Space Usage with MDC Tables
The following section will use the table space MDCTS, defined as:
create tablespace mdcts pagesize 4k managed by database using (file 'd:\mdcts' 10000) extentsize 32
and the table T1, defined as:
create table t1(c1 varchar(30), c2 int, c3 int) organize by (c1, c2) in mdcts
for the basis of discussion.
Before creating the table, there will be four extents used for the container tag and three extents of table space overhead. The LIST TABLESPACES command does not show the pages used by the container tag, so the output of the command would show three extents used as follows:
Tablespace ID = 3 Name = MDCTS Type = Database managed space Contents = Any data State = 0x0000 Detailed explanation: Normal Total pages = 10000 Useable pages = 9952 Used pages = 96 Free pages = 9856 High water mark (pages) = 96 Page size (bytes) = 4096 Extent size (pages) = 32 Prefetch size (pages) = 32 Number of containers = 1
Creating a table will use two extents for the data object and its extent map, two extents for the index object and its extent map, and two extents for the MDC table's block map and its extent map.
NOTE
The first block or extent (Extent 0) of an MDC data object cannot hold any rows.
A block map is used to determine quickly and efficiently whether there are blocks in the table that have been emptied and disassociated from any existing cells and are therefore available for reuse. If there are no blocks available, a new block (extent) will need to be created in the table, and the block map will be extended to account for the new block. Therefore, creating the above table will require six additional extents in the table space. The output of the LIST TABLESPACES command after the table has been created would look like the following:
Tablespace ID = 3 Name = MDCTS Type = Database managed space Contents = Any data State = 0x0000 Detailed explanation: Normal Total pages = 10000 Useable pages = 9952 Used pages = 288 Free pages = 9664 High water mark (pages) = 288 Page size (bytes) = 4096 Extent size (pages) = 32 Prefetch size (pages) = 32 Number of containers = 1
When an MDC table is created, DB2 will automatically build at least one index, the block dimension index. Additional dimension indexes may also be created.
For the above table, there will be a block dimension index created on C2, C1. In addition, there will be two dimension indexes created, one on C1 and one on C2. To examine the indexes that are created, use the following statement:
select indname, colnames, indextype from syscat.indexes where tabname ='T1'
This statement would produce the following output:
INDNAME COLNAMES INDEXTYPE ------------------ -------- --------- SQL021118211811590 +C2+C1 BLOK SQL021118211811770 +C2 DIM SQL021118211811780 +C1 DIM
As illustrated above, a dimension block index has a type of BLOK, and a dimension index has a type of DIM.
NOTE
A normal RID index will have a type of REG.
Given the following delimited ASCII file, named file.del:
aaaaaaa, 11, 9 bbb, 22, 10 cccccc, 33, 11 bbb, 22, 7 dddd, 44, 5
If the data is loaded into the MDC table t1 as follows:
load from file.del of del insert into t1
the data is selected from the table t1 as follows:
select * from t1
and the data is returned as follows:
C1 C2 C3 ------- ------- ------- aaaaaaa 11 9 bbb 22 10 bbb 22 7 cccccc 33 11 dddd 44 5
The sequence of rows returned is different from the sequence in which they were entered. The fourth row (bbb, 22, 7) in the input file is the third row in the output of the SELECT statement. The rows are retuned in this order because an MDC table places the rows with the same dimension keys, which are the values on dimension columns, in the same block. Therefore, the rows (bbb, 22, 10) and (bbb, 22, 7) are in the same block in the table and will therefore be read at the same time, and returned before the blocks containing (cccccc, 33, 11) and (dddd, 44, 5).
NOTE
No special options are required to load into an MDC table.
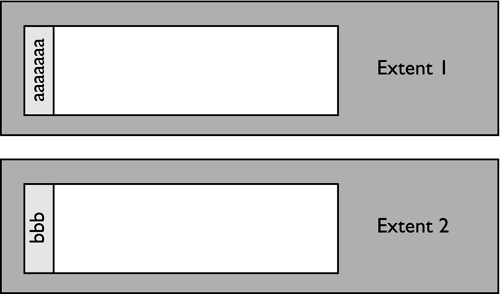
In the above example, when the first row from the file is loaded, a new extent will be created, and the row will be placed in Extent 1 for the table. Therefore, the table would logically look like:

When the second row from the file is loaded, a new extent will be created, and the row will be placed in Extent 2 of the table. The table now logically looks like:
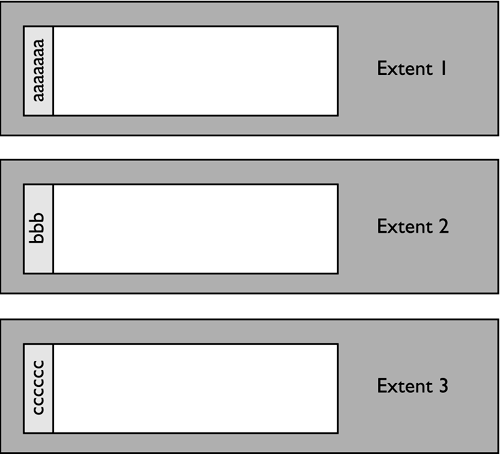
When the third row from the file is loaded, a new extent will be created, and the row will be placed in Extent 3 of the table. The table would logically look like:
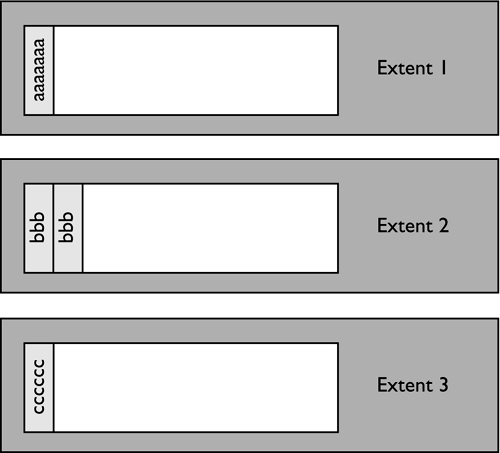
When the fourth row from the file is loaded, the data in the dimension columns is the same as in row 2; therefore, the row will be placed in the same extent as row 2 (Extent 2). The table now logically looks like:
When the fifth row from the file is loaded, a new extent will be created, and the row will be placed in Extent 4 of the table. The table now logically looks like:
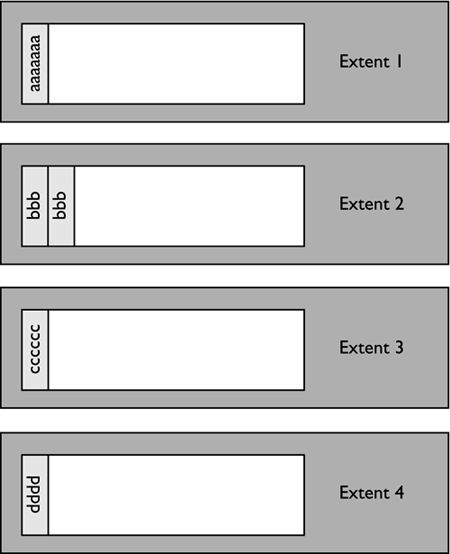
Therefore, an additional four extents of data are created when inserting the data into the table. In total, there would be 10 extents used for this data, the block map, and the indexes for this table.
The next example uses the following table:
create table city(name char(30), zipcode char(10), state char(2)) organize by (state)
with the following data inserted into the table:
Phoenix, 85001, AZ Los Angeles 90001, CA Tempe, 85820, AZ San Francisco, 94101, CA Boston, 02101, MA San Diego, 92126, CA Tiburon, 94920, CA Buffalo, 14201, NY Albany, 12202, NY Chicago, 60601, IL Kansas City, 64101, MO Kansas City, 66101, KS
This will require seven new extents in the table's data object because there are seven distinct values for the dimension column, STATE.
When the data is selected from the table CITY, as follows:
select * from city
the data is returned as follows:
NAME ZIPCODE STATE ------------- ------- ----- Phoenix 85001 AZ Tempe 85280 AZ Los Angeles 90001 CA San Francisco 94101 CA San Diego 92126 CA Tiburon 94920 CA Boston 02101 MA Buffalo 14201 NY Albany 12201 NY Chicago 60601 IL Kansas City 64101 MO Kansas City 66101 KS
The table would logically look like Figure 5.7.
Figure 5.7. Logical view of the MDC table.







