'Best of Breed' Maps
Map databases that contain sufficient detail to support mobile location service applications, such as routing, are extremely complex and time consuming to build and maintain. As of 2001, no single map data vendor provided a suitable worldwide map database for location-based services. In fact, even within continents such as North America and Europe, quality of data varies considerably from one map vendor to another. In Europe, as an example, one map data vendor might have excellent data for Germany, but very poor data for the United Kingdom. In North America, one map data vendor might have excellent data in urban areas, but very poor data in rural areas. Thus, it is often necessary to combine various map data sources to achieve complete coverage and adequate quality.
When Is a Best of Breed Map Required?
Best of breed maps can be necessary to achieve high-quality coverage in a market. In Europe, it is important that mobile operator or automotive solutions be pan-European. If a German customer drives to Spain or Italy, he or she expects to have the same quality of service he or she receives at home, and in his or her native language. Thus it is important that the location service is able to route seamlessly across borders and that the quality of the solution in Spain is the same as in Germany.
It might also be necessary to consider a best of breed map database to address specific business model concerns. Map data vendor pricing varies widely, and is often dependent on how the map data is used. It is common to charge based on number of transactions. It might be beneficial in very large location service systems to use less expensive data for transactions that do not require more expensive data sets. As an example, some map databases might have enormous detail that is very valuable for routing, but not necessary for other spatial operations.
Other scenarios to consider could include having primary and backup map databases to provide failover capabilities if a spatial operation (e.g., geocoding or routing) fails, or being able to route on two databases.
Map Database Conflation[1]Introduction One of the greater underlying challenges in delivering mobile location-based service (LBS) applications is the integration and management of high-quality data sets. From a routing and navigation perspective, where accuracy of the database and information is paramount, this is particularly true. The application solution requires high-quality information to identify the user's position, determine the appropriate path of travel, and accurately display the moving position along a map. Because pinpoint positional accuracy is essential for producing quality routes, some map vendors drive tens of thousands of road segments to verify the accuracy of links and attribute data. Any anomalies discovered during testing are corrected in the digital database to reposition road segments to better match their real-world geographic locations. The collection and verification process of these vendors ensures that the high level of data accuracy necessary for deploying sound LBS applications is achieved. Traditionally these capabilities have been achieved using a single supplier of data. However as the LBS application space grows and increasingly demands greater geographical coverage, developers are finding that a single data source is no longer adequate for meeting these stringent requirements. The varying strengths in each source database drive the need to integrate multiple sources. Once the domain of technical experimentation, map database conflation has found its way into a variety of commercial and consumer applications. Online map providers MapQuest and Vicinity have been integrating high-quality NavTech coverage and broad GDT coverage to deliver door-to-door routing solutions over the Internet. Both Microsoft and Kivera, using radically different techniques, have extended this capability to deliver high-quality display solutions for consumer products. Data Conflation and Compilation The conflation process integrates multisource, disparate geographic data sets and their corresponding attribute data. Because data sets frequently vary in their formats, naming conventions, and positional accuracy, conflation is a complicated procedure. Data integrators, to achieve a high-quality data set, must be concerned with the relative accuracy and currency of the data sets to be used. The specific requirements for base map content are often tied to the application. Each application has its own threshold for quality and accuracy. In-vehicle navigation with map matching capabilities requires a high degree of quality for map rendering, whereas an Internet product that delivers raster map images at high zoom levels will be less concerned with the database's final geometric representation. Developing the necessary tools, processes, and algorithms to conflate map databases is a long and involved process. There are two general strategies for conflation, each with its own methods for production, qualities, and limitations. The first, database overlays, is the simpler of the two approaches. When data sets are overlaid, the original data set is essentially left intact. The logic for integration is found in the application layer. On the other hand, database merging calls for the union of two data sets to create a new single map database. In this scenario, the real effort is done during the map compilation phase. This sidebar reviews the different approaches, evaluating their strengths and weaknesses. Overlay Strategy The general principle of overlaying databases is to utilize two or more completely self-contained data sets. The application is responsible for knowing which database contains which information. This is relatively straightforward for geocoding and display applications. Based on some qualitative criteria such as accuracy of positional and attribute data, completeness of the data set and cost, the application sets a preference order for data access. For instance, GDT provides a North America database that is known for its breadth of coverage and accurate address attribution. For this reason, it is often the first database searched when geocoding a user-entered address. The very same application, when displaying a map, might opt to use NavTech for display, due to its high degree of positional accuracy in detailed coverage areas. Obviously there are significant benefits to this approach. It is relatively easy to maintain; changes in one data set have little bearing on the other data set in use. An application developer can independently license and track database usage at the application level. However, routing across disparate data sets presents a great challenge. A routing algorithm must explore across the data set(s) for the appropriate path. If the origin and destination are on different data sets, or if the data set used is disjointed, the application requires some mechanism to "connect" them together. This mechanism is called a standard location reference. The standard reference identifies positions in the first data set that are the same in the second data set. The measure of likeness is based an evaluation of the geometry of the feature and its attribution. There are two different general approaches for defining a standard location reference. With an increasing cost and complexity they are capable of delivering successively higher quality routes. Run-Time Determination of Cross-Over Points The first approach, run-time determination, is an appropriate approach when the data coverage in one database is a subset of the coverage in the other. This was the case in North America, before NavTech began distributing its Full Coverage product. This approach calls for run-time determination of a cross-over point between the two data sets during route calculation. For it to work, the application must identify a primary database in which all route calculations are attempted first. Only in the event that a destination does not fall on the primary database will the secondary database be used. In this case, the application will determine the closest "like" point in the primary database to the destination in the secondary database. This point is then matched against a road segment in the secondary database with similar attribution. Finally, the application calculates the two subroutes joining them at the reference point. Because this approach can be used regardless of the underlying data set, it is cost effective and easy to maintain. However, the quality of the match and route can be rather poor. This is particularly true in situations where there is no primary database coverage in proximity to the secondary database point. This scenario might force the calculation of a roundabout path in the primary database, even though a more direct path exists in the secondary database. Inconsistent naming conventions for street names across the databases can also confuse the algorithms, resulting in very poor matches. For instance, one database might refer to a street as "Mason Drive" and the other might identify it as "Mason Street." Without manual verification, it is nearly impossible for an algorithm to verify the likeness of these two street names. Finally, run-time determination presents significant problems at display time. Because the final matched points are represented at different geographical positions, the connection between them is often off the road network entirely. When displaying this portion of the route, it is common to see a zig-zag image representing the connection. Generally this is not a problem at higher zoom levels; however, if the solution calls for the display of maneuver maps for each route segment, the results are inadequate for high-end services. Precompiled Cross-Over Reference Points Database integrators can resolve many of the problems associated with run-time determination by precompiling a list of "qualified" cross-over points. These lists identify specific places shared between the two data sets that produce high-quality routes when joined together. For data sets with overlapping coverage territory, this method is an improvement over the run-time calculation of cross-over points. It does so by identifying specific freeway interchanges that can serve as database jump points. This solution is effective because it relies on the primary database for high-level arterial connectivity, but makes greater use of the secondary database's network, especially in areas off the highway. Furthermore, naming conventions for freeways are more likely to be routinely verified by data suppliers and in sync with each other. Precompiled cross-over points are also effective in routing across two data sets that do not overlap, but are contiguous. This is quite common, especially along national borders where a best of breed data integrator requires data from two different suppliers. In this scenario, the cross-over points are matched at known border crossings. Border crossings, even more so than freeway interchanges, are fixed network features that will have a high degree of accuracy. These higher quality routes come with a cost. The solutions are specific to a data set and the list of possible cross-over points must be regenerated with each new data release. Furthermore, the introduction of fixed cross-over points creates new challenges for route optimization, especially for routes with multiple stopovers. Regardless, this approach is still a significant improvement over run-time determination. It allows for exhaustive testing and verification before releasing the data to ensure route quality and display standards are met. Database Merging Database merging is a significant strategy shift. Unlike overlaid databases, where the data sets are kept distinct, the goal of merging is to create a new data set that consists of the best available coverage from each data supplier. Often, merging requires a shift in the geometry of one data source such that it lines up with the other. Depending on the desired quality of the conflated database, the process of merging can be extremely complex and time consuming. The requirement to remove duplicate data and resolve conflicting information from the competing suppliers further complicates matters. Despite the high production costs and technical hurdles associated with conflation, data integrators find that merging provides significant benefits above and beyond overlaid data. First of all, the application challenges inherent in overlaid database solutions disappear. The final data set is one single graph, delivered in a single access format. Display, geocoding, and routing applications can be optimized for this data set alone, requiring no intelligence about the quality of one data set in relation to another. Assuming a quality merge process was utilized, map rendering is seamless across the edges. Routes can be calculated across the entire network, and the shape of these route paths will line up exactly with the road network's geometry. Of course, although all this blurring of source data is advantageous to the application developer, it creates a number of complications for data suppliers. Data suppliers, looking to enforce license agreements, have a difficult time tracking real usage of a merged data set. For delivered fixed media products, like desktop software and in-vehicle navigation, this is not an insurmountable problem. Each data supplier negotiates royalties commensurate with the value their data brings to the final solution. Obtaining the volume of units on any shipped product is no great challenge; therefore, calculating the total license cost is relatively straightforward. However, in server-based applications, where per-transaction pricing applies, license management becomes a significant problem. If the underlying source information about the merged database is sufficiently blurred, it is nearly impossible to know which data supplier was really responsible for the transaction and to whom the royalty should be sent. Varying quality requirements have brought about two different conflation strategies for database merging. The first is grid-based merging, the process of edge-matching contiguous tiles of coverage and sewing them together. The other approach, selective area merging, uses one database as a reference grid and augments it with coverage from a secondary supplier. The former approach is far easier to achieve and maintain but produces a database of inferior quality. Grid-Based Merging The approach behind grid-based merging is similar to assembling a jigsaw puzzle. Each subsection is a complete unmodified representation of the map from a single supplier. An adjacent tile from a secondary source is edge-matched to the first, inducing connectivity between contiguous features where necessary. The process typically forces a shift in geometry to ensure connectivity. This can cause distortion in the map's appearance that might be visible at detailed zoom levels. However, the distortion will be confined to the boundaries along the seam. Moreover, because the stitch boundaries are fairly well defined, this approach has a slightly reduced overhead for ongoing maintenance. There are significant problems with this approach. Because the process calls for edge-matching adjacent tiles, it is difficult to remove duplicate data, especially along stitch borders that vary significantly in their representation. This is especially problematic for geocoding applications that might accurately resolve "100 Main Street" twice, once in each underlying data source. Routing algorithms can behave quite erratically on a data set merged this way. A single highway's attribution might change periodically as it moves in and out of a particular source supplier's coverage area. As a result, the conflated database is a blend of attributes, with variable improvements based on location. Selective Area Merging Selective area merging provides significant improvements over a grid-based merge. Conflation software automatically recognizes important features in the primary data set and correlates them with features in the secondary data set. Links are precisely merged, repositioned, and associated with additional attribute data. Each link in a digital map database can have literally hundreds of attributes associated with it, and hence, requires highly intelligent algorithms to test the validity of the road network's connectivity. Start and end points connect links, and when two data sets are merged, the number of links that meet at any given node is an important measure of similarity. The program intuitively performs quality checks to determine whether all links agree with each other. Links containing the better data, from either a positional or attribute perspective, are preserved and redundant links are deleted. These deletions might cause a disconnection of links, but a set of aggressive algorithms that intuitively shifts the links back into place preserves connectivity. The end result is a single database without duplicated data, preserving the best geometry and attribution from each source supplier. Brian Shenson Kivera, Inc. |
Example Merge: Kivera Combined NavTech/GDT Solution[2]
The goal of this project is to provide the most complete road data available for use with in-vehicle navigation systems. To accomplish this, Kivera has applied a novel technology to merge the data sets available from two different vendors: Navigation Technologies (NavTech) and Geographic Data Technologies (GDT).
The purpose of the Kivera merge process is to take information from the GDT data set and add it to the NavTech data set to fill empty spaces. This involves reading map data, clipping it into smaller, more workable files, and then establishing control nodes to align the two maps together.
The Problem
The data set from NavTech is notable for its extremely accurate, reliable information. The coordinates provided by NavTech are highly consistent with those provided by the GPS. The representations of roads in this data set are extremely accurate and very closely reflect the actual roads. Unfortunately, this data set is not complete. Most of the United States has only partial coverage, with data covering only the main highways and extremely sparse coverage of local roads.
Currently, various vehicle navigation systems rely on the NavTech data set, but the incompleteness of the data set creates a lot of customer complaints. That leads to a significant loss of sales of in-vehicle navigation systems because the data set does not cover areas where customers live and drive.
The map data set from GDT is much more complete. There is effectively 100 percent coverage of areas in the United States. However, the data has significant geographical position errors, as well as geometry problems. Using the GDT data alone in an in-vehicle navigation system would be a dubious choice because the GPS system would report very different coordinates for ground positions than the GDT map indicates. GDT data often shows extremely inaccurate representations of ramps and complicated road configurations. Because of the discrepancies between the GDT data set and reality, users of in-vehicle navigation systems using this data would get hopelessly lost quite regularly. GDT data therefore has not been used for highway navigation.
Kivera's Solution
Kivera has come up with a way to merge the data sets of the two vendors to produce a data set that takes advantage of GDT's more complete coverage and NavTech's higher accuracy. In effect, Kivera "sews" the data sets together like a patchwork quilt, as shown in Figures 12.1 through 12.3.
Figure 12.1. NavTech Area Showing Major Roads and Two Loops.
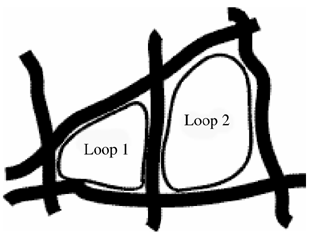
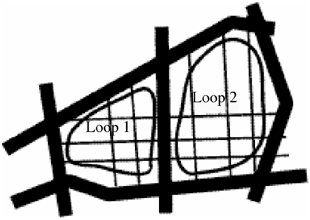
Figure 12.3. Merged Data.
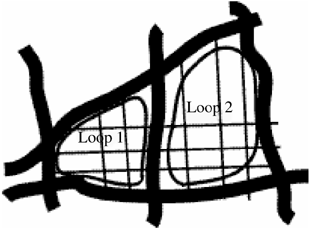
Figure 12.2. GDT Data Covering All Roads (Distorted with Corresponding Loops Indicated).
Loops and Control Nodes
The sewing is accomplished by finding corresponding, closed, circular paths of travel along roads contained in both the NavTech and GDT data sets. A NavTech loop is defined as a path of segments in the NavTech data that makes the sharpest possible right-hand turn at every point, until it comes back to the point of origin. A GDT loop is defined as the closest match to the NavTech loop; it is comprised of roads in GDT data that are duplicated in both data sets. Kivera's software identifies the common road intersections occuring in both the NavTech loop and the GDT data sets along these loops. These are called control nodes. The links between the control nodes form the loop path.
Once a complete, closed loop path has been generated and matched, Kivera software then copies all the GDT links inside each loop and "rubber bands" their geographical position to compensate for the differences in geographcal positions of corresponding intersections. It then "glues" this shifted data on top of the NavTech data set, adding to, but not changing any elements from the original NavTech data set.
Some Specific Problems
Inconsistent Source Data
Of course, the process is not quite that simple. Because the original data was entered by humans, it is full of inconsistencies and other problems that make impossible a totally automated merge of the two data sets. Thus, at one critical stage, every single loop identified by the Kivera software requires inspection and possible alteration via a Kivera-proprietary user interface tool. This is necessary because inconsistencies between NavTech and GDT data are often not resolvable by algorithmic approaches. Approximately 20 percent of the loops generated and matched by the Kivera software require some human alteration to resolve discrepancies.
There are many cases in which the map representations of an area are totally different in the two data sets. Kivera has developed a manual process to resolve most of these cases and to allow all or most of the GDT data in these very confusing loops to be extracted. In some very rare cases, however, impossible areas are simply left out.
"Empties"
There are approximately 240,000 NavTech loops throughout the United States. Many of them are very small and simple and have no GDT data in them that can be clipped out and inserted into the NavTech loop. These are called empties. Typically, empty loops are generated inside of double-digitized highways in the NavTech data, between pairs of overpasses. Other varieties of empties include the inside circles and triangles created by the ramps surrounding an overpass. All 240,000, including approximately 140,000 empties, get passed to human inspector-adjusters.
Inspection Problems
Unfortunately, people are not perfect. Inspector-adjusters get tired and some understand the problems more completely than others. A second pass through the data by the more experienced and accurate members of the inspection team has proven to be necessary to catch errors that were undetected by the first pass. This second pass is assisted by a software program that locates loops with problems introduced by people and submits them along with English-language descriptions of the suspected problems to assist the person reviewing each loop. This tool reports both original data errors and human errors such as the following:
Control nodes that don't perfectly match
Inconsistencies like nonmatching road names and erroneous one-way streets
Severely divergent paths in the two data sets








