The Need for Logical Volume Managers
There are two ways to implement RAID within disk arrays. Hardware, or controller-based, RAID is implemented via firmware in the disk array. Software, or host-based, RAID is implemented via software on the host server. Of course, you can combine the two methods as well.
While it may seem that RAID via hardware would be preferable, there are some drawbacks. Often this approach requires a one-time, static configuration. If the DBA guesses wrong or if the application I/O patterns change over time, the only solution is to back up the data, reconfigure the array, and reload the data. For a multi-terabyte data warehouse, this exercise could take an entire weekend! Another issue is that different RAID configurations often cannot be mixed and matched on the same disk drive (i.e., either RAID 0+1 or RAID 5, but not both on a given disk drive). Finally, many controller-based RAID solutions offer limited tools to trace I/O patterns and gather the statistics necessary to analyze them to plan for successful reconfigurations.
Although software-based RAID will require host CPU cycles and increased I/O bus traffic, the advantages are very compelling. Host-based RAID offers just plain superior flexibility in terms of configuration. The process is not one-time, but ongoing, and it does not require backups and reloads to make changes. You also can freely mix and match RAID configurations on entire disk drives or portions of drives. For example, you could create RAID0+1 space for loading current data and RAID 5 space for loading non-current (i.e., read-only) data, with each configuration spread equally across all disk drives. Plus, software RAID generally offers very useful tools for monitoring and tuning disk space configurations. And, some vendors offer automated tools for finding and removing hot spots.
While most UNIX vendors provide a free logical volume manager (LVM) with the OS, you get what you pay for. I highly recommend a third-party vendor's LVM such as Veritas' Volume Manager. If you've adopted the Veritas file system for its Quick IO feature (see prior section on raw files), then you really should consider using their LVM as well.
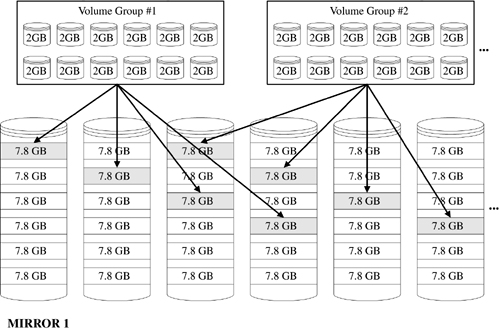
So just how does the combination work? Most disk arrays first split spindles (i.e., disks) into partitions, often referred to as meta- or hyper-devices. These meta-devices are then the devices that the disk array presents to the UNIX OS. For example, if we had:
64 47GB disk drives (3 terabytes in total)
Hardware-based mirroring (1.5 terabytes usable)
6-way split of disks into 192 7.8GB meta-devices
LVM stripe size of 64K
LVM stripe set size of 4 meta-devices per volume group
12 2GB data files per volume group
48 total volume groups (1.15 terabytes accessible)
The picture would look something like Figure 3-9.
Figure 3-9. Example Logical Volume Manager Layout