2.6 Distributed Directories
At this point we have completed examining the simple directory of Figure 2-1. Since we have covered the basics, let's expand Figure 2-1 to create a distributed directory. In a distributed directory, different hosts possess different portions of the directory tree.
Figure 2-9 illustrates how the directory would look if the people ou were housed on a separate host. There are many reasons for distributing the directory tree across multiple hosts. These can include, but are not limited to:
- Performance
-
Perhaps one section of the directory tree is heavily used. Placing this branch on a host by itself lets clients access the remaining subtrees more quickly.
- Geographic location
-
Are all the clients that access a particular branch of the directory in one location? If so, it would make more sense to place this section of the directory closer to the client hosts that require it. In this way, trips across a possibly slow WAN link can be avoided.
- Administrative boundaries
-
It is sometimes easier to delegate administrative control of a directory branch by placing the branch on a server controlled by the group responsible for the information in that branch. In this way, the server operators can have full access for duties such as replication and backups without interfering with a larger, more public server.
Figure 2-9. Building a distributed directory
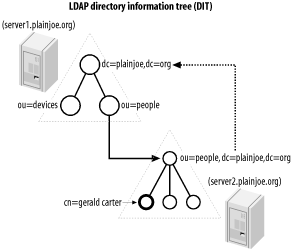
To divide the directory tree between the two servers in Figure 2-9, you must configure two links between the main directory server and the server that holds people ou. To do so, create the superior and subordinate knowledge reference links as shown.
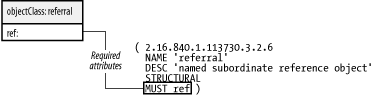
A subordinate knowledge link, often called simply a reference, logically connects a node within a directory tree to the naming context of another server. Most often, the naming context of the second server is a continuation of the directory. In this example, the people ou in the main directory tree has no children because all queries of entries in the ou=people,dc=plainjoe,dc=org tree should be served by the second server. The entry ou=people,dc=plainjoe,dc=org on the main directory server is now a placeholder that contains the referral to the actual directory server for this entry. Figure 2-10 shows the definition for the the referral object class defined in RFC 3296.
Figure 2-10. The referral object class
|
The referral object contains only a single required attribute, ref. This attribute holds the URI that points to the host that contains the subtree. The format of this URI is defined in RFC 2255 as:
ldap://[host:port]/[/dn[?attribute][?scope][?filter][?extensions]]
This syntax will make more sense when we have covered LDAP search parameters in Chapter 4. For our purposes, the most common URI used as a ref value looks like:
ldap://[host:port]/dn
For example, the LDIF listing for the new people ou entry is:
# LDIF listing for the entry ou=people,dc=plainjoe,dc=org dn: ou=people,dc=plainjoe,dc=org objectClass: referral ref: ldap://server2.plainjoe.org/ou=people,dc=plainjoe,dc=org
Configuring the superior knowledge reference link, also called simply a referral but not to be confused with the referral object class, from the second server back to the main directory is a vendor-dependent operation, so it is difficult to tell you exactly what to expect. However, the purpose is to define an LDAP URI (just like the one used as the ref attribute value) that should be returned to clients who attempt to search or query entries outside of the naming context of the subordinate server. In the example discussed here, server2 would be configured to return ldap://server1.plainjoe.org/dc=plainjoe,dc=org to all clients who attempt to go outside of ou=people,dc=plainjoe,dc=org.
Who should follow the referral link? There are two possible answers:
The server follows and resolves any referrals that it runs into during an LDAP operation. The client receives only the result and never knows that the referral happened. This is known as "chaining" and is similar to a recursive DNS server. Chaining has not been standardized. If you are interested, you should consult the documentation for your server to determine whether chaining is supported.
The client follows links for itself. The LDAP client library normally follows the link, but the URI can be handed to the calling application, which is then responsible for following the link itself. This method is supported by all LDAPv3-compliant clients and servers.
|








