done serially or in parallel? This is probably one of the most overlooked architectural issues in data warehousing.
It's been over 10 years since I've worked on a uniprocessor database server. The typical database server generally has four to six CPUs, and the typical data warehouse server even more. So the question of serial versus parallel program design is warranted.
In reality, the loading program's design is the key factor for the fastest possible data loads into any large-scale data warehouse. Data loading programs must be designed to utilize SMP/MPP architectures, otherwise CPU usage may not exceed 1/No. of CPUs. The Golden Rules are very simple:
Minimize inter-process wait states.
Maximize total concurrent CPU usage.
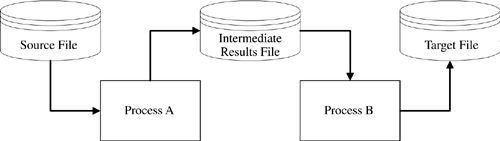
For example, suppose you have a file with 1000 records and each must pass though Process A and then Process B. Each process takes one unit of time to process a record. If the program design is purely serial, as in Figure 2-7, then the total runtime is roughly 2000 units of time. The problem is that Process B cannot start until after Process A has completed. Unfortunately, this is the way most programmers write code.
Figure 2-7. Serial ETL Processing with Wait States
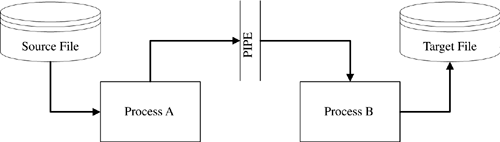
To eliminate the inter-process wait time, we can replace the temporary file with a pipe. Pipes are supported by most operating systems, including UNIX/Linux and NT. The program design now looks like Figure 2-8, with a total runtime of roughly 1001 units (there is a one-unit time lag for the very first record to be completely processed through the pipe). This represents a nearly 100% improvement over the original serial solution.
Figure 2-8. Basic Parallel ETL Processing via Pipes
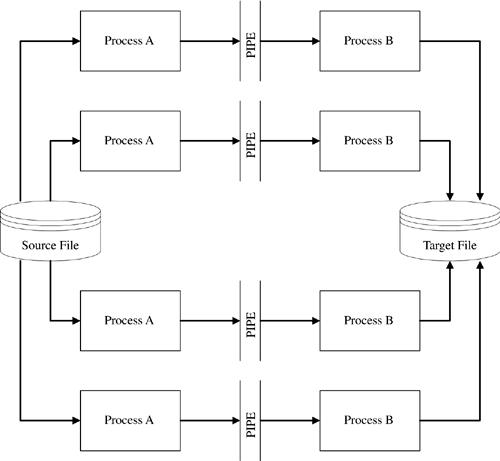
To maximize CPU usage, we can fork multiple A/B process pairs to divide and conquer the 1000 records. Each process pair would handle 1/N records, where N is the number of CPUs. If we assume four CPUs, then the picture would look like Figure 2-9, with a total runtime of roughly 251 units (there is a one-unit time lag for the very first record to be completely processed through the pipe). This represents a nearly 700% improvement over the original serial solution. This technique should be the standard for most data warehouse programming efforts.
Figure 2-9. True Parallel EFL Processing via Forking
Let me give you a real-world example of just how big a difference this kind of software architectural issue can make. And don't laugh at how silly this example sounds. It really happened this way on my 7-Eleven data warehouse.
We had a nightly batch window of about eight hours to run all our data warehouse ETL jobs. At some point, just one of our jobs started to take 4.5 hours to run, so we could no longer complete our load cycle within the time allowed. At the time, our hardware included:
8 400MHz 64-bit CPUs
4 GB RAM
2 GB EMC cache
RAID-5
Rather than listen to the DBA and effect a software redesign, management decided to upgrade the hardware. They felt that this would provide an immediate and measurable payback. Plus, it was very easy to manage?one down weekend to install all the upgrades. And they sold the customer on it. So we upgraded to:
16 400MHz 64-bit CPUs
8 GB RAM
4 GB EMC cache (this was the most expensive item)
RAID 0+1 (faster writes at cost of doubling the number of disks)
All that hardware cost nearly a million dollars, and all we got was a 15-minute improvement! In the long term, our data warehouse was scaling up in terms of concurrent users and queries per day, so the money really was not wasted. We merely ended up ordering some necessary hardware upgrades a few months earlier than necessary or planned.
After that fiasco, management authorized me to redesign the ETL process. So, I merely applied the Golden Rules: Minimize inter-process wait states and maximize total concurrent CPU usage. I first converted the existing program to "divide and conquer" the input data into 16 concurrent streams, with each stream feeding an instantiation of the program. I modified the job to not wait for any step to complete before starting a subsequent step.
In terms of hours, this was a dirt-cheap fix. The time spent was merely 30 minutes for some simple UNIX shell scripting changes and a few hours of time to modify the program and job schedule. The result was a total runtime of 20 minutes. Finally, I made one last tuning modification using Dynamic SQL Method 2: prepare and execute. The result was a total runtime of 15 minutes. We estimated the costs in terms of time at $2600, yielding 17 times the throughput at 385 times less than the costs of the hardware upgrades! I got my bonus that quarter.







