Loading Architecture
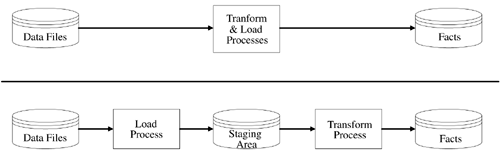
Remember, there are two data loading architectures for fact tables: transform, then load and load, then transform (see Figure 7-1).
Figure 7-1. Common Data Warehouse ETL Architectures
The same data loading architecture options exist for loading aggregates; however, each of these scenarios becomes a bit more complex (Figures 7-2 and 7-3) as they add aggregation processes and aggregate tables to the flow. Plus, selecting an approach may limit your actual implementation options (e.g., does that approach work with materialized views?). You should review these options in detail and choose carefully.
Figure 7-2. "Transform Then Load" Aggregation Options
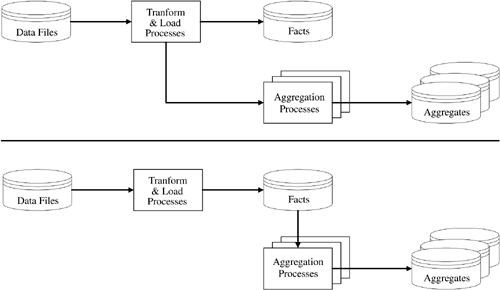
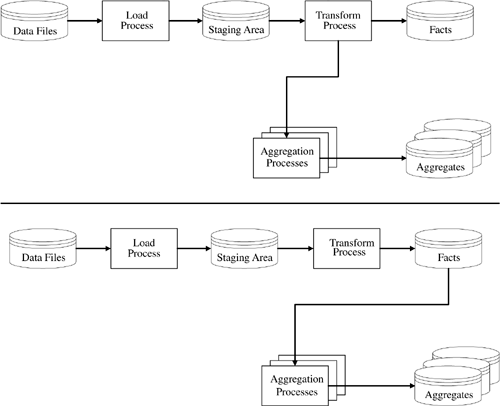
Figure 7-3. "Load Then Transform" Aggregation Options
The transform, then load architecture offers two options for including aggregates, as shown in Figure 7-2:
The first option requires the transform and load program code to implement two distinct functions: the fact table transform and load, plus the aggregation for each aggregate. Although this can be accomplished via a single program that reads all the data once with no inter-process waits, that program will be significantly more complicated because it has to include logic for each target aggregate. This poses substantial project management risk as a single change to that one program could break the process for the fact and all its aggregates. Of course, you could implement each of the aggregate processes separately and feed them off the transform, then load approach via concurrent pipes, with commands like:
transform_then_load | tee aggregation_1 | tee aggregation_2 ... > aggregation_N
However, note this first option does not lend itself to a materialized view implementation. While you could create the aggregates as materialized views and possibly utilize query rewrites, you would not be able to use the refresh mechanism, as refresh must be based on a table with a primary key. Even if the data files were accessed via external tables, you still could not do a refresh, as external tables also do not have primary keys. This is another drawback to this approach.
The second option separates the base fact and aggregate load logic. So, you don't have the project management nightmares related to having a single point of failure. In fact, you can implement each aggregation on its own, which is a natural fit for implementing via materialized views with refreshes (assuming that the aggregation processes will perform only inserts, as refresh does not yet support the MERGE command). This option also has the added benefit of subdividing the tasks into more manageable and less complex pieces for developer resource allocation and batch job scheduling.
However, there are two drawbacks to this second option. First, you'll have to read the base fact table information at least twice (i.e., once to load it from the data files and a second time to summarize it). In fact, if you implement each of the aggregation processes separately, you'll then have to read the base fact table information N+1 times (where N represents the distinct number of aggregates based on that base fact table). Second, this option introduces an inter-process wait since you cannot load any of the aggregates until the fact has completed its data load. Nonetheless, you should view the second option as preferable to the first.
The load, then transform architecture also offers two options for including aggregates, as shown in Figure 7-3.
While Figure 7-3 may look fairly different than Figure 7-2, the two options are essentially the same, with nearly identical pros and cons. Either you have a complex program to read from the staging table into both the fact and its aggregates, or you have separate programs for each. And, either you read the staging data once or once per aggregate. The only difference is that here with the first option, if you're using Oracle 9i, you could use parallel, pipelined table functions to implement the aggregations concurrently with the transform process. Refer back to Chapter 6 for an example of how to do this.
Note that this approach is very complex and will require the DBA to stay intimately involved with the ETL process?probably more so than he or she may desire.
Once again, you should view the second option as preferable to the first.







