Avoid Snowflakes
Look again at the dimensions in Figure 4-1. These three tables are clearly denormalized (i.e., in zero normal form), as they should be. But DBA instincts being what they are, far too often mistakenly attempt to normalize star schema designs. In effect, they try to apply OLTP logic to their data warehouse. In data warehousing parlance, such forced normalization attempts are called snowflakes. Let's look at a snowflake example to avoid.
First, the PRODUCT dimension clearly violates third normal form (i.e., a non-key column depends on another non-key column) in three places:
MFG_NAME depends entirely on MFG_CODE.
CATEGORY_NAME depends entirely on CATGEORY_CODE.
SUBCATEGORY_NAME depends entirely on SUBCATEGORY_CODE.
Likewise, the LOCATION dimension also violates third normal form in two places:
MARKET_NAME depends entirely on MARKET_CODE.
DIVISION_NAME depends entirely on DIVISION_NAME.
Finally, the LOCATION dimension also violates first normal form (i.e., no column is an array or repeats groups of values) in two places:
ADDRESS_LINE1
ADDRESS_LINE2
This clearly represents an array of address lines, which is a repeating group. So what you end up with is a model that is in zero normal form. Remember, normal forms are cumulative, meaning you cannot be in one normal form if you violate its predecessor. Therefore, if you've violated first normal form, you cannot be at any higher normalization level.
When you apply OLTP skills to star schemas, you end up with a model like that shown in Figure 4-2.
Figure 4-2. Snowflaked Dimensional Entity Relationship Model
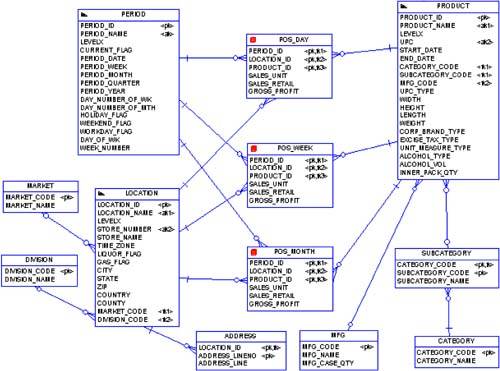
So what does Figure 4-2 accomplish? The data model has been normalized, thus the resulting database will save a few bytes of inexpensive disk space. The problem is that the ad-hoc user queries will now take forever to run. The key problem is that by adding all these snowflake tables, the Oracle optimizer is confused into thinking this is in fact an OLTP database and not a star schema. This is a waste of disk space. Had space been saved in a fact table, then it's probably a worthwhile endeavor. But the dimension tables are relatively small, so saving space here at the expense of the extra joins and confusing the Oracle optimizer is not advisable.
Of course, someone will inevitably ask, "Why can't I build the database like Figure 4-2 and then just simply create view definitions to reassemble the snowflaked dimensions?" The short answer is because it doesn't work. A view definition is really nothing more than a pre-canned query. So, that pre-canned query is extrapolated and merged into your query at runtime. Thus, the view only hides the design from the user?not the optimizer. So, you end up with queries that the optimizer cannot handle utilizing Oracle's latest and greatest star schema features. In other words, the query takes forever to run.
To recap, snowflakes are bad because they:
Add additional levels of JOIN complexity (i.e., add more tables to JOIN).
Complicate end-user query construction as there are now more tables to choose from, unless view definitions are used to combine multiple tables into singular, flat objects from which to select.
Are mishandled as OLTP data by the Oracle query optimizer (i.e., bad explain plan).
Save a little cheap disk space at the cost of much longer query runtimes.







