Database Legacy
Database Legacy
Flat file, hierarchy, and network databases are usually referred as legacy databases. They represent the ways people used to organize information in prehistoric times — about 30 years ago.
Flat file databases
The flat file database was probably one of the earliest database management systems. The idea behind flat file is a very simple one: one single, mostly unstructured data file. It mirrors "ancient" precomputer data storage systems: notebooks, grocery lists, and so on. You could compare it to a desk drawer that holds virtually everything — bill stubs, letters, small change. While requiring very little effort to put information in, such a "design" becomes a nightmare to get the information out, as you would have to scroll through each and every record searching for the right one. Putting relevant data into separate files and even organizing them into tables (think of a file cabinet) alleviates the problem somewhat but does not remove the major obstacles: data redundancy (the same information might be stored more than once in different files), slow processing speed ("I know it was there somewhere..."), error-prone storage and retrieval. Moreover, it required intimate knowledge of the database structure to work at all — it would be utterly useless to search for, say, orders information in the expenses file.
Let's design a flat database system for an order entry system that gathers information about customers, orders they've placed and products the customers had ordered. If data is accumulated sequentially, your file will contain information about customers, then orders and products, then about some new customer, and so on — all in the order the data is entered (Table 1-2). Just imagine a task of extracting any meaningful information from this mess, not to mention that a lot of the cells will remain empty. (What would you fill Quantity column for the "Ace Hardware" or Address column for "Nails" with?)
|
Name |
Type |
Address |
Price |
Quantity |
|---|---|---|---|---|
|
Nails |
Product |
n/a |
100 |
2000 |
|
Ace Hardware |
Customer |
1234 Willow Ct Seattle, Washington |
n/a |
n/a |
|
Cedar planks |
Product |
n/a |
2000 |
5000 |
Dissatisfaction with these shortcomings stimulated development in the area of data storage-and-retrieval systems.
| Note |
Excel is often used to create flat file databases. |
Hierarchical databases
The concept of a hierarchical database was around since the 1960s and — believe it or not — it is still in use. The hierarchical model is fairly intuitive: As the name implies, it stores data in hierarchical structure, similar to that of a family tree, organization chart, or pyramid; some readers could visualize a computer file system as it is presented through some graphical interface.
The most popular hierarchical database product is IBM's Information Management System (IMS) that runs on mainframe computers. First introduced in 1968, it is still around (after a number of reincarnations), primarily because hierarchical databases provide impressive raw speed performance for certain types of queries.
It is based on "parent/child" paradigm in which each parent could have many children but each child has one and only one parent. You can visualize this structure as an upside down tree, starting at the root (trunk) and branching out at many levels (Figure 1-1).
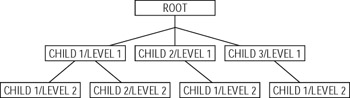 Figure 1-1: Hierarchical structure
Figure 1-1: Hierarchical structure
Since the records in a child table are accessed through a hierarchy of levels there could not be a record in it without a corresponding pointer record in the parent table — all the way up to the root. You could compare it to a file management system (like a tree-view seen in the Microsoft Windows Explorer) — to get access to a file within a directory one must first open the folder that contains this file.
Let's improve upon the previously discussed flat file model. Instead of dumping all the information into a single file you are going to split it among three tables, each containing pertinent information: business name and address for the CUSTOMER table; product description, brand name, and price for the PRODUCT table; and an ORDER_HEADER table to store the details of the order.
In the hierarchical database model redundancy is greatly reduced (compared with flat file database model): You store information about customer, product, and so on once only. The table ORDER_HEADER (Figure 1-2) would contain pointers to the customer and to the product this customer had ordered; whenever you need to see what products any particular customer purchased, you start with ORDER_HEADER table, find list of id(s) for all the customers who placed orders and list of product id(s) for each customer; then, using CUSTOMER table you find the customer name you are after, and using products id(s) list you get the description of the products from the PRODUCT table.

Figure 1-2: Hierarchical database example
Everything works great as long as one is willing to put up with a somewhat nonintuitive way of retrieving information. (No matter what information is requested one always has to start with the root, i.e., ORDER_HEADER table.) Should you need only customers' names the hierarchical database would be blazingly fast — going straight from a parent table to the child one. To get any information from the hierarchical database a user has to have an intimate knowledge of the database structure; and the structure itself was extremely inflexible — if, for instance, you'd decided that the customers must place an order through a third party, you'd need to rewire all relationships because CUSTOMER table would not be related to ORDER_HEADER table anymore, and all your queries will have to be rewritten to include one more step — finding the sales agent who sold this product, then finding customers who bought it. It also makes obvious the fact that you did not escape the redundancy problem — if you have a customer who places an order through more than one sales agent, you'll have to replicate all the information for each agent in a number of customer tables.
But what happens if you need to add a customer that does not have a placed order, or a product that no one yet ordered? You cannot — your hierarchical database is incapable of storing information in child tables without a parent table having a pointer to it: by the very definition of hierarchy there should be neither a product without an order, nor a customer without an order — which obviously cannot be the case in the real world.
The hierarchical databases handle one-to-many relationship (see Chapter 2 for definition) very well. However, in many cases you will want to have the child be related to more than one parent: Not only one product could be present in many orders, but one order could contain many products. There is no answer (at least not an easy one) within the domain of hierarchical databases.
Network databases
Attempts to solve the problems associated with hierarchical databases produced the network database model. This model has its origins in the Conference on Data Systems Languages (CODASYL), an organization founded in 1957 by the U.S. Department of Defense. CODASYL was responsible for developing COBOL — one of the first widely popular programming languages — and publishing the Network Database standard in 1971 The most popular commercial implementation of the network model was Adabas (long since converted to the relational model).
The network model is very similar to the hierarchical one; it is also based on the concept of parent/child relationship but removes the restriction of one child having one and only one parent. In the network database model a parent can have multiple children, and a child can have multiple parents. This structure could be visualized as several trees that share some branches. In network database jargon these relationships came to be known as sets.
In addition to the ability to handle a one-to-many relationship, the network database can handle many-to-many relationships.
| Cross-References |
One-to-one, one-to-many, and many-to-many relationships are explained in Chapter 2. |
Also, data access did not have to begin with the root; instead one could traverse the database structure starting from any table and navigating a related table in any direction (Figure 1-3).
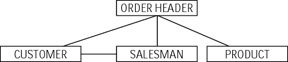
Figure 1-3: Network database example
In this example, to find out what products were sold to what customers we still would have to start with ORDER_HEADER and then proceed to CUSTOMER and PRODUCT — nothing new here. But things greatly improve for the scenario when customers place an order through more than one agent: no longer does one have to go through agents to list customers of the specific product, and no longer has one to start at the root in search of records.
While providing several advantages, network databases share several problems with hierarchical databases. Both are very inflexible, and changes in the structure (for example, a new table to reflect changed business logic) require that the entire database be rebuilt; also, set relationships and record structures must be predefined.
The major disadvantage of both network and hierarchical database was that they are programmers' domains. To answer the simplest query, one had to create a program that navigated database structure and produced an output; unlike SQL this program was written in procedural, often proprietary, language and required a great deal of knowledge — of both database structure and underlying operating system. As a result, such programs were not portable and took enormous (by today's standards) amount of time to write.







