10.8 Load Balancing
Load balancing is a technique for improving performance when many activities are processed concurrently. These activities could be in separate processes on different machines, in separate processes on the same machine, or in separate threads within the same process. The architecture makes no difference to the basic guidelines.
To support load balancing, a standard design is to have:
One point of entry for all requests (the request queue)
One or more request-processor objects behind the queue
A mechanism for the queue to decide which processor to hand a particular request to
You also need communication lines between the queue and processors and a way to internally identify requests, but this is an obvious part of the infrastructure. The decision mechanism is typically a simple load-balancing system that distributes requests to those available processors. The request processors specify when they are available or busy. When the queue has a request to process, it chooses the first available request processor. Some applications need more complex decision-making, and use a decision mechanism that allocates requests depending on the type of request.
Our main concern with this architecture is that the queue is a potential bottleneck, so it must pass on requests quickly and be ready fairly continually.[7] The pool of request processors behind the queue can be running in one or more threads or processes, usually one request processor per thread. The pool of threaded request processors can be prestarted or started on demand, or you can have a combination of these. Typically for this kind of setup, there are configuration options that specify how many prestarted request processors there should be, the maximum number of request processors to have running simultaneously, and how long to wait before terminating a request processor since it last processed a request.
[7] The queue is also a single point of failure. For this reason, an advanced load-balancing design does not rely on a single queue. Instead, any queues in the application are distributed, redundantly copied, and monitored so that any queue failure results in only a small performance degradation at worst. Some designs use persistent queue elements so that a critical failure does not lose queued elements. The Java Messaging Service supports persistent queue elements.
Note that there is always a point of diminishing returns on response time versus the number of threads in a system. If you have too many threads running concurrently, the system's overall response time gets worse. The operating-system thread scheduler (or Java-system thread scheduler, if you're not using OS threads) spends more and more time managing threads, and this overhead takes up the CPU time rather than allowing the threads to run.
You also need to consider whether the queue object handles the responses (collecting them from the request processes and handing them back to the clients) or whether the request-processor objects can hand the responses back directly. The former design has the advantage that the client cannot get any direct access to the request-processor objects, but the disadvantage that you are introducing an unnecessary bottleneck in processing terms. The latter option (handing responses back directly), of course, has the opposite characteristics: no extra bottleneck, but access to client objects is enabled.
10.8.1 Free Load Balancing from TCP/IP
If you use sockets to handle incoming requests within one process, the operating system provides some load-balancing support. If you want, the operating system will provide the queue for free. TCP sockets can have multiple threads reading or accepting on them. A connectionless TCP server (such as a web server) performs the following process:
Opens a server socket.
Starts however many threads you want.
Each thread sits on a ServerSocket.accept( ) call, waiting for the call to return (all threads call accept( ) on the identical ServerSocket object).
Whenever a client connects to the server socket, the operating-system TCP stack hands the connection off to only one thread that is blocked on the accept( ) call. This is guaranteed behavior for TCP.
The thread that returns from the accept( ) call gets the client connection (Socket object), reads the request, processes it, and writes the request back (directly to the client).
The thread goes back into the accept( ) call, waiting for the next connection.
At any time, you can start further threads to scale up the server as long as each thread has access to the previously created ServerSocket object. TCP does not allow more than one ServerSocket object to be bound to the same port on any machine (actually, any one network interface). It is therefore not possible to have multiple separate processes (i.e., independent operating-system processes, rather than threads within one operating-system process) serving on the same server socket. (Strictly speaking, it is possible to fork a process into multiple system processes after the socket has been opened. This is a standard practice on Unix servers. Multiprocess TCP servers have some small disadvantages over multithreaded TCP servers, mainly when they need to communicate between themselves or use other expensive resources. However, multiprocess TCP servers do have one big advantage over multithreaded servers, which is that if one server process crashes, the others can continue running independently, unaffected by the crash. Win32 does not support a fork procedure.)
With UDP sockets, the architecture can be slightly different, as you can open a UDP server socket on a port that already has a server socket bound to it. A UDP socket is not connection-oriented but packet-oriented, so there is no accept( ) call to wait on. Instead, all the threads (from potentially multiple system processes) sit on a read( ) call on the UDP socket, and the UDP stack hands off each incoming packet to just one of the threads that are waiting on the read( ). The server then has to use the information from the packet (either at the application level or the protocol level) to determine the return address to send the result of the processed request (again, directly back to the client).
10.8.2 Load-Balancing Classes
If you need to implement your own queuing system, you have to consider whether the queue controls the request processors, or whether the processors access the queue. The latter model is how the socket model works: each request processor sits on the queue and waits for it to pass a request. This looks rather like the following class:
public class PassiveRequestQueue
{
//The queue of requests
FIFO_Queue queue = new FIFO_Queue( );
public synchronized void acceptRequest(Request r)
{
//Add to the queue, then notify all processors waiting
//on the releaseRequest( ) method
queue.add(r);
notify( );
}
public synchronized Request releaseRequest( )
{
for(;;)
{
//if the queue is empty, just go back into the wait call
if (queue.isEmpty( ))
try {wait( );} catch (InterruptedException e){ }
//Need to check again if the queue is empty, in case
//we were interrupted
if (!queue.isEmpty( ))
return (Request) queue.pop( );
}
}
}
The former model, in which the request processors are passive and the queue actively manages them, looks more like the following class:
public class ActiveRequestQueue
//subclass the passive queue that holds the behavior
//needed for managing the queue of requests
extends PassiveRequestQueue
//and make us able to run in our own thread
implements Runnable
{
int MAXIMUM_NUM_SERVERS=3;
//Data for the public queue - a list of private servers
ActiveRequestQueue[ ] servers;
//Data for the private (internal) queues
//the RequestProcessor
RequestProcessor requestProcessor;
//Retain a handle on my thread so that we can easily access
//it if we need control
Thread myThread;
//Keep a handle on the 'public' queue - the one that
//actually holds the objects
ActiveRequestQueue queueServer;
//Availability
boolean isAvailable = true;
//Internal queue object - processes requests
private ActiveRequestQueue(ActiveRequestQueue q)
{
queueServer = q;
requestProcessor=new RequestProcessor( );
}
//External queue object - accepts requests and manages a queue of them
public ActiveRequestQueue(int num_servers)
{
//Create a pool of queue servers and start them in their own threads
servers = new ActiveRequestQueue[num_servers];
Thread t;
for (int i = servers.length-1; i>=0 ; i--)
{
servers[i] = new ActiveRequestQueue(this);
(t = new Thread(servers[i])).start( );
servers[i].myThread = t;
}
}
public synchronized void acceptRequest(Request r)
{
//Override the super class accept to increase the number
//of servers if they are all busy
//If we already have the maximum number of threads,
//just queue the request
if (servers.length >= MAXIMUM_NUM_SERVERS)
{
super.acceptRequest(r);
return;
}
//otherwise, if one of the servers is available, just queue
//the request
for (int i = servers.length-1; i>=0 ; i--)
{
if (servers[i].isAvailable( ))
{
super.acceptRequest(r);
return;
}
}
//otherwise, increase the server pool by one, then queue the request
Thread t;
ActiveRequestQueue[ ] tmp_servers = servers;
servers = new ActiveRequestQueue[tmp_servers.length+1];
System.arraycopy(tmp_servers, 0, servers, 0, tmp_servers.length);
servers[tmp_servers.length] = new ActiveRequestQueue(this);
(t = new Thread(servers[tmp_servers.length])).start( );
servers[tmp_servers.length].myThread = t;
super.acceptRequest(r);
}
public void run( )
{
Request request;
RequestResult result;
//Private queues use this method.
//Basically, we just ask the public server for a request.
//The releaseRequest( ) method blocks until one is available.
//Then we process it and start again.
for(;;)
{
request = queueServer.releaseRequest( );
isAvailable = false;
result = requestProcessor.processRequest(request);
returnResult(result);
isAvailable = true;
}
}
public boolean isAvailable( ) { return isAvailable;}
public void returnResult(RequestResult r) { }
}
Note that the server classes as they stand can be tested with the following minimal implementations for support classes:
class FIFO_Queue {
java.util.Stack v = new java.util.Stack( );
public void add(Object o){v.push(o);}
public Object pop( ){return v.pop( );}
public boolean isEmpty( ){return v.isEmpty( );}
}
class RequestProcessor {
public RequestResult processRequest(Request r)
{
System.out.println("Processing request: " + r);
try{Thread.sleep(2000);}catch(InterruptedException e){ }
return new RequestResult( );
}
}
class RequestResult { }
class Request { }
10.8.3 A Load-Balancing Example
It may help to look at a concrete implementation of load balancing. I'll consider the task of downloading many pages from a web server as quickly as possible.
|
The individual page download code is quite simple. Open a URL, read the data, and dump it into a local file:
/* Two args, the local file to put the downloaded page into,
* and the URL where the page to download is.
*/
public static void dowload(String file, String url)
throws IOException
{
URL u = new URL(url);
InputStream in = null;
//Try repeatedly to get the page opened. Note that catching
//all exceptions is not such a good idea here. It would be
//much better to catch individual execption types and handle
//them separately. Some exceptions should not lead to a repeated
//attempt to access the page. But this definition is okay for testing.
while(in = = null)
try{in = u.openStream( );}
catch(Exception e){try {Thread.sleep(500);}catch(Exception e2){ }}
FileOutputStream out = new FileOutputStream(file);
byte[ ] buffer = new byte[8192];
//read until the connection terminates (this is not a
//keep-alive connection), and write to the file.
int len = in.read(buffer);
while(len != -1)
{
out.write(buffer, 0, len);
len = in.read(buffer);
}
out.close( );
in.close( );
}
All our tests use this same download( ) method. The most straightforward test implementation is extremely simple. Simply take a list of URLs and corresponding data files, and loop calling download( ) for each URL/file pair:
//Use one array to hold alternate file and URL elements
public static void iterativeTest(String[ ] files)
throws IOException
{
for (int i = 0; i < files.length; i+=2)
download(files[i], files[i+1]);
}
The opposite to downloading pages one by one is to try to download everything at the same time. Once again, the code is quite straightforward (apart from timing issues: see the earlier section Section 10.5). You simply define a Runnable class and loop, starting a thread for every download:
public class LoadBalancing
implements Runnable
{
String url;
String localfilename;
public static void massivelyParallelTest(String[ ] files)
throws IOException
{
for (int i = 0; i < files.length; i+=2)
(new Thread(new LoadBalancing(files[i], files[i+1]))).start( );
}
public LoadBalancing(String f, String u)
{
localfilename = f;
url = s;
}
public void run( )
{
try
{
download(localfilename, filename);
}
catch(Exception e) {e.printStackTrace( );}
}
The earlier iterative test takes seven times longer than the latter multithreaded test.[8] However, the latter test suffers from significant resource problems. Creating so many threads simultaneously can seriously strain a system. In fact, every system has a limit to the number of threads it can create. If the download requires more threads than the system is capable of supporting, this multithreaded test fails to download many pages. In addition, with so many threads running simultaneously, you are using more of the system's resources than is optimal.
[8] For my tests, I downloaded a large number of pages. I validated the tests over the Internet, but not surprisingly, Internet access times are extremely variable. For detailed repeatable tests, I used a small local HTTP server that allowed me to control all the parameters to the tests very precisely. The full test class, tuning.threads.LoadBalancing, is available with the other classes from this book.
Let's look at a more balanced approach. In fact, you can create a very simple load-balanced test with one small variation to the last test. Simply add a delay between each thread creation to stagger the system load from threads and downloading. This new version of the massivelyParallelTest( ) method is simple:
public static void roughlyParallelTest(String[ ] files, int delay)
throws IOException
{
for (int i = 0; i < files.length; i+=2)
{
(new Thread(new LoadBalancing(files[i], files[i+1]))).start( );
try{Thread.sleep(delay);}catch(InterruptedException e){ }
}
}
Now you have a tuning parameter that needs to be optimized. Obviously, a delay of zero is the same test as the previous test, and a very large delay means that the test is spending most of its time simply waiting to create the next thread. Somewhere in between is an optimal range that creates threads fast enough to fully use the system resources, but not so fast that the system is overloaded.
This range is different depending on the full environment, and probably needs to be experimentally determined. But you can make a decent first guess by considering the bottlenecks of the system. In this case, the bottlenecks are CPU, system memory, disk throughput, network-connection latency, server-download rates, and network throughput. In my tests, system memory and CPU limit the number of threads and download speed for the massively parallel case, but you are using a delay specifically to reduce the load on those resources. System memory constrains the number of threads you can use, but again, the delay avoids overloading this resource (provided that the delay is not too short). Disk throughput can be significant, but network and server throughput are far more likely to limit data-transfer rates. So we are left with network-transfer rates and network-connection latency to consider.
Now you can make a good guess as to a starting point for the delay. You can evaluate the average number of bytes to transfer for each download, and work out the amount of time this takes based on the available network throughput. You can also estimate the average time taken to make a connection (by measuring some real connections). A straightforward guess is to set the delay at a value below the higher of these two averages. In my tests, the files being downloaded are not large, and the average connection time is the larger time. I started with a delay of about half the average connection time and ran tests increasing and decreasing the delay in steps of about 10% at a time. Figure 10-3 shows the results of varying the delay times. An optimum choice for the delay in this particular test environment is approximately 70% of the average connection time. The flat line in the middle of the graph shows the relative time taken for the massively parallel test.
Figure 10-3. The results of varying the delay
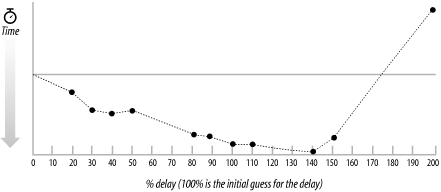
The results show that for this environment there are several advantages to running with a delay. A decisive advantage is that you never run out of system resources. There are never so many threads running simultaneously that you run out of memory and completely lose URLs, as occurred with the massively parallel test. In fact, the system doesn't even need to run to full capacity for most of the test.
Another significant advantage is that by tuning the delay, you can run the test faster. The optimum value for the delay, at 70% of the average connection time, executes the full test in 90% of the massively parallel time.
What about our nice load-balancing architecture classes? Let's test these to see how they compare to the last simple optimization you made. You need to add a few support classes so that your load-balancing architecture is running the same download test. Basically, there are three classes to define: Request, RequestProcessor, and RequestResult. They are fairly simple to implement. Request needs to hold only a URL and a local file for storing the downloaded page. RequestProcessor simply needs to call the download( ) method. RequestResult does not need any extra behavior for the test.[9]
[9] RequestResult does need extra state and behavior in order to make timing measurements, and RequestProcessor is similarly a bit more complicated for timing purposes. For full details, see the test class, tuning.threads.LoadBalancing, which is available with the other classes from this book.
The classes are as follows:
class RequestProcessor {
public RequestResult processRequest(Request r)
{
try
{
LoadBalancing.dowload(r.localfilename, r.url);
}
catch(Exception e) {e.printStackTrace( );}
return new RequestResult( );
}
}
class Request
{
String localfilename;
String url;
public Request(String f, String u)
{
localfilename = f;
url = u;
}
}
class RequestResult { }
In addition, of course, you need to define the method that kicks off the test itself:
public static void loadBalancedTest(String[ ] files, int numThreads)
throws IOException
{
ActiveRequestQueue server = new ActiveRequestQueue(numThreads);
for (int i = 0; i < files.length; i+=2)
server.acceptRequest(new Request(files[i], files[i+1]));
}
I have included a variable to determine the optimum number of threads. As with the earlier test that used a variable delay, the optimum number of threads for this test needs to be experimentally determined. For my test environment, the bottleneck is likely to be my small network throughput. This is easy to see: each thread corresponds to one download. So for n threads to be working at full capacity, they need to be downloading n files, which amounts to a throughput of n times the average file size. This means that for my test environment, about 10 threads reach capacity. In fact, since files are not all the same size and there are some overheads in the architecture, I would expect the optimum number of threads to be slightly larger than 10.
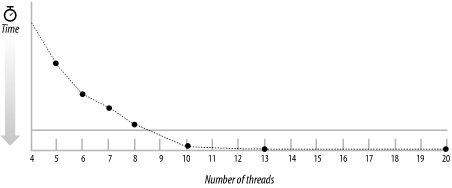
Running the test with different numbers of threads shows that for 12 or more threads, the time taken is essentially the same (see Figure 10-4). This time is also the same as that achieved with the previous most optimal test. This is not surprising. Both tests optimized the downloads enough that they have reached the same network-throughput bottleneck. This bottleneck cannot be optimized any further by either test.
Figure 10-4. Time taken for the load-balanced download versus number of threads
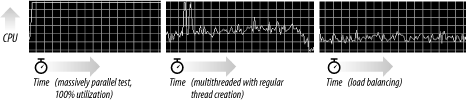
The load-balancing architecture is more complex than adding a delay between threads, but it is much more flexible and far more controlled. If you want to vary your download in a number of ways, such as prioritizing URLs or repeating certain failed ones, it is much easier to do so with the load-balancing architecture. By looking at the CPU utilization graphs for the load-balancing architecture compared to the other tests in Figure 10-5, you can easily see how much more controlled it is and how it uses resources in a far more consistent manner.
Figure 10-5. CPU utilization for various download tests