9.2 Why (Not) Intercept?
Many organizations find interception caching attractive because they can't, or would rather not, configure all their user's web browsers. It's probably easier to perform a little network trickery on a single switch or router than it is to configure hundreds or thousands of workstations. As with many choices we face, interception caching is really a tradeoff. It brings both benefits and drawbacks. It may make your life easier, or more difficult.
The obvious benefit of interception caching is that all HTTP requests leaving your network automatically go through Squid. You don't need to worry about configuring any browsers or that users might disable their proxy settings. Interception caching puts you, the network administrator, in control of the HTTP traffic. You can change, add, or remove Squid caches from service without significantly interrupting your users' web surfing.
Most of the disadvantages surrounding HTTP interception are because this technique violates the TCP/IP standards. These protocols mandate that routers (and switches) forward TCP/IP packets to the host specified by the destination IP address. Diverting the packets to a caching proxy breaks the rules. The proxy accepts diverted connections under false pretense. User agents are tricked into believing they have established a TCP connection with the origin server.
This confusion causes a serious problem with older versions of Microsoft's Internet Explorer. The browser's Reload button is the easiest way to refresh an HTML page. When Explorer is configured to use a caching proxy, a reload request includes a Cache-Control: no-cache header to force a cache miss (or validation) and ensure that the response is up to date. Explorer omits this header when not explicitly configured for proxying. With interception caching, Explorer thinks it is connecting to the origin server anyway, and there is no need to send this header. Squid can't tell that the user pressed the Reload button in this case and may not validate the cached response. Squid's ie_refresh provides a partial workaround for this bug (see Appendix A). According to Microsoft, this problem has been corrected in Explorer Version 5.5, Service Pack 1.[1]
[1] See Microsoft support knowledge base article Q266121 for more (or less) information: http://support.microsoft.com/support/kb/articles/Q266/1/21.ASP.
For similar reasons, you can't use HTTP proxy authentication in combination with interception caching. Because the client is unaware of the proxy, it doesn't send the necessary Proxy-Authorization header. Additionally, the 407 (Proxy Authorization Required) response code is inappropriate because the response should look like it came from the origin server, which would never send such a reply.
You also can't use RFC 1413 ident lookups (see Section 6.1.2.11) with interception. Squid can't bind a new TCP socket to the necessary IP address. The operating system cheats when forwarding the intercepted connection to Squid. However, it can't cheat when Squid wants to bind a new TCP socket to the foreign IP address. The address that it wants to bind to isn't really local, so the bind system call fails.
Interception caching is also incompatible with IP filtering designed to prevent address spoofing (See also RFC 2267: Network Ingress Filtering: Defeating Denial of Service Attacks Which Employ IP Source Address Spoofing). Consider the network shown in Figure 9-2. The router has two LAN interfaces: lan0 and lan1. The network administrator uses packet filters on the router to make sure that the internal hosts don't transmit packets with spoofed source addresses. The router forwards only packets with source addresses corresponding to the connected networks. The packet filter rules might look something like this:
# lan0 allow ip from 172.16.1.0/24 to any via lan0 deny ip from any to any via lan0 # lan1 allow ip from 10.0.0.0/16 to any via lan1 deny ip from any to any via lan1
Figure 9-2. Interception caching breaks address spoofing filters
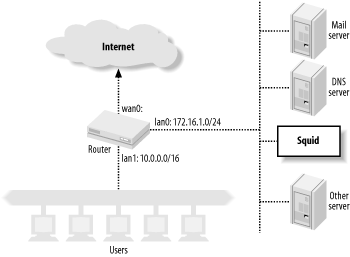
Now consider what happens when the router and Squid box on lan1 are configured to intercept HTTP connections coming from lan0. Squid pretends to be the origin server, which means that the TCP packets carrying response data from Squid back to the users have spoofed source addresses. These lan0 filter rules cause the router to deny these packets. To make interception caching work, the network administrator must remove the lan0 rules. This, in turn, leaves the network vulnerable to being the source of denial-of-service attacks.
As I explained in the previous section, clients must make DNS queries before opening a connection. This may be undesirable or difficult in certain firewall environments. A host whose HTTP traffic you want to intercept must be able to query the DNS. Clients that know they are using a proxy (due to manual configuration or proxy auto-configuration, for example) don't usually try to resolve hostnames. Instead, they simply forward full URLs to Squid, and it becomes Squid's job to look up origin server IP addresses.
Another little problem is that Squid accepts connections for any destination IP address. Consider, for example, a web site that still has a DNS entry even though the site and server have been taken down. Squid accepts the TCP connection for this bogus site. The client believes the site is up and running, because it's connection is established. When Squid fails to connect to the origin server, it is forced to return an error message.
In case it's not clear, HTTP interception can be tricky and difficult to get working the first time. A number of different components must all work together and be correctly configured. Furthermore, it can be difficult to recreate the entire configuration from memory. I strongly encourage you to set up a test environment before attempting this on a production system. Once you get it all working, be sure to document every little step.







