Space Management
The two most common reasons data warehousing DBAs get paged at night is either that ETL jobs miss their "must start by" or "must complete by" time due to data volumes and job interdependencies, or ETL jobs cause Oracle errors in the range of ORA-1650 to ORA-1654 ("Unable to extend extent" for rollback segments, undo segments, temp segments, tables and indexes). There's not much that can be done about the first issue, but any competent DBA should definitely be in charge of his or her own destiny regarding the second issue. Proper space management and planning are both prudent and advisable.
For example, the screen snapshot in Figure 9-1 shows an example of a spreadsheet depicting a database's actual and projected growth over nearly a year and a half.
Figure 9-1. Screenshot Showing Data Warehouse Growth Over Time
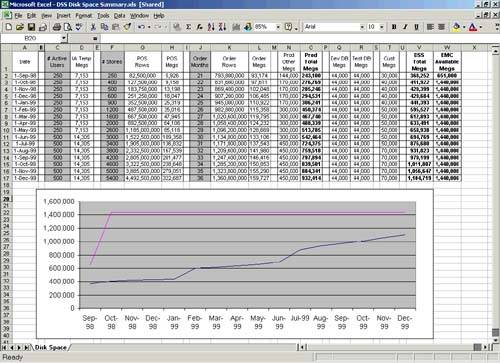
The upper line shows the amount of total disk space available and the lower line shows how the space is being consumed. The idea is that the DBA must know well in advance when the space will run out. While just adding more disks to an existing array may only take a few weeks to a month from order to install, getting a bigger or second disk array may take six months or longer. So, the DBA must truly be psychic regarding when space will run out. Otherwise, you can run out of space and suffer for months. Again, this is another situation where you'd better keep your resume up-to-date if you're not on top of things.
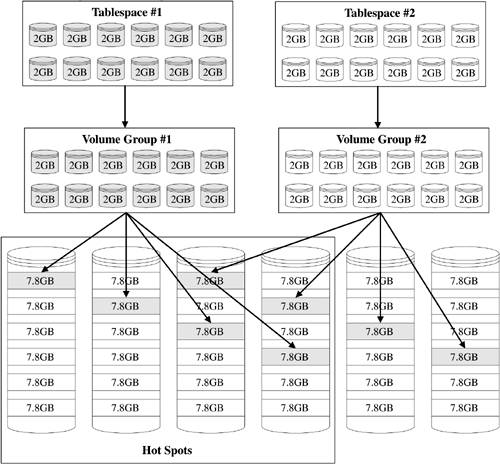
Another common and critical space management mistake I see data warehousing DBAs make is to try and keep their logical volume, tablespace, and data file management overly simple. Often I'll be brought into a troubled shop where the performance stinks and the on-call support is overwhelming (i.e., paged almost nightly). When I look into their space management, I generally find just a few logical volume groups, a few tablespaces, and lots of data files, something like what is shown in Figure 9-2.
Figure 9-2. Logical Volume Manager Disk Layout with Hidden Hot Spot
So what's the problem here? Well, half of Tablespace #1's data files come from Volume Group #1 and half from Volume Group #2. The same is true for Tablespace #2. So let's assume that we have two fact tables: A and B. If Table A is in Tablespace #1 and Table B is in Tablespace #2, the DBA is assuming very little physical disk contention. But look at the figure again: Half of each volume group's physical volumes come from Disks 3 and 4. So, in fact, you have 50% disk contention for each object across these tablespaces. Therefore, the DBA has hot devices, even though he or she has striped across all the disks.
The solution is to create lots of volume groups. That way, you can manually place objects into volume groups such that the overlap at the physical disk level is kept to a minimum. For example, a relatively small data warehouse (i.e., one with just a few terabytes) might have several hundred volume groups. Yes, it's going to be a small battle to convince the system administrators to create so many volume groups, but the results justify it. I've actually seen data warehouses that were near total performance failures completely turned around by simply changing the underlying volume management strategy alone.
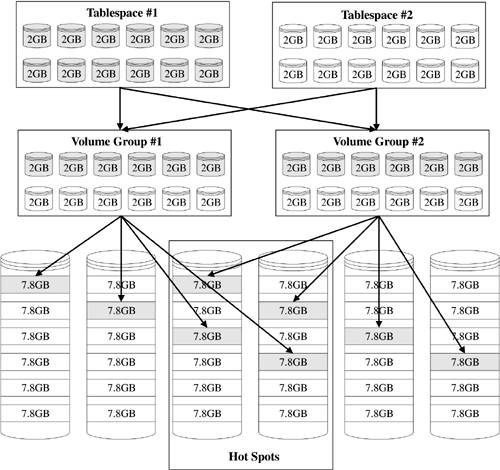
One final and critical space management mistake I sometimes see data warehousing DBAs make is so obvious that I hate to bring it up: Database objects are not striped across the available volume groups. Yes, believe it or not, I've been brought into more than one situation where performance is horrible and this is the case. The culprit is a layout something like what is shown in Figure 9-3.So what's the problem here? Well, it's twofold. First, you have 50% disk contention for each object across these tablespaces (as before). Second and more importantly, you have 67% disk contention for each object in Tablespace #1. Of course, this little six physical disk scenario paints an overly negative picture. The real disk contention would be more like 12.5?25% since most LVMs permit/advise striping across from 4?8 physical disks. In real-world terms, imagine a data warehouse with, say, 256 disks and a logical volume striped across just 8 of those disks. If the DBA placed a really large fact table into a tablespace using data files from just that one volume group, then 248 disks would be sitting idle while just 8 were completely over-stressed. I've seen this more times than I care to admit, so watch out for it.
Figure 9-3. Logical Volume Manager Disk Layout with Obvious Hot Spots