8.4 Complex Hierarchy Operations
Using Oracle's hierarchical SQL extensions, you can perform complex, hierarchical queries much more easily than you would be able to do using standard, ANSI SQL.
8.4.1 Finding the Number of Levels
Previously we showed how the LEVEL pseudocolumn generates a level number for each record when we use the START WITH . . . CONNECT BY clause. You can use the following query to determine the number of levels in the hierarchy by finding the maximum level number returned by the LEVEL pseudocolumn:
SELECT MAX(LEVEL)
FROM employee
START WITH manager_emp_id IS NULL
CONNECT BY PRIOR emp_id = manager_emp_id;
MAX(LEVEL)
----------
4To determine the number of employees at each level, group the results by LEVEL and count the number of employees in each distinct group. For example:
SELECT LEVEL, COUNT(emp_id)
FROM employee
START WITH manager_emp_id IS NULL
CONNECT BY PRIOR emp_id = manager_emp_id
GROUP BY LEVEL;
LEVEL COUNT(EMP_ID)
--------- -------------
1 1
2 3
3 8
4 28.4.2 Listing Records in Hierarchical Order
One of the very common programming challenges SQL programmers face is to list records in a hierarchy in their proper hierarchical order. For example, you might wish to list employees with their subordinates underneath them, as in the following query:
SELECT LEVEL, LPAD(' ',2*(LEVEL - 1)) || lname "Employee",
emp_id, manager_emp_id
FROM employee
START WITH manager_emp_id IS NULL
CONNECT BY PRIOR emp_id = manager_emp_id;
LEVEL Employee EMP_ID MANAGER_EMP_ID
--------- ------------ --------- --------------
1 KING 7839
2 JONES 7566 7839
3 SCOTT 7788 7566
4 ADAMS 7876 7788
3 FORD 7902 7566
4 SMITH 7369 7902
2 BLAKE 7698 7839
3 ALLEN 7499 7698
3 WARD 7521 7698
3 MARTIN 7654 7698
3 TURNER 7844 7698
3 JAMES 7900 7698
2 CLARK 7782 7839
3 MILLER 7934 7782
14 rows selected.Notice that by using the expression LPAD(' ',2*(LEVEL - 1)), we are able to align employee names in a manner that corresponds to their level. As the level number increases, the number of spaces returned by the expression increases, and the employee name is further indented.
The previous query lists all the employees in the employee table. If you want to filter out certain employees based on some condition, then you can use a WHERE clause in your hierarchical query. Here is an example:
SELECT LEVEL, LPAD(' ',2*(LEVEL - 1)) || lname "Employee",
emp_id, manager_emp_id, salary
FROM employee
WHERE salary > 2000
START WITH manager_emp_id IS NULL
CONNECT BY manager_emp_id = PRIOR emp_id;
LEVEL Employee EMP_ID MANAGER_EMP_ID SALARY
--------- ------------ --------- -------------- ---------
1 KING 7839 5000
3 SCOTT 7788 7566 3000
3 FORD 7902 7566 3000
2 BLAKE 7698 7839 2850
2 CLARK 7782 7839 2450This query lists records with salary > 2000. The WHERE clause restricts the rows returned by the query without affecting other rows in the hierarchy. In our example, the WHERE condition filtered JONES out of the result, but the employees below JONES in the hierarchy (SCOTT and FORD) are not filtered out, and are still indented as they were when JONES was present. The WHERE clause must come before the START WITH . . . CONNECT BY clause in a hierarchical query; otherwise, you'll get a syntax error.
|

As discussed earlier, the START WITH clause is optional?i.e., you can have a CONNECT BY without a START WITH. When the START WITH clause is missing, effectively the query doesn't specify where to start building the hierarchy. In that situation, each row of the table is considered a root, and a hierarchy is built for each row. For example:
SELECT LEVEL, LPAD(' ',2*(LEVEL - 1)) || lname "Employee",
emp_id, manager_emp_id, salary
FROM employee
CONNECT BY manager_emp_id = PRIOR emp_id;
LEVEL Employee EMP_ID MANAGER_EMP_ID SALARY
----- -------------------- ---------- -------------- ----------
1 SCOTT 7788 7566 3000
2 ADAMS 7876 7788 1100
1 FORD 7902 7566 3000
2 SMITH 7369 7902 800
1 ALLEN 7499 7698 1600
1 WARD 7521 7698 1250
1 JAMES 7900 7698 950
1 TURNER 7844 7698 1500
1 MARTIN 7654 7698 1250
1 MILLER 7934 7782 1300
1 ADAMS 7876 7788 1100
1 JONES 7566 7839 2000
2 SCOTT 7788 7566 3000
3 ADAMS 7876 7788 1100
2 FORD 7902 7566 3000
3 SMITH 7369 7902 800
1 CLARK 7782 7839 2450
2 MILLER 7934 7782 1300
1 BLAKE 7698 7839 2850
2 ALLEN 7499 7698 1600
2 WARD 7521 7698 1250
2 JAMES 7900 7698 950
2 TURNER 7844 7698 1500
2 MARTIN 7654 7698 1250
1 SMITH 7369 7902 800
1 KING 7839 5000
2 JONES 7566 7839 2000
3 SCOTT 7788 7566 3000
4 ADAMS 7876 7788 1100
3 FORD 7902 7566 3000
4 SMITH 7369 7902 800
2 CLARK 7782 7839 2450
3 MILLER 7934 7782 1300
2 BLAKE 7698 7839 2850
3 ALLEN 7499 7698 1600
3 WARD 7521 7698 1250
3 JAMES 7900 7698 950
3 TURNER 7844 7698 1500
3 MARTIN 7654 7698 1250
39 rows selected.This example returns the hierarchy tree for each row in the table. In the organization tree under KING, SCOTT is at level 3; however, in the organization tree under JONES, SCOTT is at level 2, and under the organization tree headed by himself, SCOTT is at level 1.
8.4.3 Checking for Ascendancy
Another common operation on hierarchical data is to check for ascendancy. In an organization chart, you may ask whether one employee has authority over another. For example: "Does JONES have any authority over BLAKE?" To find out, you need to search for BLAKE in the subtree headed by JONES. If you find BLAKE in the subtree, then you know that BLAKE either directly or indirectly reports to JONES. If you don't find BLAKE in the subtree, then you know that JONES doesn't have any authority over BLAKE. The following query searches for BLAKE in the subtree headed by JONES:
SELECT * FROM employee WHERE lname = 'BLAKE' START WITH lname = 'JONES' CONNECT BY manager_emp_id = PRIOR emp_id; no rows selected
The START WITH . . . CONNECT BY clause in this example generates the subtree headed by JONES, and the WHERE clause filters this subtree to find BLAKE. As you can see, no rows are returned. This means that BLAKE was not found in JONES's subtree, so you know that JONES has no authority over BLAKE. Let's take a look at another example that produces positive results. This time we'll check to see whether JONES has any authority over SMITH:
SELECT emp_id, lname, dept_id, manager_emp_id, salary, hire_date
FROM employee
WHERE lname = 'SMITH'
START WITH lname = 'JONES'
CONNECT BY manager_emp_id = PRIOR emp_id;
EMP_ID LNAME DEPT_ID MANAGER_EMP_ID SALARY HIRE_DATE
---------- ---------- ---------- -------------- ---------- ---------
7369 SMITH 20 7902 800 17-DEC-80This time, SMITH was found in the list of employees in JONES's subtree, so you know that at some level JONES has management authority over SMITH.
8.4.4 Deleting a Subtree
Let's assume that the organization we are dealing with splits, and JONES and all his subordinates form a new company. Therefore, we don't need to maintain JONES and his subordinates in our employee table. Furthermore, we need to delete the entire subtree headed by JONES, as shown in Figure 8-1, from our table. We can do this by using a subquery as in the following example:
DELETE FROM employee WHERE emp_id IN (SELECT emp_id FROM employee START WITH lname = 'JONES' CONNECT BY manager_emp_id = PRIOR emp_id); 5 rows deleted.
In this example, the subquery generates the subtree headed by JONES, and returns the emp_ids of the employees in that subtree, including JONES's. The outer query then deletes the records with these emp_id values from the employee table.
8.4.5 Listing Multiple Root Nodes
An interesting variation on the problem of listing the root node of a hierarchy is to find and list the root nodes from several hierarchies that are all stored in the same table. For example, you might consider department managers to represent root nodes, and you might further wish to list all department managers found in the employee table.
There are no constraints on the employees belonging to any department. However, you can assume that if A reports to B and B reports to C, and A and C belong to the same department, then B also belongs to the same department. If an employee's manager belongs to another department, then that employee is the uppermost employee, or manager, of his department.
Therefore, to find the uppermost employee in each department, you need to search the tree for those employees whose managers belong to a different department than their own. You can do that using the following query:
SELECT emp_id, lname, dept_id, manager_emp_id, salary, hire_date FROM employee START WITH manager_emp_id IS NULL CONNECT BY manager_emp_id = PRIOR emp_id AND dept_id != PRIOR dept_id; EMP_ID LNAME DEPT_ID MANAGER_EMP_ID SALARY HIRE_DATE ------ -------- -------- -------------- ------ --------- 7839 KING 10 5000 17-NOV-81 7566 JONES 20 7839 2000 02-APR-81 7698 BLAKE 30 7839 2850 01-MAY-80
In this example, the extra condition (dept_id != PRIOR dept_id) added to the CONNECT BY clause restricts the output to only those employees whose managers belong to a different department than their own.
8.4.6 Listing the Top Few Levels of a Hierarchy
Another common task in dealing with hierarchical data is listing the top few levels of a hierarchy tree. For example, you may want to list top management employees in an organization. Let's assume that the top two levels in our organization chart constitute top management. You can then use the LEVEL pseudocolumn to identify those employees, as in the following example:
SELECT emp_id, lname, dept_id, manager_emp_id, salary, hire_date FROM employee WHERE LEVEL <= 2 START WITH manager_emp_id IS NULL CONNECT BY manager_emp_id = PRIOR emp_id; EMP_ID LNAME DEPT_ID MANAGER_EMP_ID SALARY HIRE_DATE ------ --------- ---------- -------------- ------ --------- 7839 KING 10 5000 17-NOV-81 7566 JONES 20 7839 2000 02-APR-81 7698 BLAKE 30 7839 2850 01-MAY-80 7782 CLARK 10 7839 2450 09-JUN-81
In this example, the LEVEL <= 2 condition in the WHERE clause restricts the results to only those employees in the top two levels of the organization chart.
8.4.7 Aggregating a Hierarchy
Another challenging requirement is to aggregate a hierarchy. For example, you may want to sum the salaries of all employees reporting to a specific employee. Or, you may want to consider each employee as a root, and for each employee print out the sum of the salaries of all subordinate employees.
The first problem is relatively simple. Earlier we described how to select a subtree headed by an employee. You can easily sum the salaries of all employees in such a subtree. For example:
SELECT SUM(salary)
FROM employee
START WITH lname = 'JONES'
CONNECT BY manager_emp_id = PRIOR emp_id;
SUM(SALARY)
-----------
9900The START WITH lname = 'JONES' clause generates the subtree headed by JONES, and the SUM(salary) expression sums the salary of employees in this subtree.
The second problem, a seemingly simple extension of the first, is relatively complex. You want to consider each employee as a root, and for each employee you want to sum the salaries of all employees in its subtree. In essence, you want to repeat the previous query for each employee in the table. The following SQL uses an inline view to achieve this:
SELECT t2.lname, t2.salary, (SELECT SUM(t1.salary) FROM employee t1 START WITH t1.lname = t2.lname CONNECT BY t1.manager_emp_id = PRIOR t1.emp_id) sum_salary FROM employee t2; LNAME SALARY SUM_SALARY -------------------- ---------- ---------- SMITH 800 800 ALLEN 1600 1600 WARD 1250 1250 JONES 2000 9900 MARTIN 1250 1250 BLAKE 2850 9400 CLARK 2450 3750 SCOTT 3000 4100 KING 5000 28050 TURNER 1500 1500 ADAMS 1100 1100 JAMES 950 950 FORD 3000 3800 MILLER 1300 1300 14 rows selected.
In this example, the START WITH . . . CONNECT BY clause in the inline view generates a subtree for each employee. The inline view executes once for every row in the outer employee table. For each row in the outer employee table, the inline view generates a subtree headed by this employee, and returns the sum of salaries for all the employees in this subtree to the main query.
The result set provides two numbers for each employee. The first number, salary, is the employee's own salary. The second number, sum_salary, is the sum of the salaries of all employees under him (including himself/herself). Often programmers resort to PL/SQL to solve this type of problem. However, this query, which combines the power of hierarchical queries with that of inline views, solves the problem in a much more concise and elegant way.
8.4.8 Ordering Hierarchical Data
Sorting the results from a hierarchical query is a more interesting problem than it first may sound. A hierarchical query with a START WITH . . . CONNECT BY . . . construct displays the results in an arbitrary order, as shown in the following example:
SELECT LEVEL, LPAD(' ',2*(LEVEL - 1)) || lname "EMPLOYEE",
emp_id, manager_emp_id
FROM employee
START WITH manager_emp_id IS NULL
CONNECT BY PRIOR emp_id = manager_emp_id;
LEVEL EMPLOYEE EMP_ID MANAGER_EMP_ID
---------- -------------------- ---------- --------------
1 KING 7839
2 JONES 7566 7839
3 SCOTT 7788 7566
4 ADAMS 7876 7788
3 FORD 7902 7566
4 SMITH 7369 7902
2 BLAKE 7698 7839
3 ALLEN 7499 7698
3 WARD 7521 7698
3 MARTIN 7654 7698
3 TURNER 7844 7698
3 JAMES 7900 7698
2 CLARK 7782 7839
3 MILLER 7934 7782As always, you can use an ORDER BY clause to order the result rows in the way you want. However, in the case of a hierarchical query, an ORDER BY clause can destroy the hierarchical nature of the data returned by the query. This is shown in the following example, which orders the results by last name:
SELECT LEVEL, LPAD(' ',2*(LEVEL - 1)) || lname "EMPLOYEE",
emp_id, manager_emp_id
FROM employee
START WITH manager_emp_id IS NULL
CONNECT BY PRIOR emp_id = manager_emp_id
ORDER BY lname;
LEVEL EMPLOYEE EMP_ID MANAGER_EMP_ID
---------- -------------------- ---------- --------------
4 ADAMS 7876 7788
3 ALLEN 7499 7698
2 BLAKE 7698 7839
2 CLARK 7782 7839
3 FORD 7902 7566
3 JAMES 7900 7698
2 JONES 7566 7839
1 KING 7839
3 MARTIN 7654 7698
3 MILLER 7934 7782
3 SCOTT 7788 7566
4 SMITH 7369 7902
3 TURNER 7844 7698
3 WARD 7521 7698As you can see from this output, it is impossible to identify the hierarchical relationship between the rows. To resolve this problem, you can use the SIBLINGS (in Oracle9i and later) keyword in the ORDER BY clause, to order the hierarchical data while at the same time preserving the hierarchy. Oracle does this by sorting at each level while ensuring that child nodes remain underneath their parents. For example:
SELECT LEVEL, LPAD(' ',2*(LEVEL - 1)) || lname "EMPLOYEE",
emp_id, manager_emp_id
FROM employee
START WITH manager_emp_id IS NULL
CONNECT BY PRIOR emp_id = manager_emp_id
ORDER SIBLINGS BY lname;
LEVEL EMPLOYEE EMP_ID MANAGER_EMP_ID
---------- -------------------- ---------- --------------
1 KING 7839
2 BLAKE 7698 7839
3 ALLEN 7499 7698
3 JAMES 7900 7698
3 MARTIN 7654 7698
3 TURNER 7844 7698
3 WARD 7521 7698
2 CLARK 7782 7839
3 MILLER 7934 7782
2 JONES 7566 7839
3 FORD 7902 7566
4 SMITH 7369 7902
3 SCOTT 7788 7566
4 ADAMS 7876 7788In this example's output, BLAKE, CLARK, and JONES are siblings, and they are displayed in ascending order. So are BLAKE's children: ALLEN, JAMES, MARTIN, TURNER, and WARD.
8.4.9 Finding the Path to a Node
You can list the entire path of a given node starting from the root node using the SYS_CONNECT_BY_PATH function (in Oracle9i and later). This function takes two arguments: a column name and a character string. The function then returns a list containing each value of the column from the root node to the current node, separating values by the character string you provide. For example:
SELECT SYS_CONNECT_BY_PATH(lname, '#') FROM employee START WITH manager_emp_id IS NULL CONNECT BY PRIOR emp_id = manager_emp_id; SYS_CONNECT_BY_PATH(LNAME,'#') --------------------------------- #KING #KING#JONES #KING#JONES#SCOTT #KING#JONES#SCOTT#ADAMS #KING#JONES#FORD #KING#JONES#FORD#SMITH #KING#BLAKE #KING#BLAKE#ALLEN #KING#BLAKE#WARD #KING#BLAKE#MARTIN #KING#BLAKE#TURNER #KING#BLAKE#JAMES #KING#CLARK #KING#CLARK#MILLER
The preceding query lists the full organizational path for each employee starting at the top. For example, #KING#JONES#FORD#SMITH shows the complete reporting relation of SMITH in the organization.
To understand the usefulness of the SYS_CONNECT_BY_PATH function, think of a trail in a park. The branches of such a trail are illustrated in Figure 8-3.
Figure 8-3. Trails
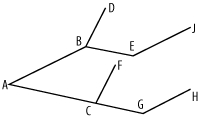
The various points in the trail, and the distance between them is stored in a table, trail:
CREATE TABLE trail (
start_point CHAR,
end_point CHAR,
distance NUMBER
);
INSERT INTO trail VALUES ('A','B', 3);
INSERT INTO trail VALUES ('A','C', 2.5);
INSERT INTO trail VALUES ('B','D', 2);
INSERT INTO trail VALUES ('B','E', 1.5);
INSERT INTO trail VALUES ('C','F', 2.5);
INSERT INTO trail VALUES ('C','G', 2.5);
INSERT INTO trail VALUES ('G','H', 3.5);
INSERT INTO trail VALUES ('E','J', 1.5);
COMMIT;You need to find the total distance of each point in the trail from the starting point "A." The following query uses SYS_CONNECT_BY_PATH to print the distance of each point concatenated with the distances of each of its ancestors in the tree:
SELECT end_point,
SUBSTR(SYS_CONNECT_BY_PATH(distance,'+'),2) total_distance
FROM trail
START WITH start_point = 'A'
CONNECT BY start_point = PRIOR end_point;
E TOTAL_DISTANCE
- --------------------
B 3
D 3+2
E 3+1.5
J 3+1.5+1.5
C 2.5
F 2.5+2.5
G 2.5+2.5
H 2.5+2.5+3.5The SUBSTR function takes out the first "+" in the query's output. Now, each of the total_distance expressions, one for each point, can be evaluated to compute the total distance. One way to evaluate such expressions is to write an eval function, as shown in the following code:
CREATE OR REPLACE FUNCTION eval (exp IN VARCHAR2) RETURN NUMBER IS
result NUMBER;
BEGIN
EXECUTE IMMEDIATE 'SELECT ' || exp || ' FROM DUAL' INTO result;
RETURN result;
EXCEPTION
WHEN OTHERS THEN
RETURN NULL;
END;
/The following example uses the eval function to compute the total distance of each point in the trail from the starting point A:
SELECT end_point,
eval(SUBSTR(SYS_CONNECT_BY_PATH(distance,'+'),2)) total_distance
FROM trail
START WITH start_point = 'A'
CONNECT BY start_point = PRIOR end_point;
E TOTAL_DISTANCE
- --------------
B 3
D 5
E 4.5
J 6
C 2.5
F 5
G 5
H 8.5From this output, it is easy to figure out how far each point is in the trail from the starting point "A."






