2.6 Resolution
Name servers are adept at retrieving data from the domain namespace. They have to be, given the limited intelligence of most resolvers. Not only can they give you data about zones for which they're authoritative, they can also search through the domain namespace to find data for which they're not authoritative. This process is called name resolution or simply resolution.
Because the namespace is structured as an inverted tree, a name server needs only the domain names and addresses of the root name servers to find its way to any point in the tree. A name server can issue a query to a root name server for any domain name in the domain namespace, and the root name server will start the name server on its way.
2.6.1 Root Name Servers
The root name servers know where the authoritative name servers for each of the top-level zones are. (In fact, some of the root name servers are authoritative for some of the generic top-level zones.) Given a query about any domain name, the root name servers can at least provide the names and addresses of the name servers that are authoritative for the top-level zone the domain name ends in. In turn, the top-level name servers can provide the list of authoritative name servers for the second-level zone that the domain name ends in. Each name server queried either gives the querier information about how to get "closer" to the answer it's seeking or provides the answer itself.
The root name servers are clearly important to resolution. Because they're so important, DNS provides mechanisms?such as caching, which we'll discuss a little later?to help offload the root name servers. But in the absence of other information, resolution has to start at the root name servers. This makes the root name servers crucial to the operation of DNS; if all the Internet root name servers were unreachable for an extended period, all resolution on the Internet would fail. To protect against this, the Internet has 13 root name servers (as of this writing) spread across different parts of the network. One is on PSINet, a commercial Internet backbone; one is on the NASA Science Internet; two are in Europe; and one is in Japan.
Being the focal point for so many queries keeps the roots busy; even with 13, the traffic to each root name server is very high. A recent informal poll of root name server administrators showed each root receiving thousands of queries per second.
Despite the load placed on root name servers, resolution on the Internet works quite well. Figure 2-12 shows the resolution process for the address of a real host in a real domain, including how the process corresponds to traversing the domain namespace tree.
Figure 2-12. Resolution of girigiri.gbrmpa.gov.au on the Internet
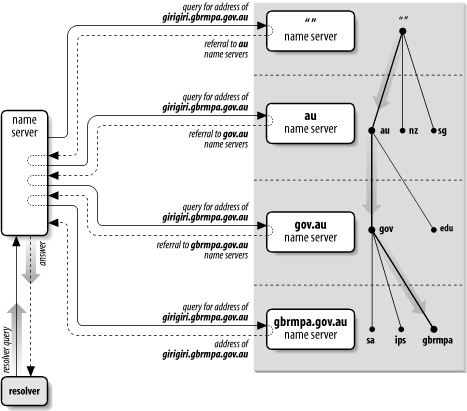
The local name server queries a root name server for the address of girigiri.gbrmpa.gov.au and is referred to the au name servers. The local name server asks an au name server the same question, and is referred to the gov.au name servers. The gov.au name server refers the local name server to the gbrmpa.gov.au name servers. Finally, the local name server asks a gbrmpa.gov.au name server for the address and gets the answer.
2.6.2 Recursion
You may have noticed a big difference in the amount of work done by the name servers in the previous example. Four of the name servers simply returned the best answer they already had?mostly referrals to other name servers?to the queries they received. They didn't have to send their own queries to find the data requested. But one name server?the one queried by the resolver?had to follow successive referrals until it received an answer.
Why couldn't the local name server simply have referred the resolver to another name server? Because a stub resolver wouldn't have had the intelligence to follow a referral. And how did the name server know not to answer with a referral? Because the resolver issued a recursive query.
Queries come in two flavors, recursive and iterative, also called nonrecursive. Recursive queries place most of the burden of resolution on a single name server. Recursion, or recursive resolution, is just a name for the resolution process used by a name server when it receives recursive queries. As with recursive algorithms in programming, the name server repeats the same basic process (querying a remote name server and following any referrals) until it receives an answer.
Iteration, or iterative resolution, on the other hand, refers to the resolution process used by a name server when it receives iterative queries.
In recursion, a resolver sends a recursive query to a name server for information about a particular domain name. The queried name server is then obliged to respond with the requested data or with an error stating either that data of the requested type doesn't exist or that the domain name specified doesn't exist.[7] The name server can't just refer the querier to a different name server, because the query was recursive.
[7] The Microsoft DNS Server can be configured to ignore recursive queries. See Chapter 11 for how and why you'd want to do this.
If the queried name server isn't authoritative for the data requested, it will have to query other name servers to find the answer. It could send recursive queries to those name servers, thereby obliging them to find the answer and return it (and passing the buck), or it could send iterative queries and possibly be referred to other name servers "closer" to the domain name it's seeking. Current implementations are polite and by default do the latter, following the referrals until an answer is found.[8]
[8] The exception is a name server configured to forward all unresolved queries to a designated name server, called a forwarder. See Chapter 11 for more information on using forwarders.
A name server that receives a recursive query that it can't answer itself will query the "closest known" name servers. The closest known name servers are the servers authoritative for the zone closest to the domain name being looked up. For example, if the name server receives a recursive query for the address of the domain name girigiri.gbrmpa.gov.au, it will first check whether it knows which name servers are authoritative for girigiri.gbrmpa.gov.au. If it does, it will send the query to one of them. If not, it will check whether it knows the name servers for gbrmpa.gov.au, and after that gov.au, and then au. The default, where the check is guaranteed to stop, is the root zone, since every name server knows the domain names and addresses of the root name servers.
Using the closest known name servers ensures that the resolution process is as short as possible. A berkeley.edu name server receiving a recursive query for the address of waxwing.ce.berkeley.edu shouldn't have to consult the root name servers; it can simply follow delegation information directly to the ce.berkeley.edu name servers. Likewise, a name server that has just looked up a domain name in ce.berkeley.edu shouldn't have to start resolution at the root to look up another ce.berkeley.edu (or berkeley.edu) domain name; we'll show how this works in the upcoming section on caching.
The name server that receives the recursive query always sends the same query that the resolver sent it; for example, for the address of waxwing.ce.berkeley.edu. It never sends explicit queries for the name servers for ce.berkeley.edu or berkeley.edu, though this information is also stored in the namespace. Sending explicit queries could cause problems: there may be no ce.berkeley.edu name servers (that is, ce.berkeley.edu may be part of the berkeley.edu zone). Also, it's always possible that an edu or berkeley.edu name server would know waxwing.ce.berkeley.edu's address. An explicit query for the berkeley.edu or ce.berkeley.edu name servers would miss this information.
2.6.3 Iteration
Iterative resolution doesn't require nearly as much work on the part of the queried name server. In iterative resolution, a name server simply gives the best answer it already knows back to the querier. No additional querying is required. The queried name server consults its local data (including its cache, which we'll talk about shortly), looking for the data requested. If it doesn't find the answer there, it finds the names and addresses of the name servers closest to the domain name in the query in its local data and returns that as a referral to help the querier continue the resolution process. Note that the referral includes all of the name servers listed in the local data; it's up to the querier to choose which one to query next.
2.6.4 Choosing Between Authoritative Name Servers
Some of the card-carrying Mensa members in our reading audience may be wondering how the name server that receives the recursive query chooses between the name servers authoritative for the zone. For example, we said that there are 13 root name servers on the Internet today. Does the name server simply query the one that appears first in the referral? Does it choose randomly?
The Microsoft DNS Server uses roundtrip time (RTT) to choose between name servers authoritative for the same zone. Roundtrip time is a measurement of how long a remote name server takes to respond to queries. Each time a Microsoft DNS Server sends a query to a remote name server, it starts an internal stopwatch. When it receives a response, it stops the stopwatch and makes a note of how long that remote name server took to respond. When the name server must choose which of a group of authoritative name servers to query, it simply chooses the one with the lowest roundtrip time.
Before a Microsoft DNS Server has queried a name server, it ranks it according to how many octets its IP address has in common with the local host's. This is designed to favor remote name servers on the same or nearby networks.
On the whole, this simple but elegant algorithm allows Microsoft DNS Servers to "lock on" to the closest name servers quickly and without the overhead of an out-of-band mechanism to measure performance.
2.6.5 The Whole Enchilada
What this amounts to is a resolution process that, taken as a whole, looks like Figure 2-13.
Figure 2-13. The resolution process
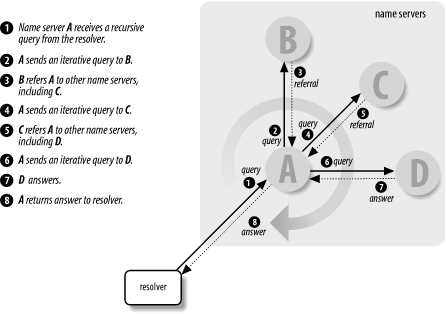
A resolver queries a local name server, which then sends iterative queries to a number of other name servers in pursuit of an answer for the resolver. Each name server it queries refers it to another name server that is authoritative for a zone further down in the namespace and closer to the domain name sought. Finally, the local name server queries the authoritative name server, which returns an answer. All the while, the local name server uses each response it receives?whether a referral or the answer?to update the RTT of the responding name server, which will help it decide which name servers to query to resolve domain names in the future.
2.6.6 Mapping Addresses to Names
One major piece of functionality missing from the resolution process as explained so far is how addresses get mapped back to domain names. Address-to-name mapping is used to produce output that is easier for humans to read and interpret (in log files, for instance). It's also used in some authorization checks. Unix hosts map addresses to domain names to compare against entries in .rhosts and hosts.equiv files, for example. When using host tables, address-to-name mapping is trivial. It requires a straightforward sequential search through the host table for an address. The search returns the official hostname listed. In DNS, however, address-to-name mapping isn't so simple. Data, including addresses, in the domain namespace is indexed by name. Given a domain name, finding an address is relatively easy. But finding the domain name that maps to a given address would seem to require an exhaustive search of the data attached to every domain name in the tree.
Actually, there's a better solution that's both clever and effective. Because it's easy to find data once you're given the domain name that indexes that data, why not create a part of the domain namespace that uses addresses as labels? In the Internet's domain namespace, this portion of the namespace is the in-addr.arpa domain.
Nodes in the in-addr.arpa domain are labeled after the numbers in the dotted-octet representation of IP addresses. (Dotted-octet representation refers to the common method of expressing 32-bit IP addresses as four numbers in the range 0 to 255, separated by dots.) The in-addr.arpa domain, for example, could have up to 256 subdomains, one corresponding to each possible value in the first octet of an IP address. Each of these subdomains could have up to 256 subdomains of its own, corresponding to the possible values of the second octet. Finally, at the fourth level down, there are resource records attached to the final octet giving the full domain name of the host at that IP address. That makes for an awfully big domain: in-addr.arpa, shown in Figure 2-14, is roomy enough for every IP address on the Internet.
Figure 2-14. The in-addr.arpa domain
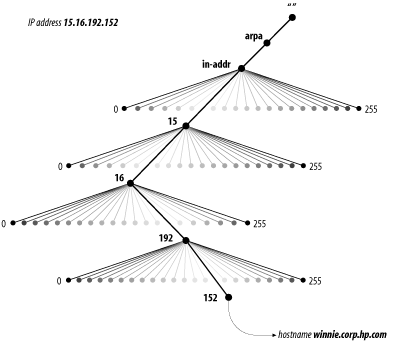
Note that when read in a domain name, the IP address appears backward because the name is read from leaf to root. For example, if winnie.corp.hp.com's IP address is 15.16.192.152, the corresponding node in the in-addr.arpa domain is 152.192.16.15.in-addr.arpa, which maps back to the domain name winnie.corp.hp.com.
IP addresses could have been represented the opposite way in the namespace, with the first octet of the IP address at the bottom of the in-addr.arpa domain. That way, the IP address would have read correctly (forward) in the domain name. IP addresses are hierarchical, however, just like domain names. Network numbers are doled out much as domain names are, and administrators can then subnet their address space and further delegate numbering. The difference is that IP addresses get more specific from left to right, while domain names get less specific from left to right. Figure 2-15 shows what we mean.
Figure 2-15. Hierarchical names and addresses
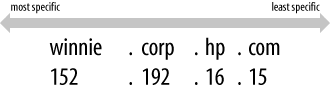
Making the first octets in the IP address appear highest in the tree gives administrators the ability to delegate authority for in-addr.arpa zones along network lines. For example, the 15.in-addr.arpa zone, which contains the reverse-mapping information for all hosts whose IP addresses start with 15, can be delegated to the administrators of network 15/8. This would be impossible if the octets appeared in the opposite order. If the IP addresses were represented the other way around, 15.in-addr.arpa would consist of every host whose IP address ended with 15?not a practical zone to try to delegate.






