Method 2: Load, Then Transform
After the lengthy discussion regarding the transform, then load scenarios, a logical question is why would anyone choose load, then transform? There's really no great answer here that will universally justify this approach, but I can give some specific examples where I've seen it done, and with good reason in those particular instances.
If you need complex data transformations, you might decide to separate that logic from the basic data loading processes for developer resource allocation reasons. For example, you could have your junior team members write the loading jobs and your senior people write the complex data transformation jobs. By artificially separating these tasks, you can better allocate your developer resources. I've worked on projects where this was the case. It's a sound project management reason to adopt a load, then transform approach. I do, however, feel that Oracle 9i's advanced features make this less of an option than it was in the past. But, only you know your team's makeup and capabilities.
If you have a business requirement that your data loading jobs must be able to handle cumulative amounts of data, you might decide to separate the loading process from the data transformation logic so that you can still perform some work on those days when the loads are not promoted to your fact tables. Let me explain. Let's say that you have a nightly ETL process that updates your fact tables. However, on occasion (for legitimate business or technical reasons), you may need to collect the raw data for loading, but not promote that data to the fact tables until some later batch cycle run. Rather than just accumulating those files and having to process them all at once, it might be preferable to create a staging area in the database to accumulate that raw data. Then you could very easily perform just the transformation logic whenever it is permitted. This is probably the soundest reason I've seen for adopting a load, then transform approach.
But, the most common reason I run into is that the data warehouse was built before some of these features were available so the existing ETL code uses the historically popular choice of load, then transform. Moreover, new ETL jobs are written to conform to the exiting architecture, so the data warehouse does not evolve into a more modern approach. The guiding principal at these sites seems to be "If it ain't broke, don't fix it." They are more than content with this approach, and are willing to spend hardware dollars to stand pat. I even think some of these people would do it over the exact same way, meaning I'm not sure they know that other ways exist. For whatever reason, they're convinced that not only does it work, but it must be good since it was done that way. Unlike the previous two examples, I cannot say that this is a legitimate reason to adopt or maintain this approach.
So let's assume that for whatever reason, you are going to be working in a load, then transform paradigm; what are your implementation choices? For once, I have an easy answer. To load raw data into your staging tables, SQL Loader is the only way to go. It offers sufficient cleansing, trivial data transformations, performance, and ease of use as benefits to make all other choices irrelevant. And for promoting your staged data to your fact tables, SQL should be your first choice?with PL/SQL as your fallback. The architecture looks like Figure 6-5.
Figure 6-5. Using SQL Loader and PL/SQL to Load the Warehouse
![]()
The reason I say SQL first is for its set-oriented approach and parallel DML capabilities. Too often, developers fall into a PL/SQL rut of open cursor, loop though records till end of cursor, and perform operations on each record in the loop iteration. It reminds me of people doing file I/O programs, where they open file, read record, etc. You cannot load and transform tens to hundreds of millions of rows with such a limited and outdated programming approach. Compare the next two snippets of code:
-- SQL using parallel DML and direct mode loads
alter session enable parallel dml;
insert /*+ parallel(f,10) append */ into fact f
select /*+ parallel(s,10) full(s) */ * from staging_table s;
-- PL/SQL record-oriented cursor for loop
-- with a commit after every 100 records
commit_ctr := 0;
for rec in (select * from staging_table) loop
insert into fact values (rec.c1, ... rec.cN);
commit_ctr := commit_ctr + 1;
if (commit_ctr >= 100) then
commit_ctr := 0;
commit;
end if;
end loop;
The first snippet utilizes multiple CPUs and pushes both your CPU and I/O bandwidth consumptions to their limits. The second snippet uses one CPU and makes minimal resource requests overall. It just does not get it, so don't pick it.
So assuming that you have a legitimate reason to go this way, our optimally efficient load, then transform implementation options are (shown in Figure 6-6).
Figure 6-6. "Load Then Transform" Implementation Options
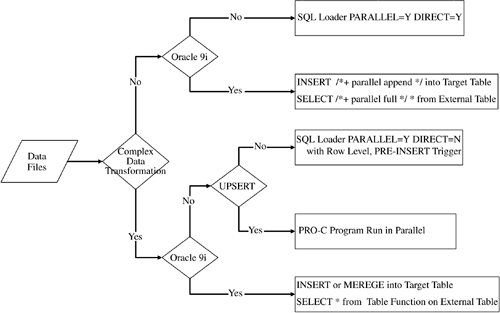
Looks a bit like Figure 6-4, which depicts our options for transform, then load, doesn't it? You should not be too surprised. On some of the choices, we merely had to change the word "External" to "Staging" (referring to the source table). Plus, all these approaches are entirely within the database (i.e., they copy data from one table to another). Most Oracle developers have little or no problems grasping such operations since they've been doing this kind of stuff since Day One. Of course it's this familiarity that too often has people choosing the load, then transform approach. I'm not going to detail the implementation choices in Figure 6-6 any further. The techniques are simple, and if you read the previous section, you already have code that is 90% of what you need for these implementation choices.







