15.3 Siderean Software's Seamark
Siderean Software's Seamark is a sophisticated application providing resources for intelligent site querying and navigation. The company makes use of a faceted metadata search and classification scheme for describing page characteristics. It is intended for larger, commercial applications and web sites, providing the infrastructure necessary for this type of search capability.
|

By faceted metadata, Siderean is talking about defined properties or characteristics of objects. Seamark allows searching on variations of this type of data. Once the Seamark repository is installed, it's quite simple to load data into it from external RDF/XML files. The data in these files is then combined with existing data in the Seamark database. There is no specialized Seamark RDF Schema, which means the RDF/XML can be from any vocabulary.
Aside from the repository, Seamark's second main component is what Siderean calls search models. Once these models are defined, they can then be incorporated into the navigation and search functionality of the applications based on Seamark. The query language used to define the search models is based on XRBR, XML Retrieval by Reformulation format, a query language proprietary to Siderean. Once a search is defined, Seamark can generate a customizable ASP or a JSP page that incorporates the search and to which you can add custom code as needed. Additionally, you can access the Seamark services through the Seamark API, a SOAP-based protocol.
The user interface for Seamark is quite simple, consisting of a main model/RDF document page, with peripheral pages to manage the application data. Once the application is installed, the first steps to take after starting the application are to create a model and then load one or more RDF/XML documents. Figure 15-2 shows the page form used to identify an internal RDF/XML document. Among the parameters specified is whether to load the document on a timed schedule, or manually, in addition to the URL of the file and the base URL used within the document. The page also provides space for an XSL stylesheet to transform non-RDF XML to RDF/XML.
Figure 15-2. Adding a URL for an external RDF/XML data source
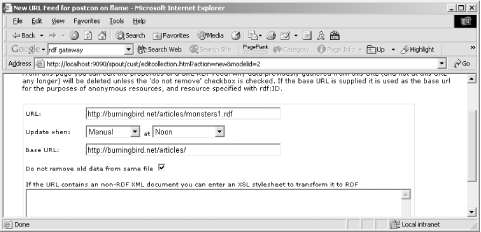
Once the external feed is defined, the data can then be loaded manually or allowed to load according to the schedule you defined.
After data is loaded into the Seamark repository, you can then create the search queries to access it. In the query page, Seamark lists out the RDFS classes within the document; you can pick among these and have the tool create the query for you or manually create the query.
For instance, the example RDF/XML used throughout the book, http://burningbird.net/articles/monsters1.rdf, has three separate classes:
- pstcn:Resource
-
Main object and any related resources
- pstcn:Movement
-
Resource movements
- rdf:Seq
-
The RDF sequence used to coordinate resource history
For my first query, I selected the Resource object, and had Seamark generate the query, as shown in Figure 15-3.
Figure 15-3. An automatically generated query in Seamark.
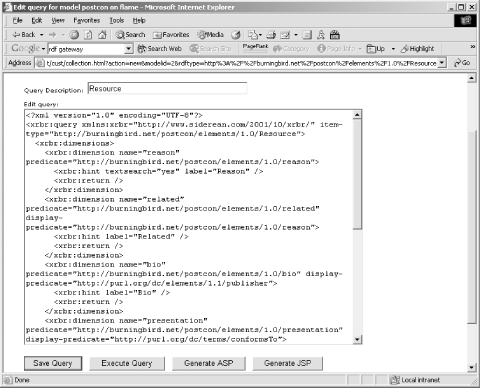
As you can see from the figure, XRBR isn't a trivial query language, though a little practice helps you work through the verbosity of the query. Once the initial XRBR is generated, you can customize the query, save it, execute it, or generate ASP or JSP to manage the query?or any combination of these options. Executing the query returns XRBR-formatted data, consisting of data and characteristics, or facets for all the Resource classes in the document. At this point, you can again customize the query or generate an ASP or JSP page.
When you add new RDF/XML documents to the repository, this new data is incorporated into the system, and running the query again queries the new data as well as the old. Figure 15-4 shows the page for the model with two loaded RDF/XML documents and one query defined.
Figure 15-4. PostCon Seamark model with two data sources and one query
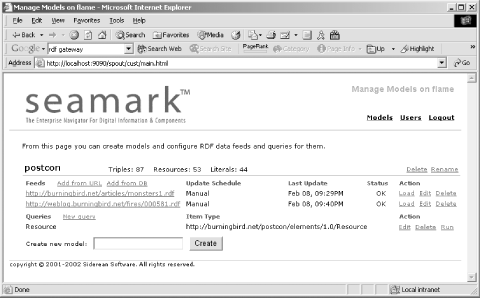
Seamark comes with a default application called bookdemo that can be used as a prototype as well as a training tool. In addition, the application is easily installed and configured and comes with considerable documentation, most in PDF format. What I was most impressed with, though, was how quickly and easily it integrated my RDF/XML data from the PostCon application into a sophisticated query engine with little or no effort. Few things prove the usefulness of a well-defined metadata structure faster than commercial viability.






