Upstream Source Data
This is probably one of the easiest areas to explain. The majority of the time, your data warehouse source data will simply be files. Why files, you might ask, when all our applications are in relational databases? The reason is simple: 90% of the upstream OLTP application production support teams are not going to permit an external team (such as a data warehousing team) to write and schedule code to run against their production application. Why? Because if your code drags their system to its knees or blows apart their job schedule, then they get paged and will face any associated customer grief, not you. So they will provide you with files to meet whatever specifications you provide, but they will write the code and schedule it, not you. That's just how it's done in large shops with lots of controls.
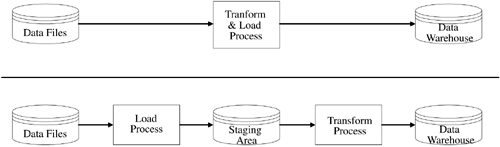
Thus, we can adjust Figure 6-1 to look like Figure 6-3, where we removed the extraction concept and used data files as our data source. The approach names, transform, then load and load, then transform, probably now make more sense.
Figure 6-3. File Based Source Means Simply Transform and Load
Of course there are exceptions to every rule. In some cases, you may be the DBA for both the OLTP and data warehouse applications. Or, your shop may not have as many controls. You might even have exceptional DBAs who coordinate their activities and share some of their responsibilities. If so, then you're very lucky. Every data warehouse I've worked on has been a separate team. As such, we've always had to document for other teams what output we needed from their systems and then lived with whatever schedule they dictated for execution and delivery. Don't fret or fight it; it's just a normal control condition for successfully managing large-scale production applications.
The major problem you run into here is with scheduling. If the upstream applications cannot produce your necessary source data in time for you to process it before your data warehouse must come online, then you may have to process that data a day late. In other words, your data warehouse may be 24?48 hours behind the production OLTP systems' data. Take time to clearly explain this to the business sponsor; it should not be an issue. Remember, the data warehouse is used for strategic purposes, and a day or two behind should not impact truly long-term or strategic reporting/planning.
However, if the sponsoring user won't budge, then you'll have to open the warehouse later (i.e., whenever you can complete the data loads for the source data that arrives the latest). It may even be that you open portions of the warehouse at different times based on this. For example, order data may come online in the warehouse at 7:00 a.m., while sales data may not come online until 9:00 a.m. I've even done data warehouses where the data is always online, but is switched over to the most current day's load at 9:00 a.m. This lets the users do work, but they know that they will not have the previous day's data available until 9:00 a.m. The point is to be creative; when you get down to it, a data warehouse is really nothing more than a glorified reporting system. While it might be important to both high-level managers and executives, the organization can still book business via its OLTP systems. But, these people should be flexible when it comes to providing a platform from which to make truly strategic decisions.
I'm going to present the various data loading architecture implementations assuming a data source of files. The translation for these example implementations to instead use database tables as their data source (which should be quite simple and straightforward) is left to the reader as an exercise.







