Hack 27 Encode XML Documents
![]()
![]()
Character encoding is quite important, especially as XML documents cross international boundaries. This hack will help you understand and use character encoding in XML.
To understand XML, you need to understand the characters that can make up XML documents. XML 1.0 supports the UCS standard, officially ISO/IEC 10646-1:1993 Information technology?Universal Multiple-Octet Coded Character Set (UCS)?Part 1: Architecture and Basic Multilingual Plane, and its seven amendments (search for 10646 on http://www.iso.ch). Since the time that XML became a recommendation at the W3C, UCS has advanced to ISO/IEC 10646-1:2000. In addition, Unicode is a parallel standard to UCS (see http://www.unicode.org). XML 1.0 supports Unicode Version 2.0, but Unicode has advanced to Version 4.0 at this time, so there are differences in what XML 1.0 supports and in what the latest versions of UCS and Unicode support.
Both ISO/IEC 10646-1 UCS and Unicode assign the same values and descriptions for each character; however, Unicode defines some semantics for the characters that ISO/IEC 10646-1 does not.
|

Each character in Unicode is represented by a unique, hexadecimal (base-16) number. The first 128 characters in Unicode are the same characters in US-ASCII or Latin 1 (ISO-8859-1), which surely makes the transition to Unicode easier. The numbers that represent these characters are called code points.
An XML document, whether in a file or in a stream, is really just a series of bytes. A byte is a chunk of bits (ones and zeros), usually eight per chunk (an octet). When you assign a character encoding to a document, you express an intent for the processing software to transform the bytes in the document into a sequence of characters that another processor, such as a word processor, can recognize.
Character encoding is the mapping of binary values to code points or character positions. Let me explain what code points are and why it's important to understand them. Back in the 1960s, the standards organization ANSI created the ASCII or US-ASCII character encoding format. (ASCII is an acronym for American Standard Code for Information Interchange.) US-ASCII represents only 128 characters, numbered in decimal 0-127, with each numbered position representing a code point. In their binary forms, every US-ASCII character is represented by only seven bits?a 7-bit byte rather than an 8-bit byte (octet). Other 7-bit encoding forms were created in other parts of the world at this time as well, not just in the United States.
Character sets map numeric values to graphic character representations; for example, the US-ASCII character set maps the integer 65 to the character A. The uppercase letter A in US-ASCII is represented by the seven bits 1000001 and is mapped to the code point 65 in decimal (integer form) or 41 in hexadecimal.
Seven bits can represent only 128 distinct values (the highest 7-bit binary number, 1111111, equals the decimal equivalent 127), but in human writing systems there are millions of characters beyond the provincial 128 characters of US-ASCII. So if you want more characters, such as 256 rather than 128, you need to at least bump up your binary numbers from seven bits to eight bits. The ISO 8859 standards do just that.
2.18.1 ISO/IEC 8859
The ISO-8859-1 character set, commonly called Latin-1, represents 256 Western European characters, numbered 0-255, using 8-bit bytes or octets. It was originally specified by the European Computer Manufacturers Association (ECMA) in the 1980s, and is currently defined there as ECMA-94 (see http://www.ecma-international.org). This standard was also endorsed by ISO and is specified in ISO/IEC 8859-1:1998 Information technology?8-bit single-byte graphic character sets?Part 1: Latin alphabet No. 1 (see http://www.iso.ch). ISO-8859-1 is only the beginning of a series: there are actually 15 characters sets in this family. These character sets helped to unify earlier 7-bit efforts. All 15 of these 8-bit character sets are specified by ISO and are listed in Table 2-1.
|
ISO standard |
Description |
Character set name |
|---|---|---|
|
ISO/IEC 8859-1:1998 |
Part1 1, Latin 1 |
ISO-8859-1 |
|
ISO/IEC 8859-2:1999 |
Part 2, Latin 2 |
ISO-8859-2 |
|
ISO/IEC 8859-3:1999 |
Part 3, Latin 3 |
ISO-8859-3 |
|
ISO/IEC 8859-4:1998 |
Part 4, Latin 4 |
ISO-8859-4 |
|
ISO/IEC 8859-5:1998 |
Part 5, Cyrillic |
ISO-8859-5 |
|
ISO/IEC 8859-6:1996 |
Part 6, Arabic |
ISO-8859-6 |
|
ISO 8859-7:1987 |
Part 7, Greek |
ISO-8859-7 |
|
ISO/IEC 8859-8:1999 |
Part 8, Hebrew |
ISO-8859-8 |
|
ISO/IEC 8859-9:1999 |
Part 9, Latin 5 |
ISO-8859-9 |
|
ISO/IEC 8859-10:1998 |
Part 10, Latin 6 |
ISO-8859-10 |
|
ISO/IEC 8859-11:2001 |
Part 11, Thai |
ISO-8859-11 |
|
ISO/IEC 8859-13:1998 |
Part 13, Latin 7 |
ISO-8859-13 |
|
ISO/IEC 8859-14:1998 |
Part 14, Latin 8 (Celtic) |
ISO-8859-14 |
|
ISO/IEC 8859-15:1999 |
Part 15, Latin 9 |
ISO-8859-15 |
|
ISO/IEC 8859-16:2001 |
Part 16, Latin 10 |
ISO-8859-16 |
Using octets rather than 7-bit bytes to represent single characters expands the limit from 128 to 256 characters. The ISO 8859 character sets reuse the code points 0-255 for each part, though the characters assigned to those code points can differ. For example, Part 1 assigns the small Latin letter ÿ (y with dieresis) to code point 255 but the same code point 255 is assigned to the ?ü (Cyrillic small letter dzhe) in Part 5.
Unicode avoids the code point conflicts seen in the ISO 8859 specs by assigning a unique number to each character, and it accomplishes this by not limiting character definitions to a single octet. Two of the most common applications of Unicode are the UTF-8 and UTF-16 character encodings.
2.18.2 UTF-8 and UTF-16
XML processors are required to support both UTF-8 and UTF-16 character encodings. These encodings provide different ways of representing Unicode characters in binary form. UTF stands for UCS Transformation Format.
UTF-8 is not limited to a fixed-length character encoding, but can use between one and six octets to represent Unicode characters. Unicode code points in the range 0-255 are represented with one octet, while those in the range 256-2047 are represented with two octets, the range 2048-65535 with three octets, and so forth. UTF-8 uses a special encoding scheme to get the most out of the least bits, using the first octet of a sequence of more than one octet to indicate how many octets are in the sequence. (See http://www.ietf.org/rfc/rfc2279.txt.)
UTF-16 uses a minimum of two octets to represent characters; if the character cannot be represented with two octets, it uses four octets. It also uses a special encoding scheme (see http://www.ietf.org/rfc/rfc2279.txt), but if you are using only Latin characters, UTF-16 characters can take up more space than necessary. For example, the letter A would only take one octet in UTF-8 but would take two octets in UTF-16. On the other hand, a character in the higher ranges that might take six octets in UTF-8 would take at most four octets in UTF-16. UTF-8 is a good choice for Latin alphabets, and UTF-16 is good for Chinese, Japanese, and Korean characters.
2.18.2.1 The Byte Order Mark
A Byte Order Mark (BOM) is a special space character?the Unicode character FEFF?that is used only as an encoding signature. If an XML document is UTF-16, it must begin with a BOM. In the absence of an XML declaration, an XML processor can read the BOM and guess that the document is UTF-16. (If it is UTF-8, it may or may not begin with a BOM.) If the document is not UTF-8 or UTF-16, then the character encoding must be declared explicitly in the XML declaration. (See Section 4.3.3 of the XML specification.)
XML processors may support other encodings such as US-ASCII, ISO-8859-1, or Shift_JIS (Japanese). The Internet Assigned Numbers Authority (IANA) keeps track of encoding names and publishes them at http://www.iana.org/assignments/character-sets. You can use your own private encoding name if you start it with x-, but you would have to write your own code to process it.
What if you have a document that has an encoding declared but is really stored in another encoding? Such is the case with the file oops.xml, which looks identical to time.xml but is stored as UTF-16 even though the encoding declaration says UTF-8. If you check oops.xml for well-formedness with rxp:
rxp oops.xml
you will get this report:
Error: Declared encoding UTF-8 is incompatible with UTF-16 which was used to read it in unnamed entity at line 1 char 37 of file:///C:/Hacks/examples/oops.xml
There are a number of ways to fix this problem. I'll share a couple. One tool you should have on your shelf is Sharmahd Computing's SC UniPad, a Windows Unicode text editor available for download from http://www.unipad.org/download/. This editor has many helpful features for creating and editing Unicode documents, one of which is changing a document's character encoding.
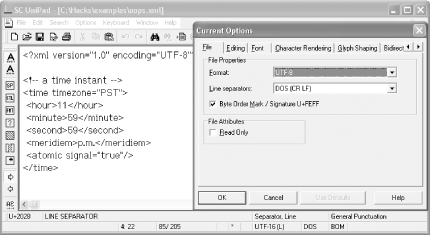
Figure 2-26 shows oops.xml in
SC UniPad. The XML declaration in the file says that the encoding is
UTF-8, but the status bar at the bottom of the editor window reports
that the file is in UTF-16(L) (L is for little
endian) and that the BOM is present. To fix that, choose Options
 Current Options, and the Current Options dialog box
appears. In the File tab, select the UTF-8 format (encoding) and then
click OK. This changes the encoding. Save the file with File
Save. If you process this file with
rxp again, you won't get the
incompatible encoding error you saw earlier.
Current Options, and the Current Options dialog box
appears. In the File tab, select the UTF-8 format (encoding) and then
click OK. This changes the encoding. Save the file with File
Save. If you process this file with
rxp again, you won't get the
incompatible encoding error you saw earlier.
Figure 2-26. Changing the character encoding of oops.xml with SC UniPad
Another way to do this is with the -utf8 option of HTML Tidy [Hack #22] . This command:
tidy -utf8 -xml -o noops.xml oops.xml
will save oops.xml in UTF-8 as noops.xml. The -xml option indicates that the input is well-formed XML.
2.18.3 See Also
HTML Tidy offers a variety of command-line options to change the encoding of a document: [Hack #22]
The command xxd, available on Cygwin and Unix systems, dumps a file, giving a hexadecimal representation of each character; try xxd -g 1 time.xml
Simon St.Laurent's Gorille is a Java tool that tests the characters, names, and content of XML documents: http://gorille.sourceforge.net/






