Synchronization Fundamentals
Synchronization Fundamentals
In the previous chapter, we learned how persistent data storage enables users to access enterprise data without being connected to a network. Without enterprise synchronization, the data on the devices would quickly become stale, hence unsuitable for many corporate applications. The synchronization process allows you to execute bidirectional updates on the required data. Any changes that have been made on the client device can be transmitted to the server database, and any changes on the server can be transmitted to the client device. In this way, you can keep the data on the client and the server synchronized.
| Note |
The term replication is often used in conjunction with synchronization, leading to some confusion. Replication is the process of making a copy of something (a replica). In database terminology, replication can be used to describe two processes: first, the bidirectional transfer of data between systems, in which use it is a pseudonym for synchronization; second, the one-way copying of data from one system to another, wherein it is quite different from synchronization. To be consistent, we will use synchronization, not replication, to describe the data transfer process. |
Whether you are synchronizing over wireless networks or a wireline connection, synchronization offers many important benefits over an always-connected solution, namely:
-
Reduced data transfer over the network, often leading to reduced transmission costs.
-
Reduced loads on the enterprise server.
-
Faster data access, because the user does not have to constantly wait for data to download.
-
Increased control over data availability.
In the following pages, we will take a look at how synchronization works and introduce features you should consider as part of an enterprise synchronization solution.
The term synchronization applies to more than the movement of enterprise data. It is often used to describe the exchange of personal information management (PIM) data and the transfer of application files. This section briefly explains other types of synchronization before we spend the remainder of this chapter on the synchronization of enterprise data.
PIM Synchronization
One of the first applications that many corporations make available to mobile workers is email. This is often enabled at the same time as contact lists, to-do lists, and calendar entries. The combination of this data is commonly referred to as PIM data. Wireless access to email is often considered the killer application in the mobile world. It is a subject to which everyone can relate, and the benefits of which most people by now take for granted.
The leading PIM applications on the desktop are Microsoft Outlook and Lotus Notes. Both vendors provide mobile access to PIM data via laptops, so users are familiar with accessing this data remotely. When it comes to smaller mobile devices such as PDAs, a PIM synchronization solution is required to provide this functionality. PIM synchronization solutions allow users to have offline access to their personal information and to synchronize any changes made back into the enterprise system, often without requiring a companion PC. (For more about PIM synchronization, see Chapter 16, "Mobile Information Management," where the subject is covered in greater detail.)
File/Application Synchronization
Within an organization, a variety of applications and other files need to be distributed to mobile users. In the wired world, this information is often made available through use of portable media such as floppy disks or CD-ROMs or by a corporate server or intranet site. Unfortunately, these techniques do not work nearly as well for mobile workers. Many mobile devices do not have support for traditional portable storage media, and the storage that is available is somewhat expensive, making this an impractical means of distribution. Adding to the challenge is the fact that most users are at remote sites, without access to internal corporate systems.
To overcome these challenges, several file and application synchronization products have come to market. These products allow an administrator to deliver these files to remote workers in an automated way; they require no additional effort by the remote user. This means you can deploy and manage files and applications on remote devices, so you can quickly update remote workers with the applications they need. In most cases, this type of synchronization is one-way: Updates are sent from the server to the remote workers; only an acknowledgment receipt comes back. (More about application deployment solutions can also be found in Chapter 16.)
Data Synchronization
Data synchronization refers to the bidirectional exchange and transformation of data between two separate data stores (and is the form of synchronization that we are going to focus on for the remainder of this chapter). For our purposes, these data stores are most often located on the client device and the enterprise server. In many cases, the synchronized data set is only a subset of the enterprise database. The reason for the limitation is twofold: one, because of the limitations of most mobile devices, and, two, because individual mobile users only require data that is relevant to them.
The data transfer itself occurs between the synchronization layer on the client and the synchronization middleware on the server. The server middleware then communicates with the enterprise data source. This is the most common way that smart client applications are given access to corporate data.
Synchronization Architectures
Enterprise data synchronization is not a straightforward task. Being able to communicate with a variety of enterprise systems over wireless and wireline networks to an assortment of client applications requires some flexibility at the architectural level. Considering that there are half a dozen mobile operating systems, with at least that many networks, and even more back-end systems that have to be accessed, the synchronization layer is often one of the most complex components of a complete smart client application.
After you take a look at the most common synchronization architecture, along with common synchronization topologies and data access methodologies, you will have a good foundation from which you can make informed decisions on implementing data synchronization within your mobile solution.
Architecture Overview
Synchronization is most often implemented in a distributed computing architecture with a client layer, a middle-tier layer, and an enterprise data layer. Each layer can be implemented using varying techniques, all aimed at accomplishing the same goal: providing a way to extend enterprise data to a variety of mobile devices.
We are going to take a closer look at each synchronization component and how it contributes to the overall synchronization process.
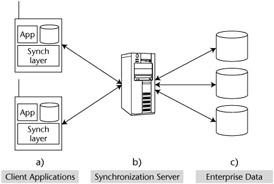 Figure 10.1: Synchronization architecture.
Figure 10.1: Synchronization architecture.
Client
When synchronizing data between an enterprise server and a persistent data store on the client device, a synchronization layer must be present to manage the two-way data communication (see Figure 10.1a). Ideally, this layer will have a minimal impact on your client application, while still providing a simple, easy-to-use client API for controlling the synchronization process. By implementing a modular, self-contained synchronization layer, you can control the entire synchronization process with little interaction from the client application. In some cases, all that is required from the client is the invocation of the synchronization process; the synchronization layer does everything else from there.
Because so many client devices are on the market, the synchronization client must have support for the leading mobile devices, including laptops, Windows CE devices, Palm OS devices, Symbian OS devices, as well as specialized devices with add-on features such as barcode scanners and other industrial components. Each of these devices can have a different mobile operating system with different network protocol support. The synchronization layer on the client takes care of the network communication from the device back to the synchronization middleware.
Middleware
The synchronization server is where most of the synchronization logic is contained. Figure 10.1b illustrates the role of the synchronization server in relation to the other components of the synchronization architecture. This server is responsible for communicating with the client application to send and receive required data packets. In order to do this, it has to be able to communicate over a protocol that the client application understands. Most of the time, this protocol is IP-based, and often is HTTP. When the synchronization server receives the data from the client, it then has to execute the synchronization logic to determine how this data is transferred into the enterprise data source.
Many of the advanced synchronization features are implemented within the synchronization server. Some of these features include data subsetting, conflict detection and resolution, data transformation, data compression, and security. All of these features have to be implemented while still maintaining server performance and scalability.
Two common synchronization server implementations exist: as a standalone server application, or as Java servlets running in a servlet engine. Both of these methods have benefits and drawbacks. The standalone synchronization server is convenient because it does not require any additional software to execute. These servers are usually programmed using the C programming language, taking advantage of OS-level calls, leading to enhanced performance. This also means that the server has to be available for the operating system to which you are deploying or you are out of luck. In terms of scalability and availability, the server can either have its own built-in load-balancing and failover mechanisms or use third-party load-balancing solutions, such as the hardware-based systems provided by Cisco systems.
For Java servlet-based synchronization servers, you will need a servlet engine for deployment. Since J2EE application servers are now commonplace in most organizations, this requirement does not usually pose a problem. By using an outside servlet engine, the performance, scalability, and availability of the synchronization server now rely on the capabilities of the application server/servlet engine being used. The same goes for the server operating systems that are supported; that is, as long as the servlet engine works on a given platform, the synchronization servlet should work as well. That said, you should give extra consideration to the synchronization vendor's supported platforms and recommended application servers when deciding which application server and operating system to use. (More information on the various features of synchronization middleware is provided later in this chapter in the section entitled Key Features of Synchronization.)
Enterprise Integration
The final part of a complete synchronization solution is the enterprise integration layer. While this layer is often part of the synchronization server, we are discussing it separately because it provides different functionality. The enterprise integration layer enables you to communicate with various back-end data sources. If you are using a commercial mobile relational database on the client, you will most likely have integration to enterprise relational databases on the server using ODBC, JDBC, or native drivers.
| Note |
Many of the mobile database vendors only have synchronization for their own enterprise database on the server. If you have multiple server databases, this can be a cause for concern. More information on commercial solutions is provided later in this chapter, in the section entitled Commercial Synchronization Solutions. |
In addition to providing integration to relational databases, you may also require access to other forms of enterprise data, such as ERP systems, CRM systems, or XML data. If this is the case, you will have to look for additional enterprise adapters for the solution you are implementing; or if you have the resources, you can create your own adapter.
Publish/Subscribe Model
One of the most common models of data access being used by synchronization solutions today is the publish/subscribe model, so it is worthwhile to explore how it works.
The publish/subscribe synchronization model is based on the concept of having a master copy of your data, the publisher, and one or more copies of this data, the subscriber(s). The data between the publisher and subscribers is updated periodically to keep the data consistent. The update process, or synchronization, is bidirectional, allowing the publisher to update the subscriber data, and vice versa.
The publisher is responsible for defining which tables (or subsets of those tables) are available for external access. The data sets that are defined as being available are called publications. The application clients that are interested in having access to that information are called subscribers. They define which data they want access to using subscriptions. It is possible to have a number of publications defining the available data. These publications can have parameters, which makes it possible to use different subsets of data for different users. In this way, one publication can be used to send a different subset of data to each subscriber.
Figure 10.2 shows an example of a field service application's data set. In this diagram, you can see that the publisher has the complete set of master data. This data contains all of the information for each field service representative. In this example, the field service representatives are the subscribers. They require only the subset of the publisher's data that pertains to their territory, so rather than keeping a copy of the entire set of data, they have a subset of data that is based on their individual subscriptions. In this way, you can easily define which data is available for mobile users and which parts of the data needs to be synchronized down to the mobile devices.
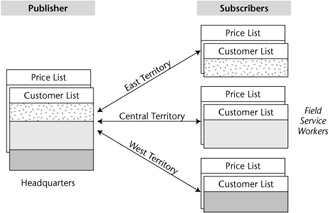
Figure 10.2: Publish/subscribe data synchronization.
Common Synchronization Configurations
A variety of network and data management configurations are commonly used with enterprise synchronization. Synchronization configurations (or topologies) are arrangements of publisher and subscriber databases that transmit data to one another. The publish/subscribe model of data access supports both peer-to-peer and hierarchical configurations.
The most common of these two is the hierarchical configuration, wherein every database has a single parent database, except for the master enterprise database, which has no parent. A diagram of common hierarchical layouts can be seen in Figure 10.3. In this diagram are two hierarchical configurations: the configuration on the right is commonly referred to as a hub-and-spoke configuration. In both cases, hierarchical configurations are good when a publisher needs to publish data to a large number of subscribers, or, in other words, when there are a large number of remote workers who need to have access to the enterprise data. In this configuration, the master database contains all of the changes made by any of the remote databases. Those updates can then be propagated to the other remote databases during their next synchronization.
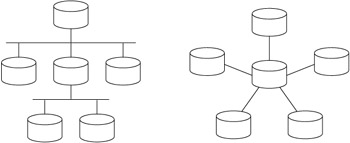
Figure 10.3: Hierarchical database configurations.
Unlike the hierarchical configuration, peer-to-peer configurations do not have a single common enterprise data store. In Figure 10.4 you can see that peer-to-peer configurations enable each database to contain the same information, with no single database acting as a central server. In this configuration, you can still use the publish/subscribe model, but the data updates are not going to be propagated to all databases in the configuration. For this reason, peer-to-peer configurations are best suited for situations in which only two systems need to be synchronized, or when it is not important for each remote user to have the updates from all other users. In general, a peer-to-peer configuration is not recommended, because there is no central server responsible for collecting updates from the remote users and propagating those changes to the other users in the system. Other difficulties of peer-to-peer configurations include maintaining data integrity, implementing conflict detection, and programming synchronization logic.
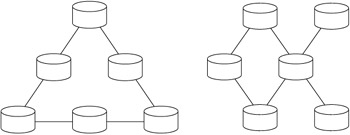
Figure 10.4: Peer-to-peer database configuration.
The Data Synchronization Process
As demonstrated by the synchronization architectures, there are many ways in which a remote database can be synchronized with the enterprise data source. To simplify things, we are going to take a look at a basic synchronization process as the foundation for our discussions on the various synchronization architectures and techniques.
To simplify the synchronization process to a generic level, we have to make a few assumptions about this particular solution, namely:
-
We are only synchronizing the changed data, to minimize data transferred.
-
We have a synchronization layer on the client.
-
We are using synchronization middleware.
-
We have a network connection available during the synchronization process.
-
The synchronization is bidirectional, and both sets of changes occur during a single synchronization session.
We'll go through each of the steps of the synchronization process shown in Figure 10.5 and explain what happens at each step. In our example, the synchronization process is going to be initiated from the client device.
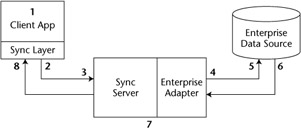
Figure 10.5: Basic synchronization process.
-
The application user can initiate the synchronization process manually, or it can be programmed into the application. At the point where the synchronization is initiated, the data that has changed since the last synchronization is prepared for sending to the synchronization server. This data preparation often involves compressing the data and, optionally, encrypting the data.
-
Once the data is prepared, a connection is established with the synchronization server. At this point, the user is usually authenticated with the server; the data packets are then sent over the communications network (wireless or wireline) to the synchronization server.
-
The synchronization server receives the data to be synchronized. It then uses the synchronization logic to determine whether the data needs to be transformed before it is sent to the enterprise data source. If it does, transformation can occur at this time.
-
The enterprise adapter provides integration to the enterprise data source. This adapter may simply be an ODBC or JDBC driver for enterprise relational databases, or custom code for other more complex data sources.
-
Using the appropriate enterprise adapter, the synchronization server can authenticate the user against the enterprise data source (optional) before it starts the data transfer. Once the user is authenticated, the server can update the enterprise data source with the changes from the client application. At this time, the synchronization server can also detect if there are any conflicts in the data being updated and, if there are, take appropriate action.
-
After the update has been committed, the relevant changes that took place on the server since the last synchronization are prepared for sending back to the client application.
-
The synchronization server takes the enterprise data source's changes and performs any transformation that may be required before sending the updates to the client application. Again, this data is usually compressed and possibly encrypted for additional security.
-
The data is sent to the client application, where it is updated in the mobile data store.
This example uses a straightforward synchronization architecture that is common to many of the synchronization solutions on the market today. It covers only one synchronization methodology, but it can easily be adapted to fit other synchronization architectures and techniques that we are going to cover in the upcoming sections.
Synchronization Techniques
The synchronization solutions available today use many techniques to move data from client applications to enterprise servers. Each of the techniques provides value for certain situations, but not every technique will be right for your particular application. When implementing your synchronization layer, keep these techniques in mind to ensure that your solution is as efficient as possible for your application.
Synchronization Modes
There are two main modes of synchronization: snapshot and net change. To determine which mode is most appropriate, you will need to consider how frequently the data will be synchronized and how many changes to data occur between synchronizations. When using a wireless network for communication, keep the data transferred to a minimum, which will help increase efficiency and reduce costs.
Snapshot
Snapshot synchronization makes it possible to move large amounts of data from one system to another. It involves deleting a table on one system and copying a table from another system in its place. The result is two tables with identical data sets.
This form of synchronization is used when there are moderate to large amounts of data that need to be synchronized or when data is not changed at the remote location. Additionally, due to the large amount of data being transferred, it is best suited for reliable networks with high bandwidth.
Snapshot synchronization is a suitable candidate for instances where a complete, or nearly complete, set of data has to be transmitted. An example might be a salesperson who requires updated product catalogues or price lists. The main office can send these updates via a snapshot so that all the data is updated to the remote worker at once. Since the remote worker will not be making changes to the remote product list, no data will be lost.
Net Changes
For most mobile applications, a net change mode of synchronization is more efficient than using snapshot synchronization. In these cases, only the changed data is sent between the remote and enterprise databases, saving network bandwidth and reducing connection times. In order to accomplish this, the remote database keeps track of the original data and the most recent change that has occurred since the last synchronization. In this way, even if the data were to change several times on the client, only the original data and most recent data have to be transmitted to the server. The changes to the enterprise data source can then happen in a single transaction since there is only one update to be made. The same approach is taken when the server database is updated and synchronized to the remote database.
This form of synchronization is well suited for applications in which the user may synchronize several times in a day, sending only small amounts of data each time. It is ideal for coping with the bandwidth limitations on most of today's wireless networks. It is also a good technique for situations in which larger amounts of data are synchronized less frequently.
The net change mode does have one drawback: If you require knowledge of each individual transaction that occurred to the data, then keeping track of only the most recent change may not be suitable for you. In this case, you might find a transaction log-based synchronization approach to be more appropriate. This approach is discussed in the Key Features of Synchronization section later in the chapter.
Data Propagation Methods
The way data is transmitted to and from the remote database can have a major impact on the effectiveness of the application. Therefore, the application designer should take care to synchronize the data in such a way that it is not too intrusive. Ideally, the application will be able to synchronize without user involvement. This capability is possible over wireline networks but often difficult over wireless networks, as most of them require a manual connection to go online.
There are two types of data propagation methods: session-based and message-based. In the following paragraphs, we will take a look at how each of these methods works and the types of synchronization for which each is best suited.
Session-Based Synchronization
Session-based synchronization requires a direct communication stream between the remote and enterprise database systems. The data synchronization happens in real time over a wired or wireless network. During this connection, both the client and server data can be updated, and the updates can be confirmed.
This form of synchronization is similar to a telephone call: Once a connection is made, data is sent in both directions until the conversation is complete; once the data has been communicated, the session is closed. If, for some reason, the communication link goes down during the data transfer, a new connection can be made, and the synchronization can continue from a suitable point. To ensure no data is lost, this point is often at the last committed transaction.
By using a session-based synchronization method, you can make sure that data is synchronized at specified times. For example, if you know that every Friday at 5:00 P.M. you need to have the latest sales information, you can schedule synchronization at this time, and you know that once it is complete, the data on both sides is up to date.
Message-Based Synchronization
Synchronization can also be executed using a message-based system. For this method of synchronization, the data updates are communicated asynchronously using messages that contain a destination address and other control information, eliminating the need for a direct connection to the enterprise system. Instead of requiring a connection over protocols such as TCP/IP, HTTP, or other wireless connections, the data can be transferred over common messaging protocols such as Simple Mail Transfer Protocol (SMTP), File Transfer Protocol (FTP), or any other proprietary messaging system.
This allows the data synchronization to use a store-and-forward mechanism to get the data to and from the database systems. This capability is often provided by the underlying messaging protocol and does not have to be implemented directly into the synchronization layers.
Message-based synchronization works in the same way as an email system. When you want to send a message to someone, you specify the destination address and write a message to send. Once it is sent, you no longer have any control over what happens to it. At some point in the future, maybe a minute, maybe an hour, maybe several days, the email message is read and acted upon. For synchronization, the action is to take the message and perform the required updates to the target database system. Once this is complete, a response may be sent containing a synchronization update in the other direction.
Message-based synchronization systems are well suited for architectures that do not allow for a direct connection between the client and the server databases, that support an extremely large number of remote users, or where a network connection is not available or is unreliable. Direct connections are not possible in many security configurations due to firewall implications. In these situations, you can implement messagebased synchronization such that it offers guaranteed delivery. In this way you can be sure the data will reach its destination. The obvious drawback to message-based synchronization is that you do not have control over when the synchronization takes place. If you require a solution that enables data to be synchronized at specific times, session-based synchronization may be more appropriate. (For more information on messaging within mobile and wireless applications, see Chapter 5, "Mobile and Wireless Messaging.")
Key Features of Synchronization
Now is a good time to take a closer look at some of the key features that will prove useful in a synchronization solution. Not all synchronization solutions will contain all of these features, but the solution you choose should, minimally, contain those that relate to the application you are building. Alternatively, if you decide to build your own synchronization system, this section will give you an idea of some of the challenges that lie ahead.
Data Subsetting and Partitioning
The database on the server will contain much more data than is required for the mobile application. For this reason, only a subset of the database should be able to be synchronized to the mobile device. This capability can successfully be accomplished in two ways. First is by limiting the mobile application to include only the portion of the database schema that is relevant to the mobile user. This process will remove any tables that are not applicable, thereby reducing overhead. Once this reduction is accomplished, the second way is to minimize the amount of data being synchronized to those tables.
Data partitioning is the technique used to minimize the synchronized data. There are two forms of data partitioning: column partitioning and row partitioning. Column partitioning means that you will only take the required columns from the table being synchronized. You determine which columns are required by looking at the data displayed to the user and the data the application uses internally. Once you know which columns are required, you may be able to further reduce the data by implementing row partitioning. This means that you will only want to synchronize the rows of data that are required by the specific user doing the synchronization. This can be accomplished by setting up a filter to user subscriptions. For example, if I am a field service representative, I only want to synchronize the data that pertains to the work orders that I will be handling myself. I do not require the rows of data for all of the other technicians in my company. By doing this, I will dramatically reduce the amount of data that has to be stored on my device and that I will have to synchronize to the server database. Side benefits of this technique are that there is a smaller chance of running into conflicts when remote users have distinct subsets of data, plus improved synchronization performance.
Data Compression
Another way to reduce the number of bytes being transferred is by implementing a compression routine. Data compression optimizes the data stream being sent over the network. In a wireless environment, this will reduce synchronization times and costs. The one caveat is that compressing and decompressing data adds extra overhead to the synchronization process on both the client device and synchronization server. This is only a concern, however, on handheld devices that have minimal resources. It is important to note that some data types can be compressed much more than others, so the benefits of compression are dependent on the data being synchronized.
Data Transformation
At times, the data in the enterprise database may not be in the ideal format for your mobile application. In these cases, the data may need to be transformed from one data type to another during synchronization. You may want to transform the data to save space on the client device, by, for example, changing text fields from fixed-length to variable-length. In other cases, you may need to transform the data because the mobile database does not support a given data format. For example, if the client database does not have support for floating-point numbers, these numbers may have to be changed to character representations so they can be displayed on the client.
Transactional Integrity
Databases attempt to maintain what are called atomic, consistent, isolated, durable (ACID) transactions. Maintaining transactional integrity means that the execution of a transaction will ensure that either all of the changes or none of the changes are committed at the same time to maintain database consistency. In addition, the transaction should occur in isolation, that is, not be affected by other transactions that may be occurring. Finally, once the transaction is committed, its effects are persistent, even in the event of future system failures.
Maintaining ACID transactions in mobile and wireless computing is even more difficult. With unreliable wireless networks, and a potentially large number of remote users, it is important for the synchronization layer to maintain transactional integrity at all times. If any part of a remote transaction fails, the entire transaction must be rolled back, and the data has to be kept in a consistent state. The client has to then reapply the transaction during the next synchronization.
With many of the systems implementing a net change approach to database updates, the net changes have to be synchronized in the context of a database transaction. If an organization requires each individual transaction to be committed in the order it occurred, then a log-based system may be required. In this case, all of the transactions performed on the remote database are stored in a transaction log, and during synchronization, the transaction log is read in chronological order, executing each database change individually. While this may appeal to some organizations, it does add additional overhead to maintain and transmit what could potentially be a large file.
Conflict Detection
A conflict occurs when two users attempt to update the same data field with different values. For example, let's say that two sales representatives attempt to update a contact's email address to a new value. Both users have access to the contact information remotely, in offline mode. The first sales representative can update the data to the enterprise server without any issue. When the second sales representative executes his or her update, a conflict will arise because the data was altered since the last time the data was synchronized. When you have multiple databases updating the same fields of data from different locations, a conflict is sure to happen when the data is synchronized to a central location.
The best way to handle conflicts is to design the database schema and data subsetting and partitioning configurations in such a way that a conflict will rarely occur. If this is not an option, the synchronization middleware has to handle them in an acceptable manner. The first step in solving a conflict is detection. For this to happen, the application or, more likely, the synchronization layer, must store both the original and new values of data for each row being updated. In this case, when data is being updated, the synchronization logic can check to see if the original value from the client matches the current value in the enterprise database. If they do, there is no conflict, since the data being updated has not changed since the last synchronization. If, on the other hand, the values do not match, it means that another user has updated the data since the last synchronization, and a conflict has occurred.
Most synchronization solutions do offer conflict-detection capabilities; but it is what happens next that really matters: conflict resolution.
Conflict Resolution
Once a conflict has been detected, it has to be resolved. This can be accomplished automatically, by implementing some predefined rules, or programmatically, by allowing the developer to apply custom business rules to resolve the conflict.
The most common resolution methods include last-in wins and first-in wins. Both of these can easily be implemented based on the user performing the synchronization. When a transaction is rolled back because of a conflict, a mechanism should be in place to tell the user why the transaction failed, so he or she can correct the problem or, possibly reapply the change.
In the case of custom conflict resolution, the system should allow developers to program the logic in a language familiar to them. When the enterprise data source is a relational database, the most obvious solution is for the synchronization logic to use SQL, the same language that is used for other database interactions. Custom resolution logic may involve notifying an administrator of the conflict, or executing some predefined logic in a stored procedure.
A conflict can also be resolved by evaluating and working with the current data. Let's use the example of the sales representatives again. In this scenario, the representative (let's call him Rep 1) has sold 100 units of product A, and another representative (Rep 2) has sold 50 units of the same product. When Rep 1 synchronizes his data, the remaining inventory value in the enterprise database will be reduced by 100 units. When Rep 2 synchronizes her data, a conflict will occur because her remaining inventory value will not be the same as that in the enterprise database. This conflict can be resolved by reducing the remaining inventory value in the enterprise database by 50. In this scenario, last-in and first-in wins do not make sense, so custom logic is required. The only situation where a problem with this system might arise is when the inventory level goes below zero, in which case either more products have to be ordered or the sales representatives have to be notified.
Network Protocol Support
Data synchronization can occur over one of many different networks, so having support for multiple network protocols is important. The client application may synchronize over a wireless connection, using CDPD, GPRS, CDMA or TDMA, or it may be over a wireline network using TCP/IP. In addition to being compatible with the given protocol, a synchronization solution should also be able to manage the connections. For example, if a wireless connection is dropped, the synchronization layer has to be able to either reconnect and continue the synchronization or notify the user to let him or her know that the transaction will have to be restarted. In the case of a dropped connection, the less data that must be re-sent, the better.
For any synchronization system, at a minimum, you will want to have support for the most common protocols such as TCP/IP and HTTP, or, in the case of message-based synchronization, FTP, email, or even physical media such as floppy disks or CD-ROMs. If your particular application will be deployed over networks using other protocols, then you will want to ensure that they are supported as well. Bluetooth is a good example of a protocol for which you may require support in the future.
Multiple Transport Mechanisms
Smart client applications do not require a wireless connection for synchronization. They can use other data transport mechanisms that may be available. In Figure 10.6 we can see some of the possible synchronization scenarios that may be required. They include the following:
-
Direct synchronization through an integrated wireless modem.
-
Synchronization through a cellular phone. The device may communicate to the cell phone using a cable infrared or Bluetooth.
-
Through an integrated wireless LAN card, possibly using 802.11b or Bluetooth.
-
Through a mobile device with a modem that is connected to a regular telephone line that uses a regular ISP to connect to the Internet.
-
Through a device in a cradle that is using a companion PC for synchronization. The device may communicate with the PC using IR, a serial cable, or a USB cable. The PC can then communicate to the synchronization server using TCP/IP or HTTP.
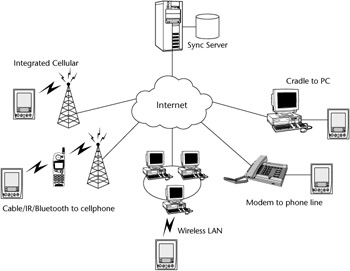
Figure 10.6: Synchronization over a variety of transport mechanisms.
Enterprise Integration
To access the enterprise data in your organization, the synchronization server has to be able to communicate directly with your enterprise data sources. In some cases, this may only involve accessing a single enterprise database, but very often, there is a need for access to multiple databases. Even if you do not currently require this, having the capability to synchronize with other databases gives you some protection that your investment will still be useful if other data has to be accessed. For relational databases, the synchronization server should have either JDBC or ODBC access to the following leading databases:
-
Oracle
-
IBM DB2
-
Microsoft SQL Server
-
Sybase Adaptive Server Enterprise (ASE)
-
Sybase Adaptive Server Anywhere (ASA)
In addition to relational databases, you sometimes need access to other enterprise data sources, such as ERP or CRM systems. To accommodate these enterprise applications, the ability to implement custom adapters is necessary.
Security
As in any enterprise solution, security is always a concern. Within the synchronization component of smart client applications, there are several security layers that need to be addressed, namely:
-
Authentication. A user can be authenticated at several locations during the synchronization process. These include the client application, the synchronization server, the database server, and the operating system. You may not require all of these authentication layers, but you should at least consider one that is managed at the server, such as using the database or the server operating system.
-
Authorization. Once a user is authenticated, you can set up access control lists based on individual users. In this way, you prevent users from accessing data that they are prohibited from accessing. This can be accomplished at a user level or by implementing authorization groups such as user, manager, and administrator. Very often authorization is implemented via synchronization logic as well.
-
Encryption. The data being transported should support some form of encryption to prevent unwanted parties from "listening" to your data stream. For many smart client applications, this can be accomplished using dedicated security libraries such as Certicom's 128-bit Elliptic Curve Cryptography (ECC). If this is not available, then SSL or other encryption routines are available.
For more information about security in mobile and wireless computing, refer back to Chapter 6, "Mobile and Wireless Security."








