High Availability Clustering
High availability (HA) is the term that is used to describe systems that run and are available to customers more or less all the time.
Failover protection can be achieved by keeping a copy of your database on another machine that is perpetually rolling the log files forward. Log shipping is the process of copying whole log files to a standby machine, either from an archive device or through a user exit program running against the primary database. With this approach, the primary database is restored to the standby machine, using either the DB2 restore utility or the split mirror function. You can use the new suspended I/O support to initialize the new database quickly. The secondary database on the standby machine continuously rolls the log files forward.
If the primary database fails, any remaining log files are copied over to the standby machine. After a rollforward to the end of the logs and stop operation, all clients are reconnected to the secondary database on the standby machine.
Failover strategies are usually based on clusters of systems. A cluster is a group of connected systems that work together as a single system. Clustering allows servers to back each other up when failures occur by picking up the workload of the failed server.
IP address takeover (or IP takeover) is the ability to transfer a server IP address from one machine to another when a server goes down; to a client application, the two machines appear at different times to be the same server.
Failover software may use heartbeat monitoring or keepalive packets between systems to confirm availability. Heartbeat monitoring involves system services that maintain constant communication between all the servers in a cluster. If a heartbeat is not detected, failover to a backup system starts. End users are usually not aware that a system has failed.
NOTE
For clarification and consistency with the naming convention throughout the book, a database node is now called a database partition, and when referencing a node name in the cluster, we refer to it as a server.
The two most common failover strategies on the market are known as idle standby and mutual takeover, although the configurations associated with these terms may also be associated with different terms that depend on the vendor.
Idle Standby
In this configuration, one system is used to run a DB2 instance, and the second system is idle, or in standby mode, ready to take over the instance if there is an operating system or hardware failure involving the first system. Overall system performance is not impacted, because the standby system is idle until needed.
Mutual Takeover
In this configuration, each system is the designated backup for another system. Overall system performance may be impacted, because the backup system must do extra work following a failover: It must do its own work plus the work that was being done by the failed system.
Failover strategies can be used to failover an instance, a partition, or multiple database partitions.
When designing and testing a cluster:
Ensure that the administrator of the cluster is familiar with the system and what should happen when a failover occurs.
Ensure that each part of the cluster is truly redundant and can be replaced quickly if it fails.
Force a test system to fail in a controlled environment, and make sure that it fails over correctly each time.
Keep track of the reasons for each failover. Although this should not happen often, it is important to address any issues that make the cluster unstable. For example, if one piece of the cluster caused a failover five times in one month, find out why and fix it.
Ensure that the support staff for the cluster is notified when a failover occurs.
Do not overload the cluster. Ensure that the remaining systems can still handle the workload at an acceptable level after a failover.
Check failure-prone components (such as disks) often, so that they can be replaced before problems occur.
In order to implement a split mirror scenario with DB2 Universal Database (UDB) Enterprise Server Edition, it is very important to understand the following three concepts.
Split Mirror
Split mirror is an identical and independent copy of disk volumes that can be attached to a different system and can be used in various ways, e.g., to populate a test system, as a warm standby copy of the database, and to offload backups from the primary machine.
A split mirror of a database includes the entire contents of the database directory, all the table space containers, the local database directory, and the active log directory, if it does not reside on the database directory. The active log directory needs to be split only for creating a clone database using the "snapshot" option of the "db2inidb" tool.
Suspend I/O Feature
When splitting the mirror, it is important to ensure that there is no page write occurring on the source database. One way to ensure this is to bring the database offline. But, due to the required downtime, this method is not a feasible solution in a true 24x7 production environment.
In an effort to provide continuous system availability during the split mirror process, DB2 UDB Enterprise Server Edition (ESE) provides a feature known as suspend I/O, which allows online split mirroring without shutting down the database. The suspend I/O feature ensures the prevention of any partial page write by suspending all write operations on the source database. While the database is in write suspend mode, all of the table space states change to a new state SUSPEND_WRITE, and all operations function normally.
However, some transactions may wait if they require disk I/O, such as flushing dirty pages from the buffer pool or flushing logs from the log buffer. These transactions will proceed normally, once the write operations on the database are resumed. The following command is used to suspend or resume write operations on the source database:
db2 set write <suspend | resume> for database
The db2inidb Tool
The split mirror created using the suspend I/O feature continues to stay in a write-suspend mode until it is initialized to a useable state. To initialize the split mirror, you can invoke the db2inidb tool.
This tool can either perform a crash recovery on a split mirror image or can put it in a rollforward pending state, depending on the options provided in the db2inidb command, the syntax of which is as follows:
db2inidb <database_alias> as < snapshot | standby |mirror >[ relocate using <config_file> ]
The snapshot option clones the primary database to offload work from the source database, such as running reports, analysis, or populating a target system.
The standby option continues rolling forward through the log, and even new logs that are created by the source database are constantly fetched from the source system.
The mirror uses the mirrored system as a backup image to restore over the source system.
The relocate option allows the split mirror to be relocated in terms of the database name, database directory path, container path, log path, and the instance name associated with the database.
Common Usage of Suspend I/O and db2inidb
The combination of the suspend I/O feature and the db2inidb tool is necessary to bring the split mirror database into a functional state. With the functionalities of the three options (snapshot, standby, mirror) provided in the db2inidb tool, in conjunction with the suspend I/O feature, it is possible to create a fast snapshot of a database, which can be used to:
Populate a test system by making a copy of the current data.
Create a standby database that can be used as a warm standby (DB2 backup can be taken if the database contains DMS only table spaces).
Provide a quick file system level recovery option.
Take database backups that can be restored on the database server.
The suspend I/O feature is necessary to ensure that all DB2 data gets written out to the disk consistently (no partial page write) before splitting the mirror. This assures a well-defined state where the database can be recovered to later, using the db2inidb tool.
The db2inidb tool can either force the database to perform a crash recovery (when the snapshot option is specified) or put the database into a rollforward pending state (when the standby or mirror option is specified) to allow processing of additional log files.
High Availability through Log Shipping
Log shipping is the process of copying whole log files to a standby machine, either from an archive device or through a user exit program running against the primary database. The standby database is continuously rolling forward through the log files produced by the production machine. When the production machine fails, a switch over occurs, and the following takes place:
The remaining logs are transferred over to the standby machine, if possible.
The standby database rolls forward to the end of the logs and stops.
The clients reconnect to the standby database and resume operations.
The standby machine has its own resources (i.e., disks) but must have the same physical and logical definitions as the production database. When using this approach, the primary database is restored to the standby machine by using the restore utility or the split mirror function.
To ensure that you are able to recover your database in a disaster recovery situation, consider the following:
The archive location should be geographically separate from the primary site.
Remotely mirror the log at the standby database site.
Use a synchronous mirror for no loss support. You can do this through:
DB2 log mirroring or modern disk subsystems, such as ESS and EMC.
NVRAM cache (both local and remote) is also recommended to minimize the performance impact of a disaster recovery situation.
NOTE
When the standby database processes a log record indicating that an index rebuild took place on the primary database, the indexes on the standby server are not automatically rebuilt. The index will be rebuilt on the standby server, either at the first connection to the database or at the first attempt to access the index after the standby server is taken out of rollforward pending state. It is recommended that the standby server be resynchronized with the primary server if any indexes on the primary server are rebuilt.
If the load utility is run on the primary database with the COPY YES option specified, the standby database must have access to the copy image.
If the load utility is run on the primary database with the COPY NO option specified, the standby database should be resynchronized; otherwise the table space will be placed in restore pending state.
There are two ways to initialize a standby machine:
Restoring it from a backup image
Creating a split mirror of the production system and issuing the db2inidb command with the STANDBY option (only after the standby machine has been initialized and you issue the ROLLFORWARD command on the standby system)
Operations that are not logged (i.e., activities performed on a table created with NOT LOGGED INITIALLY) will not be replayed on the standby database. As a result, it is recommended that you resync the standby database after such operations. You can do this through online split mirror and suspended I/O support.
High Availability through Online Split Mirror and Suspended I/O Support
Suspended I/O supports continuous system availability by providing a full implementation for online split mirror handling; that is, splitting a mirror without shutting down the database. A split mirror is an "instantaneous" copy of the database that can be made by mirroring the disks containing the data and splitting the mirror when a copy is required. Disk mirroring is the process of writing all of your data to two separate hard disks; one is the mirror of the other. Splitting a mirror is the process of separating the primary and secondary copies of the database.
If you would rather not back up a large database using the DB2 backup utility, you can make copies from a mirrored image by using suspended I/O and the split mirror function. This approach also:
Eliminates backup operation overhead from the production machine.
Represents a fast way to clone systems.
Represents a fast implementation of idle standby failover. There is no initial restore operation, and if a rollforward operation proves to be too slow or encounters errors, reinitialization is very quick.
The db2inidb command initializes the split mirror so that it can be used:
As a clone database
As a standby database
As a backup image
In a partitioned database environment, you do not have to suspend I/O writes on all partitions simultaneously. You can suspend a subset of one or more partitions to create split mirrors for performing offline backups. If the catalog partition is included in the subset, it must be the last partition to be suspended.
In a partitioned database environment, the db2inidb command must be run on every partition before the split image from any of the partitions can be used. The tool can be run on all partitions simultaneously, using the db2_all command.
NOTE
Ensure that the split mirror contains all containers and directories that comprise the database, including the volume directory (each autonumbered directory within a volume).
Split Mirror to Clone a Database
Clone the primary database to offload work from source database, such as running reports, analysis, or populating a target system.
The following scenario shows how to create a clone database on the target system, using the suspend I/O feature. In this scenario, the split mirror database goes through a crash recovery initiated by the db2inidb tool with the snapshot parameter. A clone database generated in this manner can be used to populate a test database or to generate reports. Due to crash recovery, the clone database will start a new log chain; therefore, it will not be able to replay any future log files from the source database. A database backup taken from this clone database can be restored to the source database. However, it will not be able to roll forward through any log records generated after the database was split. Thus, it will be a version-level copy only.
Suspend I/O on the source system.
The following commands will suspend I/O (all write activities from DB2 clients) on the source database so that the mirrors of the database containers can be split without the possibility of a partial page write occurring. Please note that suspending I/O on a database will not disconnect the existing connections to the database, and all operations would function normally. However, some transactions may wait if they require disk I/O. But as soon as the I/O has been resumed on the database, the transactions will proceed normally.
db2 connect to <source-database> db2 set write suspend for database
Use appropriate operating system-level commands to split the mirror or mirrors from the source database.
The process to split a mirror differs from vendor to vendor. Please consult the storage vendor documentation applicable to your device on how to create a split mirror. Regardless of the variations on the split mirror process, the entire contents of the database directory, all the table space containers, the local database directory, and the active log directory (if it does not reside on the database directory) must be split at the same time.
Resume I/O on the source system.
The following command will resume I/O (all write activities from DB2 clients) on the source database, and the currently running transactions will proceed as normal. It is essential that the same database connection that was used to issue the db2 set write suspend command be used to issue the write resume command.
db2 set write resume for databaseAttach to the mirrored database from the target machine.
After the split of the mirror, the administrator for the target machine must use the facilities of the storage vendor to provide access to the split mirror copy, to be referred to as mount. For initial setup, the following steps need to be taken on the target system:
Create the same database instance as it is on the source machine.
Catalog the database (system database directory).
Mount the database directory into the same directory as it is on the source machine.
Mount all of the containers to the same paths as they are on the source machine. If the containers are located in several directories, all container directories must be mounted.
If the log files are located in a directory other than the database directory, the log directory should also be mounted into the same directory as it is on the source machine.
Start the database instance on the target system.
Start the database manager on the target machine, assuming that the DB2 registry variable DB2INSTANCE is set to the instance name the same as the source machine.
db2startBring the clone database into a consistent state.
The following command will initiate a crash recovery and will roll back all uncommitted transactions, making the database consistent. It is essential to have all the log files that were active at the time of the split. The active log directory should not contain any log file that is not a part of the split mirror. After the crash recovery a new log chain will be started; therefore, the database will not be able to roll forward through any of the logs from the source database. The database will now be available for any operation.
db2inidb <dbname> as snapshotNOTE
This command will roll back transactions that were in flight when the split occured and start a new log chain sequence so that any logs from the primary database cannot be replayed on the cloned database.
Split Mirror as a Standby Database
Continue to roll forward through the logs and even new logs that are created by the source database are constantly fetched from the source system.
The following scenario shows how to create a standby database on the target system, using the suspend I/O feature. In a warm standby database scenario, the log files of the source database will be applied on the target (standby) database. The standby database will be kept in a rollforward pending state until the rollforward has been stopped. A DB2 backup image taken on the clone database (DMS only) can be used for restoring on the source database for the purpose of performing a rollforward recovery by using the log files produced on the source database after the mirror was split. Please see the following steps:
Suspend I/O on the source system.
The following commands will suspend the I/O (all write activities from DB2 clients) on the database so that the mirrors of the database containers can be split without the possibility of a partial page write occurring. Please note that suspending I/O on a database will not disconnect the existing connections to the database, and all operations would function normally. However, some transactions may wait if they require disk I/O. But as soon as the I/O has been resumed on the database, the transactions will proceed normally.
db2 connect to <source-database> db2 set write suspend for database
Use appropriate operating system-level commands to split the mirror or mirrors from the source database.
The process to split a mirror differs from vendor to vendor. Please consult the storage vendor documentation applicable to your device on how to create a split mirror. Regardless of the variations on the split mirroring process, the entire contents of the database directory, all the table space containers, and the local database directory must be split at the same time. It is NOT necessary to split the active log directory in this case.
Resume I/O on the source system.
The following command will resume I/O (all write activities from DB2 clients) on the source database, and the currently running transactions will proceed as normal. It is essential that the same database connection that was used to issue the db2 set write suspend command be used to issue the write resume command.
db2 set write resume for databaseAttach to the mirrored database from the target machine.
After the split of the mirror, the administrator for the target machine must use the facilities of the storage vendor to provide access to the split mirror copy, to be referred to as mount. For initial setup, the following steps need to be taken on the target system:
Create the same database instance as it is on the source machine.
Catalog the database (system database directory).
Mount the database directory into the same directory as it is on the source machine.
Mount all of the containers to the same paths as they are on the source machine. If the containers are located in several directories, all container directories must be mounted.
If the log files are located in a directory other than the database directory, the log directory should also be mounted into the same directory as it is on the source machine.
Start the database instance on the target system.
Start the database manager on the target machine, assuming that the DB2 registry variable DB2INSTANCE is set to the instance name the same as the source machine.
db2startPut the mirrored database in rollforward mode.
This places the split mirror database into a rollforward pending state. Crash recovery is not performed, and the database remains inconsistent.
db2inidb <dbname> as standbyContinually copy over the log files and roll forward.
Once the database is placed into a rollforward pending state, the log files from the source database can be used to roll forward the target database. A user exit program can be used in this case to automate the continuous archival of the inactive log files. If user exit is used, both source and target databases must be configured with the same user exit program.
db2 rollforward db <dbname> to end of logsActivate the standby database.
If the source database crashes, the standby database on the target machine can be activated for user access. The user applications will have to make new connections to this standby database. In order to activate, the standby database needs to be taken out of the rollforward pending state. The users should issue the rollforward command with the "stop" or "complete" option to bring the database into a consistent state. Once the database is in consistent state, the users can switch over to the standby database to continue their work. The log files generated on the standby database cannot be applied on the source database.
While the target database is in rollforward pending state, it is possible to perform an offline backup if the database has DMS only table spaces.
db2 rollforward db <dbname> stopNOTE
If you have only DMS table spaces, you can take a full database backup to offload the overhead of taking a backup on the production database.
Split Mirror as a Backup Image
Use the mirrored system as a backup image to restore over the source system.
The following scenario shows how to create a mirror database on the target system, using the suspend I/O feature. The purpose of this option is to provide the possibility of using a split mirror database for restoring on top of the source database, then to roll forward the log files of the source database. It is important to note that the split mirror must remain in the SUSPEND_WRITE state until it has been copied over on top of the source database.
Split Mirror
Suspend I/O on the source database.
The following commands will suspend I/O (all write activities from DB2 clients) on the database so that the mirrors of the database containers can be split without the possibility of a partial page write occurring. Please note that suspending I/O on a database will not disconnect the existing connections to the database, and all operations would function normally. However, some transactions may wait if they require disk I/O. But as soon as the I/O has been resumed on the database, the transactions will proceed normally.
db2 connect to <source-database> db2 set write suspend for database
Split the mirror.
The process to split the mirror differs from vendor to vendor. Please consult the storage vendor documentation applicable to your device on how to create a split mirror. Regardless of the variations on the split mirroring process, the entire contents of the database directory, all the table space containers, and the local database directory must be split at the same time. It is not necessary to split the active log directory in this case.
Resume I/O on the source database.
The following command will resume I/O (all write activities from DB2 clients) on the source database, and the currently running transactions will proceed as normal. It is essential that the same database connection that was used to issue the db2 set write suspend command be used to issue the write resume command.
db2 set write resume for database
Restore the Split Mirror Image
There is no "target" database in this scenario. The intent of this scenario is to use the mirror copy to restore on top of the "source" database to recover from a disk failure. The split mirror cannot be backed up using the DB2 backup utility, but it can be backed up using operating system tools. If the source database happens to crash, it can be restored with the split mirror image by copying it on top of the source database. Please see the following steps:
Stop the source database instance.
The database instance needs to be shut down using the following DB2 command before restoring the split mirror image into it.
db2stopRestore the split mirror image.
Using the storage vendor utilities, copy the data files of the split mirror database over the original database. Please do not use the operating system utilities in this case because the operating system does not have any knowledge of this split image.
Start the source database instance after restoring the split mirror image.
db2startInitialize the mirror copy on the source database.
This step will replace the source database with the mirror copy of the database and will place it into a rollforward pending state. No crash recovery is initiated, and the database will remain inconsistent until it has been rolled forward to the end of logs.
db2inidb <database> as mirrorRollforward to end of logs.
The log files from the source database must be used to roll forward the database.
db2 rollforward database <database> to end of logs and completeIn a multi-partitioned database environment, every database partition is treated as a separate database. Therefore, the I/O on each partition needs to be suspended during the split mirror process and should be resumed afterward. The same applies to the db2inidb tool and needs to be run on each mirrored partition before using the database.
Following are some examples of how to issue the commands simultaneously on all partitions.
db2_all "db2 connect to <source-database>; db2 set write resume for database" db2_all "db2inidb <target-database> as <options>"
High Availability on AIX
Enhanced scalability (ES) is a feature of High Availability Cluster Multi-Processing (HACMP) for AIX. This feature provides the same failover recovery and has the same event structure as HACMP. Enhanced scalability also has other provisions:
Larger clusters.
Additional error coverage through user-defined events.
Monitored areas can trigger user-defined events, which can be as diverse as the death of a process or the fact that paging space is nearing capacity. Such events include pre- and post-events that can be added to the failover recovery process, if needed. Extra functions that are specific to the different implementations can be placed within the HACMP pre-event and post-event streams.
A rules file (/usr/sbin/cluster/events/rules.hacmprd) contains the HACMP events. User-defined events are added to this file. The script files that are to be run when events occur are part of this definition.
HACMP client utilities for monitoring and detecting status changes (in one or more clusters) from AIX physical server outside of the HACMP cluster.
The servers in HACMP ES clusters exchange messages called heartbeats or keepalive packets, by which each server informs the other server about its availability. A server that has stopped responding causes the remaining servers in the cluster to invoke recovery. The recovery process is called a server-down-event and may also be referred to as failover. The completion of the recovery process is followed by the reintegration of the server into the cluster. This is called a server-up-event.
There are two types of events: standard events that are anticipated within the operations of HACMP ES and user-defined events that are associated with the monitoring of parameters in hardware and software components. One of the standard events is the server-down-event. When planning what should be done as part of the recovery process, HACMP allows two failover options: hot (or idle) standby and mutual takeover.
NOTE
When using HACMP, ensure that DB2 instances are not started at boot time by using the db2iauto utility, as follows:
db2iauto ?off InstName
where InstName is the login name of the instance.
Cluster Configuration
In a hot-standby configuration, the AIX server that is the takeover server is not running any other workload. In a mutual takeover configuration, the AIX server that is the takeover server is running other workloads.
Generally, in a partitioned database environment, DB2 UDB runs in mutual takeover mode with multiple database partitions on each server. One exception is a scenario in which the catalog partition is part of a hot-standby configuration.
When planning a large DB2 installation on an RS/6000 SP using HACMP ES, you need to consider how to divide the servers of the cluster within or between the RS/6000 SP frames. Having a server and its backup in different SP frames allows takeover in the event that one frame goes down (that is, the frame power/switch board fails). However, such failures are expected to be exceedingly rare because there are N+1 power supplies in each SP frame, and each SP switch has redundant paths, along with N+1 fans and power. In the case of a frame failure, manual intervention may be required to recover the remaining frames. This recovery procedure is documented in the SP Administration Guide. HACMP ES provides for recovery of SP server failures; recovery of frame failures is dependent on the proper layout of clusters within one or more SP frames.
Another planning consideration is how to manage big clusters. It is easier to manage a small cluster than a big one; however, it is also easier to manage one big cluster than many smaller ones. When planning, consider how your applications will be used in your cluster environment. If there is a single, large, homogeneous application running, for example, on 16 servers, it is probably easier to manage the configuration as a single cluster, rather than as eight two-server clusters. If the same 16 servers contain many different applications with different networks, disks, and server relationships, it is probably better to group the servers into smaller clusters. Keep in mind that servers integrate into an HACMP cluster one at a time; it will be faster to start a configuration of multiple clusters, rather than one large cluster. HACMP ES supports both single and multiple clusters, as long as a server and its backup are in the same cluster.
HACMP ES failover recovery allows predefined (also known as cascading) assignment of a resource group to a physical server. The failover recovery procedure also allows floating (or rotating) assignment of a resource group to a physical server. IP addresses and external disk volume groups, file systems, or NFS file systems, as well as application servers within each resource group specify either an application or an application component, which can be manipulated by HACMP ES between physical servers by failover and reintegration. Failover and reintegration behavior is specified by the type of resource group created and by the number of servers placed in the resource group.
For example, consider a partitioned database environment, if its log and table space containers were placed on external disks and other servers were linked to those disks, it would be possible for those other servers to access these disks and to restart the database partition (on a takeover server). It is this type of operation that is automated by HACMP. HACMP ES can also be used to recover NFS file systems used by DB2 instance main user directories.
Read the HACMP ES documentation thoroughly as part of your planning for recovery with DB2 UDB in a partitioned database environment. You should read the Concepts, Planning, Installation, and Administration guides, then build the recovery architecture for your environment. For each subsystem that you have identified for recovery, based on known points of failure, identify the HACMP clusters that you need, as well as the recovery servers (either hot standby or mutual takeover).
It is strongly recommended that both disks and adapters be mirrored in your external disk configuration. For DB2 servers that are configured for HACMP, care is required to ensure that servers on the volume group can vary from the shared external disks. In a mutual takeover configuration, this arrangement requires some additional planning, so that the paired servers can access each other's volume groups without conflicts. In a partitioned database environment, this means that all container names must be unique across all databases.
One way to achieve uniqueness is to include the partition number as part of the name. You can specify a database partition expression for container string syntax when creating either SMS or DMS containers. When you specify the expression, the database partition number can be part of the container name or, if you specify additional arguments, the results of those arguments can be part of the container name. Use the argument $N ([blank]$N) to indicate the database partition expression. The argument must occur at the end of the container string.
Following are some examples of how to create containers using this special argument:
Creating containers for use on a two-database partition system
The following containers would be used:
CREATE TABLESPACE TS1 MANAGED BY DATABASE USING (device '/dev/rcont $N' 20000) /dev/rcont0?on DATABASE PARTITION 0 /dev/rcont1?on DATABASE PARTITION 1
Creating containers for use on a four-database partition system
The following containers would be used:
[View full width]CREATE TABLESPACE TS2 MANAGED BY DATABASE USING (file '/DB2/containers/TS2/container$N+100' 10000) /DB2/containers/TS2/container100?on DATABASE PARTITION 0 /DB2/containers/TS2/container101?on DATABASE PARTITION 1 /DB2/containers/TS2/container102?on DATABASE PARTITION 2 /DB2/containers/TS2/container103?on DATABASE PARTITION 3
Creating containers for use on a two-database partition system
The following containers would be used:
CREATE TABLESPACE TS3 MANAGED BY SYSTEM USING ('/TS3/cont $N%2, '/TS3/cont $N%2+2') /TS3/cont0?on DATABASE PARTITION 0 /TS3/cont2?on DATABASE PARTITION 0 /TS3/cont1?on DATABASE PARTITION 1 /TS3/cont3?on DATABASE PARTITION 1
A script file, rc.db2pe, is packaged with DB2 UDB Enterprise Server Edition (and installed on each server in /usr/bin) to assist in configuring for HACMP ES failover or recovery in either hot standby or mutual takeover servers. In addition, DB2 buffer pool sizes can be customized during failover in mutual takeover configurations from within rc.db2pe. Buffer pool sizes can be configured to ensure proper resource allocation when two database partitions run on one physical server.
HACMP ES Event Monitoring and User-Defined Events
Initiating a failover operation if a process dies on a given server is an example of a user-defined event. Examples that illustrate user-defined events, such as shutting down a database partition and forcing a transaction abort to free paging space, can be found in the sqllib/samples/hacmp/es subdirectory.
A rules file, /usr/sbin/cluster/events/rules.hacmprd, contains HACMP events. Each event description in this file has the following nine components:
Event name, which must be unique.
State, or qualifier for the event. The event name and state are the rule triggers. HACMP ES Cluster Manager initiates recovery only if it finds a rule with a trigger corresponding to the event name and state.
Resource program path, a full path specification of the xxx.rp file containing the recovery program.
Recovery type. This is reserved for future use.
Recovery level. This is reserved for future use.
Resource variable name, which is used for Event Manager events.
Instance vector, which is used for Event Manager events. This is a set of elements of the form name=value. The values uniquely identify the copy of the resource in the system and, by extension, the copy of the resource variable.
Predicate, which is used for Event Manager events. This is a relational expression between a resource variable and other elements. When this expression is true, the Event Management subsystem generates an event to notify the Cluster Manager and the appropriate application.
Rearm predicate, which is used for Event Manager events. This is a predicate used to generate an event that alters the status of the primary predicate. This predicate is typically the inverse of the primary predicate. It can also be used with the event predicate to establish an upper and a lower boundary for a condition of interest.
Each object requires one line in the event definition, even if the line is not used. If these lines are removed, HACMP ES Cluster Manager cannot parse the event definition properly, and this may cause the system to hang. Any line beginning with "#" is treated as a comment line.
NOTE
The rules file requires exactly nine lines for each event definition, not counting any comment lines. When adding a user-defined event at the bottom of the rules file, it is important to remove the unnecessary empty line at the end of the file, or the server will hang.
HACMP ES uses PSSP event detection to treat user-defined events. The PSSP Event Management subsystem provides comprehensive event detection by monitoring various hardware and software resources.
The process can be summarized as follows:
Either Group Services/ES (for predefined events) or Event Management (for user-defined events) notifies HACMP ES Cluster Manager of the event.
Cluster Manager reads the rules.hacmprd file and determines the recovery program that is mapped to the event.
Cluster Manager runs the recovery program, which consists of a sequence of recovery commands.
The recovery program executes the recovery commands, which may be shell scripts or binary commands. (In HACMP for AIX, the recovery commands are the same as the HACMP event scripts.)
Cluster Manager receives the return status from the recovery commands. An unexpected status "hangs" the cluster until manual intervention (using smit cm_rec_aids or the /usr/sbin/cluster/utilities/clruncmd command) is carried out.
In Figure 3.1, both servers have access to the installation directory, the instance directory, and the database directory. The database instance db2inst is being actively executed on server 1. Server 2 is not active and is being used as a hot standby. A failure occurs on server 1, and the instance is taken over by server 2. Once the failover is complete, both remote and local applications can access the database within instance db2inst. The database will have to be manually restarted or, if AUTORESTART is on, the first connection to the database will initiate a restart operation. In the sample script provided, it is assumed that AUTORESTART is off and that the failover script performs the restart for the database.
Figure 3.1. Failover on a two-server HACMP cluster.
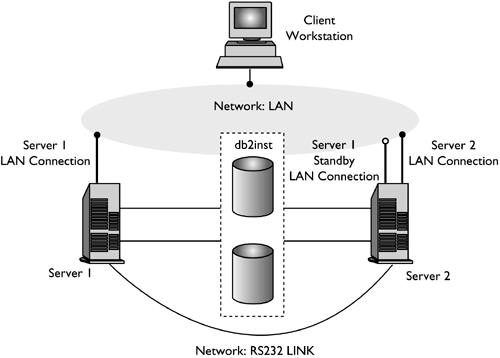
Partition Failover (Hot Standby)
In the following hot-standby failover scenario, we are using an instance partition instead of the entire instance. The scenario includes a two-server HACMP cluster as in the previous example, but the machine represents one of the partitions of a partitioned database server. Server 1 is running a single partition of the overall configuration, and server 2 is being used as the failover server. When server 1 fails, the partition is restarted on the second server. The failover updates the db2nodes.cfg file, pointing to server 2's host name and net name, then restarts the partition on the new server.
Following is a portion of the db2nodes.cfg file, both before and after the failover. In this example, database partition number 2 is running on server 1 of the HACMP machine, which has both a host name and a net name of srvr201. The server 2 srvr202 is running as a hot standby, ready to take over the execution of the partition if there is a failure on srvr201. After the failover, database partition number 2 is running on server 2 of the HACMP machine, which has both a host name and a net name of srvr202.
Before: 1 srvr101 0 srvr101 2 srvr201 0 srvr201 <= HACMP running on primary server db2start dbpartitionnum 2 restart hostname srvr202 port 0 netname srvr202 After: 1 srvr101 0 srvr101 2 srvr202 0 srvr202 <= HACMP running on standby server
Multiple Logical Partition Database Failover
A more complex variation on the previous example involves the failover of multiple logical partition databases from one server to another. Again, we are using the same two server HACMP cluster configuration as above. However, in this scenario, server 1, srvr201, is actively running three logical database partitions while server 2, srvr202, is running as a hot standby, ready to take over the execution of the partition if there is a failure on srvr201. The setup is the same as that for the simple database partition failover scenario but in this case, when server 1 fails, each of the logical database partitions must be started on server 2. It is critical that each logical database partition must be started in the order that is defined in the db2nodes.cfg file: The logical database partition with port number 0 must always be started first.
Following is a portion of the db2nodes.cfg file, both before and after the failover. In this example, there are three logical database partitions defined on server 1 of a two-server HACMP cluster. After the failover, database partitions 2, 3, and 4 are running on server 2 of the HACMP machine, which has both a host name and a net name of srvr202.
Before: 1 srvr101 0 srvr101 2 srvr201 0 srvr201 <= HACMP running on the primary server 3 srvr201 1 srvr201 <= HACMP 4 srvr201 2 srvr201 <= HACMP db2start dbpartitionnum 2 restart hostname srvr202 port 0 netname srvr202 db2start dbpartitionnum 3 restart hostname srvr202 port 1 netname srvr202 db2start dbpartitionnum 4 restart hostname srvr202 port 2 netname srvr202 After: 1 srvr101 0 srvr101 2 srvr202 0 srvr202 <= HACMP running on the standby server 3 srvr202 1 srvr202 <= HACMP 4 srvr202 2 srvr202 <= HACMP
Partition Failover (Mutual Takeover)
In this example, we are running two of the partitions of a multi-partitioned database system on the two separate servers of an HACMP configuration. The database partition for each server is created on the path /db2, which is not shared with other partitions. The following is the contents of the db2nodes.cfg file associated with the overall multi-partition instance before and after the failover. The srvr201 crashes and fails over to srvr202. After the failover, the database partition that was executing on srvr201, which is defined as database partition number 2, starts up on srvr202. Because srvr202 is already running a database partition number 3 for this database, therefore, database partition number 2 will be started as a logical database partition number on srvr202 with the logical port 1.
Before: 1 srvr101 0 srvr101 2 srvr201 0 srvr201 <= HACMP failover server 3 srvr202 0 srvr202 <= HACMP db2start dbpartitionnum 2 restart hostname srvr202 port 1 netname srvr202 After: 1 srvr101 0 srvr101 2 srvr202 1 srvr202 <= srvr201 failover to srvr202 3 srvr202 0 srvr202 <= HACMP
Scenario #1: Hot Standby with a Cascading Resource Group
In this HACMP configuration (hot standby with a cascading resource group), we use HACMP/ES 4.3 and DB2 UDB Enterprise Server Edition running on AIX 4.3.3. The cluster being defined is called dbcluster. This cluster has two servers (dbserv1 and dbserv2), one resource group (db2grp), and one application server (db2as). Because we want the resource group and the application server to be active on the dbserv1 server when there are no failovers, we will define the dbserv1 server in the resource group first. Each of these servers will have two network adapters and one serial port. The servers will have a shared external disk, with only one server accessing the disk at a time. Both servers will have access to a volume group (havg), three file systems (/home/db2inst1, /db1, and /home/db2fenc1), and a logical volume (/dev/udbdata).
If the dbserv1 server has a hardware or software failure, the dbserv2 server will acquire the resources that are defined in the resource group. The application server is then started on the dbserv2 server. In our case, the application server that is started is DB2 UDB ESE for the instance db2inst1. There are failures that would not cause the application to move to the dbserv2 server; these include a disk failure or a network adapter failure.
Here is one example of a failover: DB2 UDB ESE is running on a server called dbserv1; it has a home directory of /home/db2inst1, a database located on the /db1 file system, and a /dev/udbdata logical volume. These two file systems and logical volume are in a volume group called havg. The dbserv2 server is currently not running any application except HACMP, but it is ready to take over from the dbserv1 server, if necessary. Suppose someone unplugs the dbserv1 server. The dbserv2 server detects this event and begins taking over resources from the dbserv1 server. These resources include the havg volume group, the three file systems, the logical volume, and the hostname dbs1.
Once the resources are available on the dbserv2 server, the application server start script runs. The instance ID can log on to the dbserv2 server (now called dbs1) and connect to the database. Remote clients can also connect to the database, because the hostname dbs1 is now located on the db2serv2 server.
Follow these steps to set up shared disk drives and the logical volume manager:
Set up the disk drives.
Create the volume group (VG). The VG must have a unique name and a major number for all servers in the cluster.
Create a JFSLog.
Create the LVs and the JFSs.
Unmount all of the file systems and deactivate the VG. The volume is varied off on the dbserv1 server before it is activated on the dbserver server.
Import the VG on the dbserv2.
Move the active VG to the dbserv1 server.
User Setup and DB2 Installation
Now that the components of the LVM are set up, DB2 can be installed. The db2setup utility can be used to install and configure DB2. To understand the configuration better, we will define some of the components manually and use the db2setup utility to install only the DB2 product and license.
All commands described in this chapter must be invoked by the root user. Although the steps used to install DB2 are outlined below, for complete details, please refer to the DB2 for UNIX Quick Beginnings guide and the DB2 Client Installation Guide.
NOTE
Before any groups or IDs are created, ensure that the volume group is activated and that the file systems /home/db2inst1 and /home/db2fenc1 are mounted.
To install and configure DB2 on the dbserv1 server:
Create the group for the DB2 instance.
Create the user ID for the DB2 instance.
Create the group and user ID for the DB2 fenced ID.
Mount the CD-ROM.
Install DB2 and set up the license key.
Create the DB2 instance.
Install the DB2 HACMP scripts. To copy the HACMP scripts to /usr/bin from /usr/opt/db2_08_01/samples/hacmp/es, use the db2_inst_ha.local command. The db2_inst_ha.local script also copies over the HACMP/ES event stanzas. These events are defined in the db2_event_stanzas file.
Failover $HOME to the dbserv2 server. Repeat steps 1 to 7 on the dbserv2 server.
NOTE
Once DB2 HACMP is configured and set up, any changes made (for example, to the IDs, groups, AIX system parameters, or the level of DB2 code) must be done on both servers.
Following are some examples:
The HACMP cluster is active on the dbserv1 server, and the password is changed on that server. When failover happens to the dbserv2 server and the user tries to log on, the new password will not work. Therefore, the administrator must ensure that passwords are kept synchronized.
If the ulimit parameter on the dbserv1 server is changed, it must also be changed on the dbserv2 server. For example, suppose the file size is set to unlimited on the dbserv1 server. When a failover happens to the dbserv2 server and the user tries to acce






