Configuration Parameter Tuning
Every database and every set of applications are unique in many aspects, and these differences have a profound impact on the performance of the database system. To get the most from the database and the server, it is important that the database manager and database be properly tuned for the specific environment.
The Performance Configuration wizard or the AUTOCONFIGURE command will provide a very good starter set for the configuration of the system. Although this configuration likely will not provide the absolute best performance, it is a much better starting point than the default configuration parameters.
Different types of applications and users have different response time requirements and expectations. Applications could range from simple data entry screens to strategic applications involving dozens of complex SQL statements accessing dozens of tables per unit of work. For example, response time requirements could vary considerably in a telephone customer service application versus a batch report generation application.
Some configuration parameters can also be set to automatic. If the parameter is set to automatic, DB2 will automatically adjust these parameters to reflect the current resources required by the applications and available on the server.
The changes to many configuration parameters can now take place immediately (i.e., online). This means that the instance need not be stopped and restarted or the database need not be reactivated for the parameter change to take effect. In order for these changes to take effect immediately, the IMMEDIATE option must be specified when the configuration parameter change is made. Otherwise, the change will be deferred until DB2 is stopped and restarted or the database is reactivated.
Database Manager Configuration Parameter Tuning and Monitoring
The database manager (or instance) configuration parameters have an effect on the overall system and all databases in the instance. The parameters listed in Table 8.1 have the most significant impact on overall system and database performance.
Application Support Layer Heap Size (ASLHEAPSZ)
Background
The application support layer heap is a communication buffer between an application and its associated DB2 agent. This buffer is allocated in shared memory by each agent process for a particular DB2 instance. If the application request or the output from DB2 cannot fit into this buffer, they will be split into multiple send-and-receive pairs.
The size of the application support layer heap should be set so that it can handle the majority of requests using a single send-and-receive pair. The size of the send-and-receive request is based on the storage required to hold:
The input SQLDA
All of the associated data in the SQLVARs
The output SQLDA
Other fields that do not generally exceed 250 bytes
Parameter | Description |
|---|---|
ASLHEAPSZ | Application support layer heap size |
RQRIOBLK | Maximum requester I/O block size |
SHEAPTHRES | Sort heap threshold |
INTRA_PARALLEL | Enable intra-partition parallelism |
MAX_QUERYDEGREE | Maximum query degree of parallelism |
MAXTOTFILOP | Maximum total of files open |
QUERY_HEAP_SZ | Query heap size |
FCM_NUM_BUFFERS | No. of inter-partition communication buffers |
NUM_POOLAGENTS | Agent pool size |
NUM_INITAGENTS | Initial number of agents in pool |
AGENTPRI | Priority of agents |
In addition to being the communication buffer between the application and its associated DB2 agent, this parameter is also used for two other purposes.
The application support layer heap determines the I/O block size when a cursor defined with blocking is opened. The memory required for blocked cursors is allocated out of the application's private address space, and if the database client cannot allocate the memory for a blocking cursor out of its private memory, a nonblocking cursor will be used.
The application support layer heap is also used to determine the communication size between the db2 agents and the processes used to support UDFs and fenced stored procedures. The size of the application support layer heap is allocated from shared memory for each UDF and stored procedure process or thread that is active on the system.
Configuring
The following formula should be used to calculate a minimum number of pages for the application support layer heap.
[View full width]aslheapsz >=(sizeof(input SQLDA) + sizeof(each input SQLVAR) + sizeof(output SQLDA) + 250)/ 4096
To set the application support layer heap size, use the following command:
update dbm cfg using aslheapsz 20
Once the database is operational, monitor the system to determine whether blocked cursor requests are being rejected and increase this parameter until this condition is eliminated.
Monitoring
DB2 does not monitor the usage of the application support layer heap; however, it does monitor the number of block cursor requests that are rejected. The number of rejected block cursor requests can be determined by using a database manager snapshot, as follows:
get snapshot for all on <database_name> | grep ?i "Rejected Block Remote Cursor requests"
This will capture a snapshot for the specified database and extract the monitor element concerned with the number of rejected block cursor requests. This will produce output like the following:
Rejected Block Remote Cursor requests = 2283
In this case, a number of requests for blocked cursors were unable to be handled, and a nonblocked cursor was used. A nonblocked cursor requires more network round trips and is much less efficient than a blocked cursor. It is good practice to eliminate the "Rejected Remote Block Cursor requests" completely by monitoring the database and increasing the ASLHEAPSZ parameter until the "Rejected Remote Block Cursor requests" element is zero.
Automatic
No
Online
No
Maximum Requester I/O Block Size (RQRIOBLK)
Background
The maximum requester I/O block size is the maximum amount of data that can be sent back and forth between a DB2 client and server. The communication block is allocated in agent private memory by each agent process for a DB2 instance; however, DB2 uses only what it needs up to this maximum size. If the application request or the output from DB2 is larger than the block size, the data will be split into multiple pieces and sent in multiple communication packets.
The default maximum requester I/O block size is 32 KB, and the maximum size is 64 KB. The default value is sufficient for most workloads; however, if the size of the application requests and/or result sets generated is greater than 32 KB, increasing the maximum requester I/O block size will result in fewer communication packets being sent back and forth across the network and can result in result sets being returned to the application quicker.
Configuring
Because DB2 allocates only as much memory as needed, setting the maximum requester I/O block size to 64 KB will not hurt performance but in many cases will help improve performance. To set this parameter to a value of 64 KB, use the command:
update dbm cfg using rqrioblk 64
Monitoring
The effectiveness of the setting for the maximum requester I/O block size cannot be monitored by DB2; it can be examined only by using network monitoring tools to count the number of communication packets sent between the DB2 client and server. Therefore, it is recommended that the maximum requester I/O block size be set to 64 KB to minimize network traffic.
Automatic
No
Online
No
Sort Heap Threshold (SHEAPTHRES)
Background
When an SQL query requires that the data be returned in specified order, the result set may or may not require sorting. DB2 will attempt to perform the ordering of the data using an index; however, if an index cannot be used, a sort will take place. For example, consider the following SQL statement:
select projno from project order by projno desc
With no indexes defined on the table, the access plan would need to sort the PROJNO column from the table to return the data in descending order. The access plan would look like the following:
Access Plan: ----------- Total Cost: 3589.463 Query Degree: 1 Rows RETURN ( 1) Cost I/O | 46 TBSCAN ( 2) 25.1692 1 | 46 SORT ( 3) 25.1678 1 | 46 TBSCAN ( 4) 25.1396 1 | 46 TABLE: DWAINE PROJECT
Notice that the access plan requires that the entire table be scanned and the data sorted in order to return the project number in descending order.
The following statement creates an index on the PROJNO column that is either in descending order or is defined to allow reverse scans:
create index projx on project (projno) allow reverse scans collect detailed statistics
As long as index statistics are gathered after the index is created or during the index creation, as specified above, the access plan would look like the following.
Access Plan: ----------- Total Cost: 341.134 Query Degree: 1 Rows RETURN ( 1) Cost I/O | 22680 IXSCAN ( 2) 341.134 37 | 22680 INDEX: DWAINE PROJX
In this case, the index can be used to retrieve the data and ensure the order of the project numbers without needing to sort the data. This resulted in significant cost savings for the query because the cost went from 3589.463 to 341.134 timerons.
If at all possible, sorts should be minimized, if not completely eliminated. However, if sorts cannot be eliminated, it is important to tune the sorts to work as efficiently as possible. To do this, it is important to understand how DB2 handles sort operations.
A sort operation typically occurs in two steps:
The sort phase
The return of the result of the sort phase
The manner in which DB2 performs these two steps results in different ways in which to describe the sort operation. When describing the sort phase, the sort is categorized as either overflowed or non-overflowed. When describing the return of the results from the sort phase, the sort is categorized as either piped or non-piped.
Overflowed vs. Non-Overflowed
If the table data that is being sorted cannot fit entirely within the configured sort heap, it will overflow into a temporary table in the system temporary table space. The sort heap is a piece of memory that is allocated when a sort is being performed. The size of the sort heap is limited by the database configuration parameter SORTHEAP, discussed later in this chapter. Non-overflowed sorts perform better than overflowed sorts because the entire operation happens in memory, and no disk I/O is required for a temporary table.
Piped vs. Non-Piped
If the information that has been sorted can be returned directly to the next operation in the access plan without requiring a temporary table to store a final, sorted list of data, it is referred to as a piped sort. If the information that has been sorted requires a temporary table to be returned to the next operation in the access plan, it is referred to as a non-piped sort.
A piped sort performs better than a non-piped sort because the entire operation happens in memory, and no disk I/O is required for a temporary table. The DB2 optimizer will determine whether a non-overflowed sort can be performed and whether a piped sort can be calculating the size of the expected result set with the value of the SORTHEAP database configuration parameter.
The sort heap threshold parameter (SHEAPTHRES) sets the maximum number of memory pages that can be used for private sorts. In DB2 UDB Version 8, a new database configuration parameter, SHEAPTHRES_SHR, is used to limit the maximum number of memory pages that can be used for shared sorts within the database.
If intra-partition parallelism is disabled, DB2 can use only private sorts. If intra-partition parallelism is enabled, DB2 can choose between private and shared sorts to determine which will be more efficient. Each individual sort will have a separate sort heap allocated where the data will be sorted. The optimizer will attempt to calculate the size of the sort heap that will be needed, based on the table statistics, to know whether it requires more space than the configured SORTHEAP to complete. If it requires more than SORTHEAP, the sort will be overflowed; otherwise, DB2 will attempt to allocate an entire SORTHEAP for the sort.
The sort heap threshold parameter controls the sum of all private and shared SORTHEAPs allocated by all applications for all databases in the DB2 instance. When the value set for SHEAPTHRES is reached for private sorts, DB2 will begin reducing the allocation of additional SORTHEAPs to the applications so that applications will still be given space for sorts. If this reduced amount of SORTHEAP is sufficient for the sort, it will not overflow; if it is insufficient, the sort will overflow.
When intra-partition parallelism is enabled, DB2 will allocate a piece of shared memory equal in size to the SHEAPTHRES_SHR, in case a shared sort is performed. This shared memory size is a hard limit and cannot be exceeded. Therefore, when the value set for SHEAPTHRES_SHR is reached for shared sorts, DB2 will stop allocating additional shared SORTHEAPs to the applications, and all shared sorts will be overflowed.
Configuring
The default value for SHEAPTHRES is quite low, especially for decision support databases. It is good practice to increase the value for SHEAPTHRES significantly because it can have a very dramatic effect on performance. However, increasing the SHEAPTHRES blindly can mask a real problem in the system or applications.
When determining an appropriate value for the SHEAPTHRES parameter, consider the following:
Hash joins and dynamic bitmaps used for index ANDing and star joins use sort heap memory. Increase the size of the SORTHEAP and SHEAPTHRES when these techniques are used.
Increase the SHEAPTHRES when large sorts are frequently required.
The value of SHEAPTHRES needs to be based on the value of the SORTHEAP, as well as on the average number of applications executing in the database.
For example, if database monitoring shows that, on average, there are 12 applications concurrently executing in DB2, setting the SHEAPTHRES to 12?15 times the SORTHEAP would be a good starting point.
Also important is the number of concurrent sorts per query.
To set the SHEAPTHRES configuration parameter, use the following command:
update dbm cfg using sheapthres 80000
Once the database is operational, monitor the system to determine whether the sort heap threshold is being reached.
Monitoring
Due to the impact of sorting on database performance, DB2 monitors a number of things in relation to sort activity. Sorts that are started after the sort heap threshold has been reached may not get an entire SORTHEAP allocated and, therefore, have a much higher chance of overflowing. The number of sorts stated after the SHEAPTHRES has been reached is reported in the post threshold sorts database monitor element.
In addition, the number of piped sorts requested and accepted and the number of overflowed sorts are also available in the snapshot information. These are related to the sort heap, as well as to the sort heap threshold and will be discussed in more detail when the sort heap is discussed later in this chapter.
To determine whether the sort heap threshold is being reached, take a database manager snapshot, using the following command:
get snapshot for database manager | grep ?i "Post threshold sorts"
This will capture a snapshot for the specified database and extract the monitor element concerned with the number of post threshold sorts. This would produce output like the following:
Post threshold sorts = 16
This information can also be captured using an SQL statement, as follows:
SELECT post_threshold_sorts FROM TABLE(SNAPSHOT_DBM(-1 )) as SNAPSHOT_DBM
This would produce output like the following:
POST_THRESHOLD_SORTS -------------------- 16
If this value is excessive, the size of the sort heap and/or sort heap thresholds should be examined to determine whether they are sufficient. In addition, the applications should be examined to ensure they are using appropriate indexes.
If the allocation of one more sort heaps equals or exceeds the sort heap threshold, a piped sort cannot be performed, and any request for a piped sort will get rejected. A sort heap will be allocated to handle the sorting of the data, but it will be a reduced size.
The percentage of piped sort requests that have been serviced by the database manager can be calculated using the formula:
Percent Piped Sorts = (piped_sorts_accepted / piped_sorts_requested) * 100%
If this percentage of piped sorts is low, the sort performance could be improved by increasing the sort heap threshold.
The number of piped sort requests that have been rejected by DB2 can be calculated using the following formula:
Piped Sorts Rejected = piped_sorts_requested - piped_sorts_accepted
A high number of rejected pipe sort requests may indicate that the value of either the sort heap or the sort heap threshold is too small to support the current workload.
Another indicator of sort performance is the percentage of post threshold sorts. DB2 allocates sort heaps at the beginning of sorts and at the beginning of any sort merge phase. If at any time during a sort a request to allocate a sort heap would exceed the SHEAPTHRES, the sort would be classified as a post threshold sort. The percentage of post threshold sorts is calculated using the following formula:
Percent Post Threshold Sorts = (post_threshold_sorts / sum of total_sorts) * 100%
The total amount of private sort heap that is currently allocated can be monitored using the following:
get snapshot for database manager | grep ?i "Private Sort heap allocated" or SELECT sort_heap_allocated FROM TABLE(SNAPSHOT_DBM(-1 )) as SNAPSHOT_DBM
Automatic
No
Online
No
Enable Intra-Partition Parallelism (INTRA_PARALLEL)
Background
Intra-partition parallelism refers to the ability to break up a query into multiple parts within a single database partition and to execute these parts at the same time. This type of parallelism subdivides what is usually considered a single database operation, such as index creation, database load, or SQL queries into multiple parts, many or all of which can be executed in parallel within a single database partition. Intra-partition parallelism can be used to take advantage of multiple processors of a symmetric multiprocessor (SMP) server.
Intra-partition parallelism can take advantage of either data parallelism or pipeline parallelism. Data parallelism is normally used when scanning large indexes or tables. When data parallelism is used as part of the access plan for an SQL statement, the index or data will be dynamically partitioned, and each of the executing parts of the query (known as package parts) is assigned a range of data to act on. For an index scan, the data will be partitioned based on the key values, whereas for a table scan, the data will be partitioned based on the actual data pages.
Configuring
Intra-partition parallelism in DB2 UDB is enabled or disabled using the database manager configuration parameter INTRA_PARALLEL. Intra-partition parallelism should be enabled only if the server has more than one processor (CPU). To enable intra-partition parallelism in DB2 UDB, the INTRA_PARALLEL configuration must be set to YES. This can be done using the following command:
update dbm cfg using intra_parallel yes
The degree of parallelism can then be controlled at the instance level, the database level, the application level, or the statement level.
Monitoring
If intra-partition parallelism is enabled, DB2 will invoke multiple db2 agents to process the request. The number of agents that are handling each request is returned by the command:
list applications show detail
If the number of agents is greater than one, intra-partition parallelism is being used, and the degree of parallelism is one less than the number of agents, because there is a coordinating agent associated with the operation.
Automatic
No
Online
No
Maximum Query Degree of Parallelism (MAX_QUERYDEGREE)
Background
The maximum degree of intra-partition parallelism specifies the maximum number of subagent processes that any SQL statement can use within the database instance (or database partition, if the database is partitioned). This parameter is effective only if intra-partition parallelism is enabled by setting the INTRA_PARALLEL configuration parameter to YES.
The default value for the maximum degree of intra-partition parallelism is -1, or ANY. This value allows the DB2 optimizer to set the degree of parallelism based on the number of CPUs in the server and the current workload on the server. If a value greater than one is specified, this value will limit the degree of parallelism for all SQL statements executed within the database instance or database partition.
Configuring
For a non-partitioned database running on a server with more than one CPU, the maximum degree of intra-partition parallelism should normally be set to ANY (-1) to allow DB2 to determine dynamically the degree of intra-partition parallelism for individual SQL queries. This can be done using the command:
UPDATE DBM CFG USING MAX_QUERYDEGREE ?1 IMMEDIATE
For a multi-partitioned database on a large SMP server, the maximum degree of parallelism for each partition should be limited so that no partition attempts to use all of the CPUs on the server. This can be done using the MAX_QUERYDEGREE instance configuration parameter. For a 32-way SMP server with eight database partitions, the maximum degree of parallelism for each partition could be limited to four, as follows:
UPDATE DBM CFG USING MAX_QUERYDEGREE 4 IMMEDIATE
For an SMP server with 16 CPUs, running two separate DB2 instances, the maximum degree of parallelism for each partition could be limited to eight, as follows:
UPDATE DBM CFG USING MAX_QUERYDEGREE 8 IMMEDIATE
Monitoring
If intra-partition parallelism is enabled, DB2 will invoke multiple db2 agents to process the request. The number of agents that are handling each request is returned by the command:
list applications show detail
If the number of agents is greater than one, intra-partition parallelism is being used, and the degree of parallelism is one less than the number of agents, because there is a coordinating agent associated with the operation.
Automatic
No
Online
Yes
Query Heap Size (QUERY_HEAP_SZ)
Background
A query heap is used to store each SQL statement in the private memory for the db2 agent executing the statement. The information that is stored in the query heap for an SQL statement includes the following:
the input SQLDA
the output SQLDA
the statement text
the SQLCA
the package name
the package creator
the section number
a consistency token
the cursor control block for any blocking cursors
The query heap size specifies the maximum amount of memory that can be allocated for the query heap and allows the DBA to ensure that an application does not consume an excessive amount of memory within a DB2 agent. When an application connects to DB2, the initial size of the query heap that is allocated will be the minimum of two pages, or the size of the application support layer heap (ASLHEAPSZ). If the currently allocated query heap is not large enough to handle the request, the query heap will be reallocated with a larger size that will handle the request, as long as it does not exceed the query heap size. If the amount of query heap required is more than 1.5 times larger than the application support layer heap, the query heap will be reallocated to the size of the application support layer heap when the query completes.
Configuring
The query heap size should be set to a minimum of five times the size of the application support layer heap to allow for queries that are larger than the application support layer heap and to allow for enough memory to support three to four concurrent blocking cursors, as well.
In most cases, the default value will be sufficient; however, if the applications are accessing large LOBs, the query heap size may need to be increased to be able to accommodate the LOBs. To increase the size of the query heap size, use the following command:
update dbm cfg using query_heap_sz 10000
Monitoring
The currently allocated size of the query heap cannot be monitored.
Automatic
No
Online
No
Number of FCM Buffers (FCM_NUM_BUFFERS)
Background
Fast communications manager (FCM) is used to communicate between database partitions in a multi-partitioned database or between subagents working on behalf of the same application if intra-partition parallelism is enabled. FCM is responsible for sending data back and forth between the database partitions or subagent processes.
The number of FCM buffers specifies the number of 4-KB buffers that are used for:
Communication between database partitions in a multi-partitioned database
Communication within a database partition or instance if intra-partition parallelism is enabled
The implementation of FCM is slightly different in AIX than on other platforms. For AIX, if there is enough room in the general database manager memory area, the FCM buffer heap will be allocated there. In this situation, each database partition server will have its own dedicated FCM buffers. In this case, each database partition will have FCM_NUM_BUFFERS buffers allocated.
If there is not enough room in the general database manager memory, the FCM buffer heap will be allocated from a separate memory area that is shared by all database partitions on the server. In this case, there will be a total of FCM_NUM_BUFFERS buffers allocated for the whole server.
For all platforms except AIX, if there are multiple database partitions created on a single server, one pool of FCM buffers will be shared by all database partitions on the same server. The number of buffers is specified by the FCM_NUM_BUFFERS database manager configuration parameter.
The DB2_FORCE_FCM_BP registry variable can be used to allow DB2 to communicate between database partitions on the same server entirely through shared memory, instead of using the high-speed interconnect. If the DB2_FORCE_FCM_BP registry variable is set to YES, the FCM buffers are always created in a separate memory segment so that communication between the FCM daemons for the different database partitions on the same server will occur through shared memory. Otherwise, FCM daemons on the same server must communicate through UNIX sockets using the high-speed interconnect, even if they are on the same server. Communicating through shared memory is faster, but if DB2 is installed in 32-bit mode, there will be less shared memory available for other uses, particularly for database buffer pools.
Configuring
Normally, the default value of the number of FCM buffers is sufficient. However, if there are multiple database partitions within the same server, it may be necessary to increase the value of this parameter. It may also be necessary to increase the value of this parameter if DB2 runs out of message buffers, due to:
The number of users on the server
The number of database partitions on the server
The complexity of the applications accessing the database
It is important to consider how many FCM buffers in total will be allocated on the servers where the database partitions reside. To increase the size of the query heap size, use the following command:
update dbm cfg using fcm_num_buffers 4096 immediate
Monitoring
DB2 UDB provides monitors solely for the purpose of monitoring the FCM and its efficiency. To gather the snapshot for all database partitions in the database, use the following command:
get snapshot for FCM for all dbpartitionnums
To gather the snapshot for a specific database partition, use the following command:
get snapshot for FCM for dbpartitionnum <x>
The output of the get snapshot command would look like the following for each database partition:
Node FCM information corresponds to = 0 Free FCM buffers = 2172 Free FCM buffers low water mark = 1682 Free FCM message anchors = 384 Free FCM message anchors low water mark = 156 Free FCM connection entries = 384 Free FCM connection entries low water mark = 308 Free FCM request blocks = 506 Free FCM request blocks low water mark = 218
The snapshot information above is for database partition zero (0). If the database has multiple partitions, there will be a snapshot report generated for each database partition. To analyze the number of FCM buffers, it is important to look at the current allocation of the FCM buffers, as well as the maximum number of FCM buffers that have been allocated, i.e., the low water mark for the free FCM buffers. These numbers can then be compared with the configured number of FCM buffers from the database manager configuration.
The above information can also be obtained using the following SQL statement:
SELECT * FROM TABLE(SNAPSHOT_FCM(-1 )) as SNAPSHOT_FCM
The output of this statement would look like the following:
[View full width]SNAPSHOT_TIMESTAMP BUFF_FREE BUFF_FREE_BOTTOM MA_FREE MA_FREE_BOTTOM CE_FREE
If the percentage of free FCM buffers (PFFCMBuf) drops below 10%, there is a potential that DB2 may run out of available buffers, and this would indicate that the number of FCM buffers should be increased. The PFFCMBuf is calculated from the snapshot and the database manager configuration, using the following formula:
PFFCMBuf = (Free_FCM_buffers_low_water_mark / FCM_NUM_BUFFERS) * 100%
If the number of FCM buffers were set to 4096 as above, based on the above snapshot, the PFFCMBuf would be:
PFFCMBuf = (1682 / 4096) * 100% PFFCMBuf = 41%
In this case, there seems to be plenty of FCM buffers available for future requests. However, this should be monitored over time, as well, because the low water mark would show the smallest number of available FCM buffers available for the entire time that DB2 UDB was running.
The low water mark for the free message anchors, free connection entries, and free request blocks should also be monitored. If the low water mark for any of these snapshot elements is less than 10% of the corresponding configured parameter value, increase the value of the corresponding parameter.
Automatic
No
Online
Yes
Agent Pool Size (NUM_POOLAGENTS)
Background
When an application connects to a DB2 database, it is assigned one or more DB2 agent processes to handle the connection and perform the work on behalf of the application. When an application disconnects from the database, the agent process could be terminated; however, this is not very efficient. The overhead of continually terminating the agent processes and starting new agent processes when needed can be quite high, and DB2 can avoid this by keeping the idle agent in a "pool" to be reused by other applications.
The agent pool is the place where idle agents are held by DB2 so that they can be reused. When the connection concentrator is not enabled (i.e., the setting of the maximum number of connections {MAX_CONNECTIONS} is equal to the maximum number of coordinating agents {MAX_COORDAGENTS}), this configuration parameter specifies the maximum size of the idle agent pool. All idle agents, regardless of whether they are coordinating agents or subagents, count toward this limit. If the workload causes more agents to be created than specified by the size of the agent pool, the agents will be terminated when they finish executing their current request.
When the connection concentrator is enabled (i.e., the setting of the maximum number of connections {MAX_CONNECTIONS} is greater than the number of coordinating agents {MAX_COORDAGENTS}), this configuration parameter will be used as a guideline for how large the agent pool will be when the system workload is low. A database agent will always be returned to the pool, no matter what the value of this parameter is.
The DB2 Connection Concentrator
The DB2 connection concentrator allows DB2 UDB servers to provide support for thousands of users simultaneously executing business transactions, while drastically reducing the resources required on the database server. It accomplishes this goal by concentrating the workload from all of the applications in a much smaller number of database server connections.
The DB2 connection concentrator uses logical agents (LAs) to handle the application context while database agents (DAs) handle the actual DB2 connections. When a new application connects to a database, it is assigned an LA. Because a DA is needed to pass the SQL to the DB2 server, one is assigned to perform the work for the LA as soon as a new transaction is initiated. The key to this architecture is the fact that the DA is disassociated from the LA and is returned to the agent pool when a transaction completes.
The connection concentrator is activated when the number of maximum logical agents is set higher than the number of database agents.
Although connection concentration is similar in concept to connection pooling, there are some main differences. Connection pooling saves the cost of establishing a new database connection when one is no longer needed by a terminating application. In other words, one application has to disconnect before another application can reuse a pooled connection. Connection concentration, on the other hand, allows DB2 to make a connection available to an application as soon as another application has finished a transaction and does not require that the other application disconnect from the database. With connection concentration, a database connection and its resources are used by an application only while it has an active transaction. As soon as the transaction completes, the connection and associated resources are available for use by any other application that is ready to have a transaction executed.
In previous versions of DB2, every application connected to a database had an agent process assigned to it to manage the database connection, as well as any application requests. In the above architecture, there is a one-to-one relationship between connections and db2 agents. The connection concentrator permits a many-to-one relationship between connections and agents.
The logical agents represent an application but without reference to a particular database agent. The logical agent contains all of the information and control blocks required by an application (i.e., the application's context). If there are N applications connected to the DB2 server, there will be N logical agents on the server. The database agents are the processes that execute the application's requests but which have no permanent attachment to any given application. The database agents are associated with logical agents to perform transactions, and at the end of the transaction, end the association and return to the available pool. An overview of connection concentration is shown in Figure 8.12.
Figure 8.12. Connection concentrator overview.
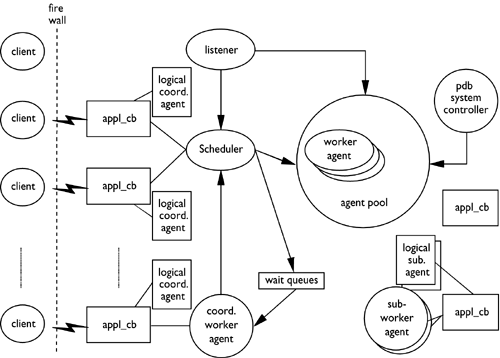
When a transaction request is initiated by an application, the scheduler will detect activity on the client connection and associate a database agent (worker agent in Figure 8.12) to service the logical agent. When a transaction completes, the database agent servicing it will be returned to the pool to service another logical agent. Only when additional work has been detected by the scheduler for this connection would a worker agent be again associated with its logical agent.
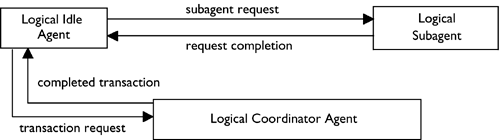
Figure 8.13 shows the various states and transitions that database agents can undergo while servicing applications. An idle agent is a physical agent that currently does not have a database connection or an application attachment. Any physical agent that has a database connection but no application attachment is considered a database agent. When a client transaction is started, a logical agent is associated with that transaction request (see Figure 8.14). DB2 will then attempt to find a database agent (or an idle agent, if no database agent is available) to service the logical agent request. Once identified, the agent will become a database coordinator agent.
Figure 8.13. Database agent transition diagram.
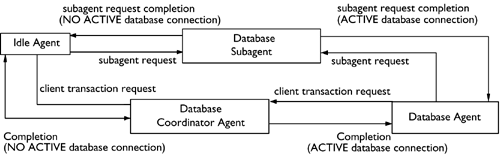
Figure 8.14. Logical agent transition diagram.
During the processing of the transaction a number of subagent requests, known as logical subagents, may be created in order to complete the transaction. The system will then try to find either a database agent or an idle agent to service these logical subagents. Once an agent is found, it becomes a database subagent. At the end of the transaction, the database coordinator agent could possibly disassociate from the logical coordinator agent and return to a database agent state. If the application terminates its database connection, the database agent will return to an idle state.
Any information in the database agent's private memory will be lost when a database agent (or an idle agent) is associated with a different logical agent. Database connection information is modified only when the database agent disconnects from one database and connects to another. Logical coordinator agents will return to their initial state (logical idle agent) at the end of the client connection.
The association of applications to logical agents is controlled by the logical agent scheduler. When activity on the client connection is detected, the logical agent scheduler attempts to find a database agent to service the logical agent. If there currently are no available database agents, the scheduler will place the logical agent into a queue of logical agents that are to be serviced when a database (or idle) agent becomes available.
During the course of processing a transaction and its many requests, certain information (both shared and private) is required by the DB2 components. Depending on whether this information is relevant across transaction or request boundaries determines whether the information will be stored at either the:
shared application level? application-level information, also sometimes called application-persistent data
shared database level? database-level information, or database-persistent data
private agent level? agent-level information
Any agent-level information is considered to be nonpersistent and relevant only to the current transaction. Transaction information that needs to be shared among database agents or needs to span transactional boundaries (i.e., cursors defined WITH HOLD) will be stored in the transaction information area. In systems where shared transaction information is required, this information will be allocated from shared memory; otherwise, it will be allocated from private memory. As a result, when a database agent is disassociated from either a logical coordinator agent or a logical subagent, this agent-level information is no longer associated to either a database or application, and it will be lost. When the database agent (or idle agent) is associated to another logical coordinator or logical subagent, the agent level information will be reinitialized based on information stored at the application level. Also contained in each component's information is a pointer to the shared database-level information (Figure 8.15).
Figure 8.15. The agent memory model.
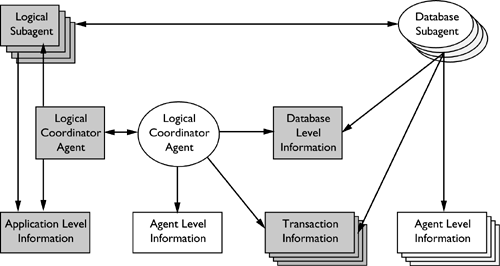
Information that normally resides in the agent's private memory that needs to be preserved beyond the end of a transaction will need to be moved into shared memory space. The amount of additional shared memory required is offset by the reduction in the amount of duplicate information that is being stored across components. The cost of associating and disassociating agents will be reduced because private memory areas will be refreshed, rather than de-allocating and allocating memory, as is done in DB2 Version 7.1.
Activating the connection concentrator
The connection concentrator will be activated when the value of MAX_CONNECTIONS is greater than the value of MAX_COORDAGENTS, as follows:
update dbm cfg using max_coordagents 80 update dbm cfg using max_connections 1200
Table 8.2 defines the key parameters related to connection concentration.
Meaning When Concentrator Is | |||
|---|---|---|---|
Configuration Parameter | Not Enabled | Enabled | Range of Values |
max_connections (This parameter was referred to as maxagents in Version 7) |
This is the maximum number of client connections allowed per partition. Concentrator is not enabled when MAX_CONNECTIONS equals MAX_COORDAGENTS. |
Concentrator is enabled when MAX_CONNECTIONS is greater than MAX_COORDAGENTS. |
1 to 64,000 |
maxagents | This is the maximum number of database agents, whether coordinator agents or subagents, available at any given time. This parameter can be used in a memory-constrained server to limit the total number of agents on the server. | 1 to 64,000 | |
max_coordagents | This parameter determines the maximum number of coordinator agents that can exist at one time on a server in a partitioned or nonpartitioned database environment. One coordinator agent is acquired for each local or remote application that connects to a database or attaches to an instance. Therefore, when the concentrator is not enabled, the total number of coordinator agents will always be greater than or equal to the number of connections. | When the concentrator is enabled, there may be more connections than coordinator agents to service them. An application is in an active state only if there is a coordinator agent servicing it. Otherwise, the application is in an inactive state. Requests from an active application will be served by the database coordinator agent and the subagents. Requests from an inactive application will be queued until a database coordinator agent is assigned to service the application, when the application becomes active. This parameter can also be used to control the load on the system. | 0 to MAXAGENTS |
num_initagents | This parameter determines the initial number of idle agents that are created in the agent pool when the instance is started. | 0 to NUM_POOLAGENTS | |
num_poolagents | This parameter determines the maximum size of the idle agent pool. If more agents are created than indicated by this parameter, agents will be terminated when they finish executing their current request, rather than be returned to the pool. | When the concentrator is enabled, this parameter will be used as a guideline for how large the agent pool will be when the system workload is low. A database agent will always be returned to pool, no matter what the value of this parameter is. Based on the system load and the time agents remain idle in the pool, the logical agent scheduler may terminate as many of them as to bring down the size of the idle pool back to this parameter (see note below). | 0 to MAXAGENTS |
appl_group_mem_sz | This parameter determines the maximum size for the application group shared memory segment. Application control group heap is allocated from shared memory. All applications attached to the same segment share one application shared workspace. | 1 to 64,000 | |
appl_ctl_heap_sz | This parameter determines the maximum size for the application control shared memory set. Application control heaps are allocated from this shared memory. For parallel systems, space is also required for the application control heap, which is shared between the agents that are working on behalf of the same application on one database partition. | 1 to 64,000 | |
appl_group_share_heap_ratio | Specifies the percentage of memory devoted to the shared heap. | 1 to 99 | |
appl_trans_heap_sz | NOT USED | This parameter determines the maximum size of the application transaction heap for each application. This heap is used by DB2 to work on the active transaction. In a parallel configuration, space is required to hold information shared between the agents that are working on behalf of the same transaction. | 1 to 64,000 |
applheapsz | This parameter defines the number of private memory pages available to be used by the database manager on behalf of a specific agent or subagent. The heap is allocated when an agent or subagent is initialized for an application. The amount allocated will be the minimum amount needed to process the request given to the agent or subagent. As the agent or subagent requires more heap space to process larger SQL statements, the database manager will allocate memory as needed, up to the maximum specified by this parameter. The application heap (applheapsz) is allocated out of agent private memory. | 1 to 64,000 | |
NOTE
When the workload is high and the connection concentrator is enabled, there are likely far more connections to be serviced than available database agents to service them. A subagent will return to the agent pool after servicing a request, so that it can be used for other requests. A coordinator agent will return to pool if there is no application waiting to be served at the time the agent finishes the transaction and checks for waiting applications, but there could be clients available immediately. An agent will terminate only after it has been idle and waiting in the pool for an amount of time determined by the logical agents scheduler, which indicates that the workload on the system has gone down.
Based on the system load and the length of time that agents remain idle in the pool, the logical agent scheduler may terminate as many agents as necessary to reduce the size of the idle agent pool to the specified value. If the value for this configuration parameter is zero (0), agents will be created as needed, and may be terminated when they finish executing their current request. If the value of this configuration parameter is equal to MAXAGENTS and the agent pool is full of associated subagents, the server cannot be used as a coordinator node, because no new coordinator agents can be created.
Setting the appropriate value for this parameter can reduce the cost of continually creating and terminating DB2 agent processes. However, setting this value too high will leave idle DB2 agent processes on the system and will, therefore, not release the memory allocated by the agent processes.
Configuring
For a decision support workload characterized by relatively few concurrent applications, the size of the agent pool should be relatively small to avoid having an agent pool that is full of idle DB2 agents. For a transaction-processing workload characterized by many concurrent applications, the size of the agent pool should be increased to avoid the cost of constant creation and termination of the DB2 agents.
To specify the size of the agent pool, use the following command:
update dbm cfg using nu





