Types of Table Relationships
Table relationships come in several forms:
One-to-one relationships
One-to-many relationships
Many-to-many relationships
|
|
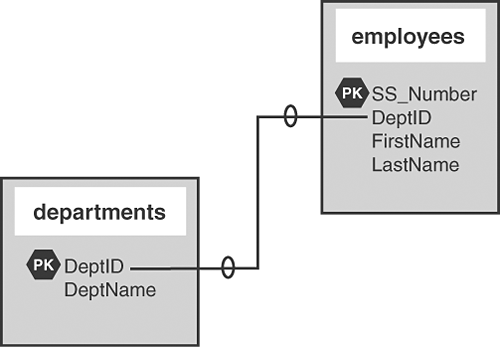
For example, suppose you have a table called employees that contains each person's Social Security number, name, and the department in which he or she works. Suppose you also have a separate table called departments, containing the list of all available departments, made up of a Department ID and a name. In the employees table, the Department ID field matches an ID found in the departments table. You can see this type of relationship in Figure 14.1. The "PK" next to the field named stands for primary key, which you'll learn about during this hour. |
Figure 14.1. The employees and departments tables are related through the DeptID.
In the following sections, you will take a closer look at each of the relationship types.
One-to-One Relationships
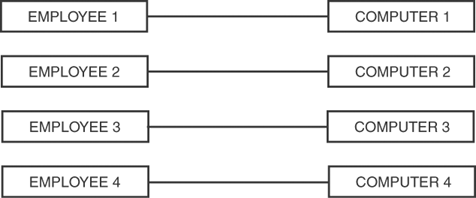
In a one-to-one relationship, a key appears only once in a related table. The employees and departments tables do not have a one-to-one relationship because many employees undoubtedly belong to the same department. A one-to-one relationship exists, for example, if each employee is assigned one computer within a company. Figure 14.2 shows the one-to-one relationship of employees to computers.
Figure 14.2. One computer is assigned to each employee.
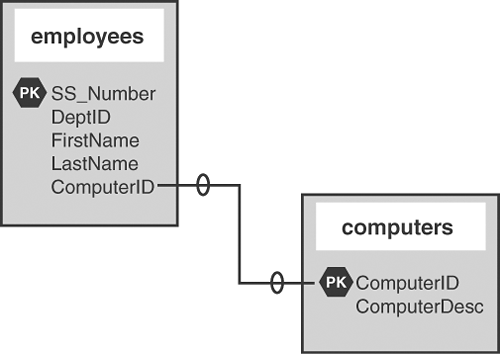
The employees and computers tables in your database would look something like Figure 14.3, which represents a one-to-one relationship.
Figure 14.3. One-to-one relationship in the data model.
One-to-Many Relationships
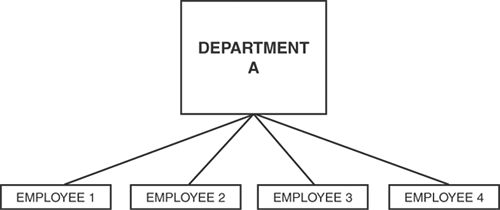
In a one-to-many relationship, keys from one table appear multiple times in a related table. The example shown in Figure 14.1, indicating a connection between employees and departments, illustrates a one-to-many relationship. A real-world example would be an organizational chart of the department, as shown in Figure 14.4.
Figure 14.4. One department contains many employees.
The one-to-many relationship is the most common type of relationship. Another practical example is the use of a state abbreviation in an address database; each state has a unique identifier (CA for California, PA for Pennsylvania, and so on), and each address in the United States has a state associated with it.
If you have eight friends in California and five in Pennsylvania, you will use only two distinct abbreviations in your table. One abbreviation represents a one-to-eight relationship (CA), and the other represents a one-to-five (PA) relationship.
Many-to-Many Relationships
The many-to-many relationship often causes problems in practical examples of normalized databases, so much so that it is common to simply break many-to-many relationships into a series of one-to-many relationships. In a many-to-many relationship, the key value of one table can appear many times in a related table. So far, it sounds like a one-to-many relationship, but here's the curveball: The opposite is also true, meaning that the primary key from that second table can also appear many times in the first table.
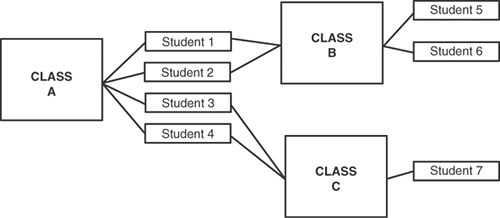
Think of such a relationship this way, using the example of students and classes. A student has an ID and a name. A class has an ID and a name. A student usually takes more than one class at a time, and a class always contains more than one student, as you can see in Figure 14.5.
Figure 14.5. Students take classes, classes contain students.
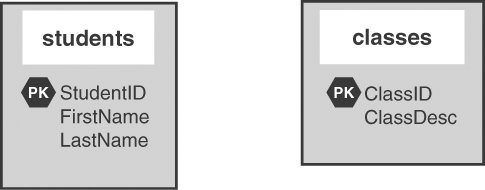
As you can see, this sort of relationship doesn't present an easy method for relating tables. Your tables could look like Figure 14.6, seemingly unrelated.
Figure 14.6. The students table and the classes table, unrelated.
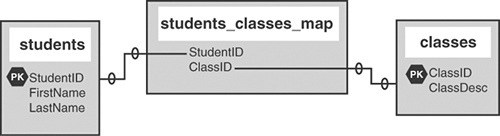
To make the theoretical many-to-many relationship, you would create an intermediate table, one that sits between the two tables and essentially maps them together. You might build one similar to the table in Figure 14.7.
Figure 14.7. The students_classes_map table acts as an intermediary.
If you take the information in Figure 14.5 and put it into the intermediate table, you would have something like Figure 14.8.
Figure 14.8. The students_ classes_map table populated with data.
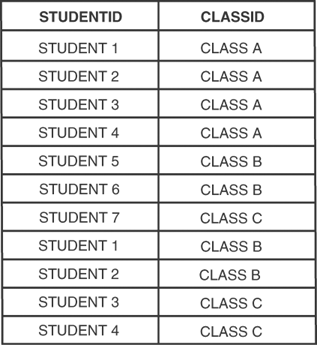
As you can see, many students and many classes happily coexist within the students_classes_map table.
With this introduction to the types of relationships, learning about normalization should be a snap.







