Types of Database Objects
A DB2 database is composed of data, indexes, and LOB and Long Varchar objects. When a table is created, the data object for the table is automatically created by DB2. If there are any indexes, primary keys, or unique constraints defined on the table, an index object will also be created. If the table contains one or more LOB columns, a LOB object will be created, and if the table contains one or more Long Varchar columns, a Long Varchar object will be created.
Tables
A table consists of data logically arranged in columns and rows. Users access the data by referring to its content instead of its location or organization in storage.
As we discussed early in this chapter, database partition groups are created within a database. Table spaces are created within database partition groups, and when tables are created, the name of the table space where the table objects will be created can be specified. If the database is partitioned, the rows of the table are distributed across the database partitions, based on the partition group's partitioning map, via a hashing algorithm.
Partition Maps
As shown in Figure 2.11, DB2 uses a hashing algorithm to assign a given row of a table to a corresponding database partition. When a table is created, a partitioning key is defined for that table. This partitioning key consists of one or many columns. (See "Partitioning Keys," later in this chapter for more details.) DB2 uses the value of the partitioning key for a given row as the input for the hashing function, and the output of the hashing function is a displacement into the partitioning map. The partitioning map is an array of 4,096 entries, each entry containing a database partition ID. The value at the specified position (displacement) in the partition map is the database partition ID where the row will be stored. Figure 2.11 shows an example of this process.
Figure 2.11. Hashing data rows using a partitioning map.
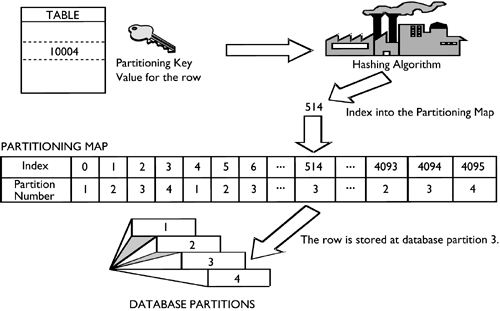
Based on the example above, a row is inserted into the table with a partitioning key value of 10004. This value is then used as input for the hashing algorithm. When the value of 10004 is hashed, the output of the algorithm is 514. DB2 then selects the value at offset 514 in the partitioning map as the database partition where the row will be stored. In this case, the row will be stored in database partition number 3.
A partitioning map is an array (or vector) of 4,096 database partition numbers. Each partitioning map corresponds to only one database partition group and is created when the database partition group is created (or when data is redistributed).
NOTE
All tables in a database partition group will use the same partitioning map.
Figure 2.12 shows three additional examples of partitioning maps. A partitioning map normally consists of an array of 4,096 elements (starting at element number 0) and is formed of two rows: The first row represents the element of the array?which ranges from 0 to 4,095?and the second row is the value at that element in the array, which is a database partition number.
Figure 2.12. Database partition map examples.
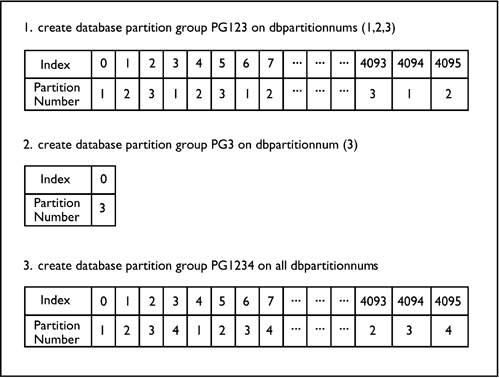
In the first example, partition group PG123 is created on database partitions 1, 2, and 3. Therefore, the default partitioning map is created containing only these database partitions.
In the second example, a single-partition partition group is created. The partition map, therefore, has only one entry because all of the data rows will be stored in the same database partition. In this example, this is database partition 3.
In the third example, a partition group is created, spanning all partitions in the database (i.e., database partitions 1, 2, 3, and 4). The partitioning map associated with this partition group will then contain all of these database partition numbers.
The partitioning map is created when a partition group is created, and it is stored in the SYSCAT.PARTITIONMAPS catalog view.
The default partitioning map contains the database partition numbers of the partition group assigned in a round-robin fashion, as shown in Figure 2.12. It is also possible to create and use partitioning maps that do not use this round-robin system. These maps are known as customized partitioning maps and may be required to achieve an even distribution of the table's data across the database partitions used by the table.
The utility db2gmap can be used to extract and display the partitioning map of a partition group from the SYSCAT.PARTITIONMAPS catalog view. To extract the partitioning map for the partition group PG123 depicted in Figure 2.12 and write it to the file PG123map.txt, use the following command:
db2gpmap -d <database_name> -g PG123 -m PG123map.txt
The first eight lines of the output file (PG123map.txt) generated by the db2gpmap utility would look like the following:
1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3 1 2 3
The upper left corner corresponds to the partition ID at element 0 of the partitioning map. The map is read by moving to the right and down, line by line.
The Relationship Between Partition Groups, Table Spaces, and Tables
In a partition database, a table will span all of the database partitions in its partition group. A table cannot span more than one partition group, but multiple tables can exist in the same partition group. Figure 2.13 shows the relationship between partition groups, table spaces, and tables.
Figure 2.13. Tables, table spaces, and partition groups.
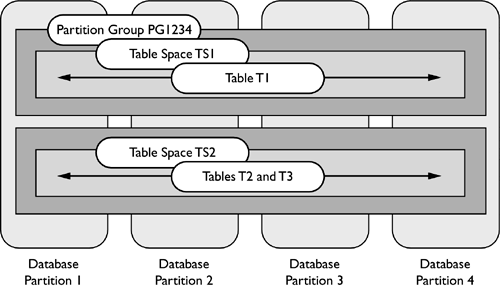
The figure shows that the tables T2 and T3 are in the table space TS2, and the table space TS2 is in the partition group PG1234. The table spaces TS1 and TS2 both span all four database partitions, because the partition group PG1234 is created on all four database partitions.
Partitioning Keys
The element that determines how the rows in a table are allocated among the database partitions is the table's partitioning key. The partitioning key for a table is a subset of the columns of the table and is defined when a table is created within a partitioned database.
For tables created in database partition groups containing more than one database partition, the partition key cannot be changed. If no partitioning key is explicitly specified, the first column that is not a Long Varchar or LOB will be used as the partitioning key.
NOTE
Tables containing only LOB and/or Long Varchar columns cannot have partitioning keys and can be placed into only single-partition partition groups.
Choosing a Partitioning Key
The following considerations should be taken into account when choosing a partitioning key for a table:
Include frequently used join columns.
Use the smallest number of columns possible.
The column(s) should have a high proportion of different values.
Integer columns are more efficient than character columns, which are more efficient than decimal columns.
Long Varchar and LOB columns fields cannot be part of the partitioning key.
The primary key or any unique index must include the partitioning key.
Specifying the Partitioning Key
If the partitioning key is not explicitly specified in the create table statement and the table is being created in a multiple-partition database partition group, the partitioning key will be defined as follows:
If a primary key is specified, the first column of the primary key is the partitioning key.
If the table is a typed table, the object identifier column will be the primary key.
Otherwise, the first column whose data type is not a LOB, LONG VARCHAR, LONG VARGRAPHIC, DATALINK column, distinct type based on one of these types, or structured type column is the partitioning key.
If none of the columns satisfy the requirements described above, the table will be created without a partitioning key, and it can be created only in a table space defined on single-partition database partition groups.
For tables in table spaces defined on single-partition database partition groups, any collection of non-long (i.e., not Long Varchar, not LOB) columns can be used to define the partitioning key. If the partitioning key is not explicitly specified, no partitioning key will be created.
Partitioning Key Examples
To determine the partitioning key used for an existing table, use the following statement:
select colname, partkeyseq from syscat.columns where tabname='<table_name>' order by partkeyseq
The following examples will show how the partitioning key for a table can be specified, and if not specified, how DB2 will choose the partitioning key. The examples will show the create table statement, followed by the partitioning key.
create table <table_name> (c1 varchar(30), c2 int, c3 char(10), c4 int) partitioning key (c2)
partitioning key c2
create table <table_name> (name char(30), ID int, email varchar(50)) partitioning key (ID)
partitioning key ID
create table <table_name> (name char(30), ID int, email varchar(50))
partitioning key name
create table <table_name> (description longvarchar(3000), ID int, email varchar(50))
partitioning key ID
create table <table_name> (name char(30) not null, ID int not null, email varchar(50), primary key (ID))
partitioning key ID
[View full width]create table <table_name> (name char(30) not null, ID int not null, email varchar(50),primary key (ID, name))
partitioning key ID
For tables T1 and T2 with the following columns:
T1 T2 ----------- ----------- C1 int C1 char(10) C2 char(10) C2 int C3 real C3 real
To support the following SQL statement without needing to send data between partitions:
select t1.c, t1.c3 from t1, t2 where t1.c2=t2.c1
The partitioning key for table T1 should be c2, and the partitioning key for table T2 should be c1. To create the tables with these partitioning keys, the following statements can be used:
create table T1 (c1 int, c2 char(10), c3 real) partitioning key (c2) create table T2 ( c1 char(10), c2 int, c3 real) partitioning key (c1)
Because the column c1 would be the default partitioning key for table T2, the partitioning key does not need to be explicitly specified. However, it is always good practice to explicitly specify the partitioning key when a table is created.
Changing the Partitioning Key
Once a partitioning key has been specified for a partitioned table, it cannot be changed. To change it, the table's data would need to be exported, the table dropped and recreated, and the data reloaded. For a table in a single-partition database partition group, the partitioning key can be changed by dropping the existing partitioning key and creating a new partitioning key, as follows:
alter table <table_name> drop partitioning key alter table <table_name> add partitioning key(<column,column,…>)
For example, for the following table in a nonpartitioned database partition group:
create table T2 ( c1 char(10), c2 int, c3 real) partitioning key (c1)
To change the partitioning key to be column c2, use the following statements:
alter table T2 drop partitioning key alter table T2 add partitioning key(c2)
If an attempt is made to drop the partitioning key of a table created in a multi-partition database partition group, the following error will be returned:
SQL0264N Partitioning key cannot be added or dropped because table resides in a table space defined on the multi-node nodegroup "<name>".
Indexes and Partitioning Keys
The indexes defined on a table are partitioned based on the partitioning key of the underlying table. When an index is created, it will be created in all of the database partitions where the table was created. In each database partition, the entries in the index will have entries only for the rows of the table that are located in the same database partition.
Non-unique indexes can be created on any columns of a table, regardless of whether it is partitioned. However, any unique index or primary key created on a partitioned table must include the columns in the partitioning key.
Collocated Tables
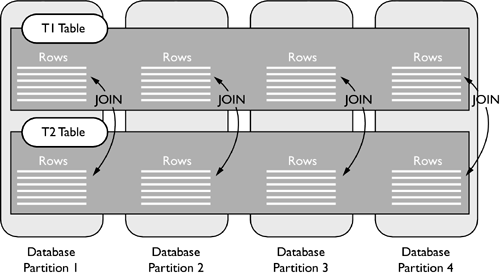
Often in a database, there will be tables that are frequently joined by applications. If the database is partitioned, it is good practice to try to avoid sending data between the partitions to satisfy these joins. This can be achieved in DB2 by exploiting table collocation. Collocation between two joined tables occurs when the matching rows of the two tables are stored in the same database partitions, so that no data needs to be sent between partitions. Figure 2.14 shows an example where tables T1 and T2 are collocated. A join made between these two tables is satisfied without the need for rows to be sent from one database partition to another.
Figure 2.14. Collocated tables.
Two tables are collocated when they satisfy all of the following conditions:
The partition groups of both tables must have the same partitioning map.
The partitioning key from both tables must have the same number of columns.
Corresponding partitioning key columns must be partition-compatible (the same or similar base data type).
For tables in multi-partition partition groups:
The two tables must be in the same partition group.
For tables in single-partition partition groups:
The tables can be in different partition groups, but these partition groups must include the same (single) database partition.
A collocated join will occur if two collocated tables are joined using all of the columns in the partitioning key.
If two tables can be joined using a collocated join, the query can be performed much more efficiently, compared with a join that sends data between database partitions.






