Chapter 1. Data Storage
In order for a database to perform well, it must be able to efficiently store and quickly retrieve, search, and manipulate large amounts of data. Within a DB2 database, data is stored on disk and must be read into memory in order to be searched and manipulated. On disk, the data is stored within table spaces, and when the data and/or indexes are needed to build the result set for a particular query, the required pages must be read from the table space(s) into the buffer pool before they can be manipulated or searched. When designing a database system, these two elements, I/O and memory, are two of the most important elements in ensuring the overall performance of the database system. This chapter will focus on the design and implementation of the physical storage model for the database. Chapter 2 will focus on the design of the database buffer pool(s) for optimal data access.
In order for DB2 to scan a table or an index, the pages of the table or index must be in the database's buffer pool(s). The buffer pool(s) are the work area for the database, and all searching for and manipulation of the data and indexes must take place within the buffer pool(s). In order for the data and index pages to be manipulated, they must be within the buffer pool. If the page is already in the buffer pool, then DB2 can start to work on the page immediately. If the page is not in the buffer pool, DB2 must read the page from disk and position it in the buffer pool(s). Therefore, the physical placement of the data (and indexes) will have a direct effect on the overall performance of the database system. To design and build a database that will meet performance expectations, the database administrator must understand the concepts of data placement and data manipulation in order to create an appropriate physical database design.
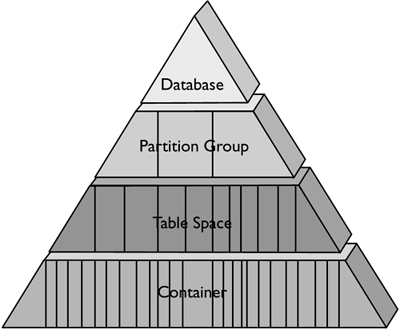
Within a DB2 database, the storage of the data and indexes is defined and controlled at four different levels. To accommodate partitioned databases, there is an abstract layer referred to as partition groups, as shown in Figure 1.1. A partition group is a grouping or collection of one or more database partitions within a database. When a table space is created, it is assigned to a partition group and will be created only on the database partitions that are part of the partition group. Each table space must have one or more containers that define the physical storage for the table space. A container can be an operating system directory, a file with a predetermined size, or a raw device, such as an unformatted hard drive, a partition on the hard drive, or a logical volume.
Figure 1.1. The DB2 storage triangle.
NOTE
LOB and Long Varchar columns are not manipulated in the database buffer pools. All access to LOB and Long Varchar data will occur directly to disk.






