15.4 Plugged In Software's Tucana Knowledge Store
Plugged In Software's Tucana Knowledge Store (TKS) enables storage and retrieval of data that's designed to efficiently scale to larger datastores. The scalability is assured because distributed data sources are an inherent part of the architecture, as is shown in the diagram in Figure 15-5.
|

Figure 15-5. Demonstration of TKS distributed nature
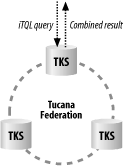
In situations with large amounts of potentially complex data, this distributed data repository may be the only effective approach to finding specific types of data. TKS has found a home in the defense industry because of the nature of its architecture and is being used within the intelligence as well as defense communities.
TKS pairs the large-scale data storage and querying with a surprisingly simple interface. For instance, the query language support (iTQL) functionality can be accessed at the command line by typing in the following command:
java -jar itql-1.0.jar
This command opens an iTQL shell session. Once in, just type in the commands necessary. I found TKS to be as intuitively easy to use as it was to install. I followed the tutorial included with TKS, except using my example RDF/XML document, http://burningbird.net/articles/monsters1.rdf, as the data source. First, I created a model within TKS to hold the data:
iTQL> create <rmi://localhost/server1#postcon>; Successfully created model rmi://localhost/server1#postcon
Next, I loaded the data from the external document:
iTQL> load <http://burningbird.net/articles/monsters1.rdf> into <rmi://localhost/ server1#postcon>; Successfully loaded 58 statements from http://burningbird.net/articles/monsters1.rdf into rmi://localhost/server1#postcon
After the data was loaded, I queried the two "columns" in the data?the predicate and the object?for the main resource, http://burningbird.net/articles/monsters1.htm:
iTQL> select $obj $pred from <rmi://localhost/server1#postcon> where <pstcn:release>
$pred $obj;
0 columns: (0 rows)
iTQL> select $obj $pred from <rmi://localhost/server1#postcon> where <http://
burningbird.net/articles/monsters1.htm> $pred $obj;
2 columns: obj pred (8 rows)
obj=http://burningbird.net/articles/monsters2.htm pred=http://burn
ingbird.net/postcon/elements/1.0/related
obj=http://burningbird.net/articles/monsters3.htm pred=http://burn
ingbird.net/postcon/elements/1.0/related
obj=http://burningbird.net/articles/monsters4.htm pred=http://burn
ingbird.net/postcon/elements/1.0/related
obj=http://burningbird.net/postcon/elements/1.0/Resource pred=htt
p://www.w3.org/1999/02/22-rdf-syntax-ns#type
obj=rmi://flame/server1#node123 pred=http://burningbird.net/postcon/elem
ents/1.0/bio
obj=rmi://flame/server1#node134 pred=http://burningbird.net/postcon/elem
ents/1.0/relevancy
obj=rmi://flame/server1#node147 pred=http://burningbird.net/postcon/elem
ents/1.0/presentation
obj=rmi://flame/server1#node164 pred=http://burningbird.net/postcon/elem
ents/1.0/history
The blank nodes are identified with TKS's own method of generating bnode identifiers, in this case a concatenation of a local server name and a specific node identifier. As you can see from this example, the TKS query language iTQL is very similar to what we've seen with RDQL and other RDF/XML-based query languages.
In addition to the command-line shell, there's also a web-based version that might be easier to use, especially when you're new. However, the basic functionality is the same.
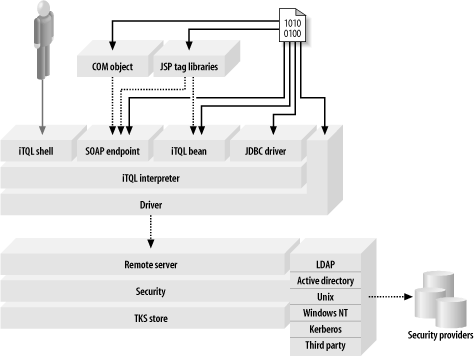
The power of TKS is accessing the services that the TKS server provides from within your own applications. For this, TKS comes with custom JSP tags for interoperating with the TKS server. In addition, you can access the services through COM objects, within a Windows environment, through SOAP, through a specialized JavaBean, and through two drivers: a JDBC driver and a native TKS driver. This makes the query capability of TKS available in all popular development environments, as shown in Figure 15-6.
Figure 15-6. Client/Server architecture supported by TKS
Bottom line: the power of TKS is just that?power. By combining a simple and intuitive interface with an architecture that's built from the ground up for large-scale data queries, the application is meant to get you up and running, quickly.






