Parallelism
The exploitation of parallelism within a database and within an application accessing a database can also have a significant benefit for overall database performance, as well as the normal administrative tasks. There are two types of query parallelism that are available with DB2 UDB: inter-query parallelism and intra-query parallelism.
Inter-query parallelism refers to the ability of multiple applications to query a database at the same time. Each query will execute independently of the others, but DB2 UDB will execute them at the same time.
Intra-query parallelism refers to the ability to break a single query into a number of pieces and replicate them at the same time using either intra-partition parallelism or inter-partition parallelism, or both.
Intra-Partition Parallelism
Intra-partition parallelism refers to the ability to break up a query into multiple parts within a single database partition and execute these parts at the same time. This type of parallelism subdivides what is usually considered a single database operation, such as index creation, database load, or SQL queries into multiple parts, many or all of which can be executed in parallel within a single database partition. Intra-partition parallelism can be used to take advantage of multiple processors of a symmetric multiprocessor (SMP) server.
Intra-partition parallelism can take advantage of either data parallelism or pipeline parallelism. Data parallelism is normally used when scanning large indexes or tables. When data parallelism is used as part of the access plan for an SQL statement, the index or data will be dynamically partitioned, and each of the executing parts of the query (known as package parts) is assigned a range of data to act on. For an index scan, the data will be partitioned based on the key values, whereas for a table scan, the data will be partitioned based on the actual data pages.
Pipeline parallelism is normally used when distinct operations on the data can be executed in parallel. For example, a table is being scanned and the scan is immediately feeding into a sort operation that is executing in parallel to sort the data as it is being scanned.
Figure 2.2 shows a query that is broken into four pieces that can be executed in parallel, each working with a subset of the data. When this happens, the results can be returned more quickly than if the query was run serially. To utilize intra-partition parallelism, the database must be configured appropriately.
Figure 2.2. Intra-partition parallelism.
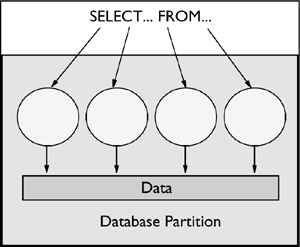
Intra-partition parallelism must be enabled for the DB2 instance before the queries can be executed in parallel. Once intra-partition parallelism is enabled, the degree of parallelism, or number of pieces of the query that can execute in parallel, can be controlled using database configuration parameters.
Configuring Intra-Partition Parallelism
Intra-partition parallelism in DB2 UDB is enabled or disabled using the database manager configuration parameter INTRA_PARALLEL. To enable intra-partition parallelism in DB2 UDB, the INTRA_PARALLEL configuration must be set to YES. This can be done using the following command:
UPDATE DBM CFG USING INTRA_PARALLEL YES
The degree of parallelism can then be controlled at the instance level, the database level, the application, or the statement level. The degree of parallelism can be set to a specific value or to ANY. If the degree of parallelism is set to ANY, the optimizer will determine the degree of parallelism for each individual SQL query that is submitted, based on the query itself and the number of CPUs available to the database or database partition.
Table 2.2 gives an overview of the parameters and options that are related to intra-partition parallelism in DB2 UDB.
Parameter | Value |
|---|---|
INTRA_PARALLEL | YES/NO Defaults to NO on uni-processor machine Defaults to YES on SMP machine If changed, packages already bound will automatically be rebound at next execution. |
MAX_QUERYDEGREE | 1?32767, ANY Defaults to ANY; allows optimizer to choose degree of parallelism based on cost. No SQL executed on a database in this instance can use a degree of parallelism higher than this value. |
DFT_DEGREE | 1?32767, ANY Defaults to 1 (no parallelism) Provides the default value for:
|
CURRENT DEGREE | 1?32767, ANY Sets degree of parallelism for dynamic SQL Defaults to DFT_DEGREE |
DEGREE | 1?32767, ANY Sets degree of parallelism for static SQL Defaults to DFT_DEGREE
|
RUNTIME DEGREE (SET RUNTIME DEGREE command) | 1?32767, ANY Sets degree of parallelism for running applications To change:
Affects only queries issued after SET RUNTIME is executed |
DB2DEGREE (CLI configuration file) | 1?32767, ANY Default is 1 Sets degree of parallelism for CLI applications CLI application issues a SET CURRENT DEGREE statement after database connection |
The maximum degree of parallelism for an active application can be specified using the SET RUNTIME DEGREE command. The application can set its own run time degree of parallelism by using the SET CURRENT DEGREE statement. The actual run time degree used is the lower of:
MAX_QUERYDEGREE instance configuration parameter
Application run time degree
SQL statement compilation degree
More information on parallelism support in DB2 Universal Database can be found in the DB2 UDB Administration Guide: Performance.
For a multi-partitioned database on a large SMP server, the maximum degree of parallelism for each partition should be limited so that each partition does not attempt to use all of the CPUs on the server. This can be done using the MAX_QUERYDEGREE instance configuration parameter. For a 32-way SMP server with eight database partitions, the maximum degree of parallelism for each partition could be limited to four, as follows:
UPDATE DBM CFG USING MAX_QUERYDEGREE 4
For an SMP server with 16 CPUs, running two separate DB2 instances, the maximum degree of parallelism for each partition could be limited to eight, as follows:
UPDATE DBM CFG USING MAX_QUERYDEGREE 8
for a DB2 instance with two databases that has intra-partition parallelism enabled. The benefit of intra-partition parallelism is very different if one database is a data mart or data warehouse and has large, complex queries scanning a large amount of data and the other database is used as a journal and is accessed using only INSERT statements. In this case, the default degree of parallelism can be set to different values for each database. If the databases are named DMDB and JRNLDB, this can be done as follows:
UPDATE DB CFG for DMDB USING DFT_DEGREE 8 UPDATE DB CFG for JRNLDB USING DFT_DEGREE 1
For CLI, ODBC, and JDBC applications, the degree of parallelism is controlled using the db2cli.ini file. The following is an example db2cli.ini file where any application that connects to the SAMPLE database will use a degree of parallelism of four.
[common] TRACE=1 Turn the trace on TRACECOMM=1 Trace communications costs as well TRACEFLUSH=1 Flush the trace as it happens TRACEPATHNAME=d:\trace Directory for the trace. ; Comment lines start with a semi-colon. [sample] DBALIAS=MYSAMP DB2DEGREE=4 autocommit=0
To change the degree of parallelism for a currently executing SQL statement, the SYSADM can change the run time degree for an application. For an application with an application ID of 130, to change the degree of parallelism to 2, the following command can be used:
SET RUNTIME DEGREE FOR (130) to 2
NOTE
This change cannot affect the currently executing SQL statement but will be effective for all subsequent SQL statements.
Applications and Intra-Partition Parallelism
When an application connects to a nonpartitioned database, the connection is assigned to a coordinating agent, and all subsequent SQL statements and DB2 commands are executed by the coordinating agent on behalf of the application. If intra-partition parallelism is enabled, when an SQL statement is executed, the coordinating agent will determine the degree of parallelism to be used to execute the statement based on the access plan and the database and instance configuration parameters. The coordinating agent will then make n copies of the access plan, where n is the degree of parallelism and will execute each copy of the plan on its own subagent. Therefore, for an access plan with a degree of parallelism of eight, there will be eight subagents and one coordinating agent used to execute the plan and return the data.
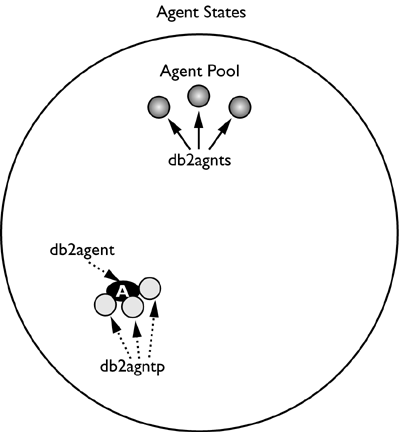
On a UNIX system, the coordinating agent and subagent processes will have different names. The coordinating agent process will be named db2agent, and the subagent process will be named either db2agntp or db2agnts, depending on whether the process is currently idle or working. An idle subagent will be named db2agnts, and a working subagent will be named db2agntp. In Figure 2.3, coordinating agent A has two subagents associated to it; therefore, the statement that it is currently executing has a degree of parallelism of 2. If coordinating agent A next runs an SQL statement with a degree of parallelism of 3, it must acquire another subagent in order to execute the access plan, as depicted in Figure 2.4.
Figure 2.3. Agent states with intra-parallel enabled.
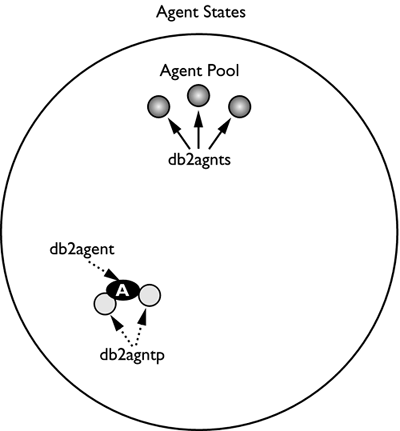
Figure 2.4. Degree of parallelism of 3.
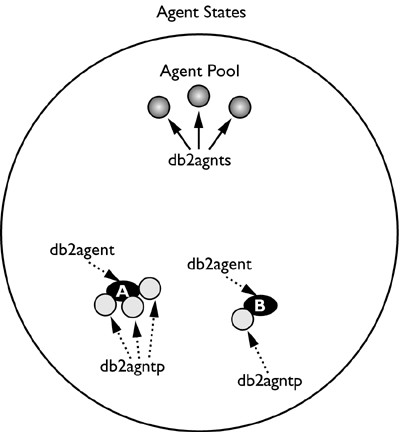
If another application connects to the database and executes an SQL statement that has a degree of parallelism of 1, the agent pool would look like Figure 2.5. In this case, there will be three subagent processes associated with coordinating agent A and one subagent process associated with coordinating agent B.
Figure 2.5. Two applications executing with varying degrees of parallelism.
The subagents are called associated because they have an affiliation with the coordinating agent and have control blocks and shared inter process communication (IPC) blocks set up to communicate between the coordinating agent and its associated subagents.
If the application that is connected to coordinating agent B finishes its current SQL statement, its associated subagent will become idle but will remain associated with its coordinating agent. It remains associated because there is a chance that it may be needed in the future for a subsequent statement, and it is inefficient to break its association to release it back to the idle agent pool if it may be needed again.
If the application connected to coordinating agent A completes the current statement and runs a subsequent statement with a degree of parallelism of 2, one of its subagents will become idle but will remain associated with coordinating agent A. The agent pool would then look like that in Figure 2.6.
Figure 2.6. Summary of agent states.
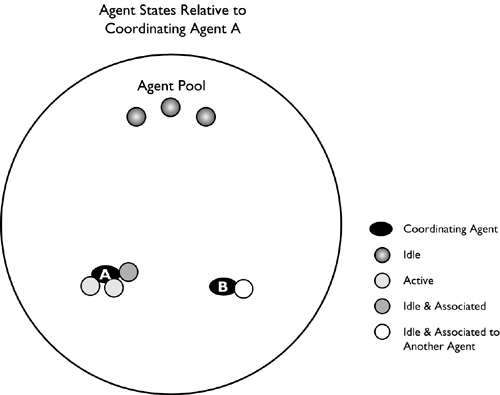
Figure 2.6 shows all of the states that agents and subagents can be in within the agent pool. Within the pool, there are three idle agents waiting to be called on by either of the existing coordinating agents or by a subsequent application connecting to the database. Coordinating agent B is idle, but its application has not yet disconnected from the database, so the agent and its associated subagents will remain to service any subsequent SQL statements or until the application disconnects. If the application disconnects, the coordinating agent and its subagents will be returned to the agent pool as idle agents.
Coordinating agent A is currently executing an SQL statement with a degree of parallelism of 2; therefore, the coordinating agent and two of its associated subagents are busy. The third subagent is idle but remains associated to coordinating agent A.
If the current statement executing in coordinating agent A completes and the next SQL statement has a degree of parallelism of 8, the coordinating agent must make active and/or acquire a number of additional subagents. The activation and acquiring of these subagents will be done in an order that helps ensure the optimal usage of the agents and available resources. The agents will be acquired in the following order:
Convert any idle subagents currently associated to the coordinating agent to active.
Convert any idle subagents not currently associated to another coordinating agent to active (i.e., in the idle agent pool).
Convert any idle subagents currently associated to another coordinating agent to active.
Create a new agent process.
For this example, the idle subagent currently associated with coordinating agent A would be converted to active. The three idle agents in the pool would be associated with coordinating agent A and made active. The idle subagent currently associated with coordinating agent B would be unassociated from coordinating agent B, associated with coordinating agent A, and made active. One additional agent process would need to be created, associated with coordinating agent A and made active; then the SQL statement could be processed.
For a large, complex query, intra-partition parallelism is good, and the result set can normally be returned much quicker this way. However, an insert of a single does not require nine (eight subagents plus the coordinating agent) agents. In a typical OLTP environment, there are normally hundreds (if not more) of applications running in parallel. If each of them were assigned nine agent processes to handle their simple tasks, there would be far too many agent processes running on the system, causing a great deal more system overhead than is required.
In addition, when intra-partition parallelism is enabled, an instance level control block is set up by DB2, and each statement that is performed on any database in the DB2 instance will require a check of this control block during the statement's optimization and execution. Even if intra-partition parallelism is disabled for a database by setting the maximum degree of parallelism or default degree of parallelism to 1, this control block will still be checked during the optimization and execution of each statement. Therefore, it is best to disable intra-partition parallelism, using the database manager configuration parameter INTRA_PARALLEL.
Inter-Partition Parallelism
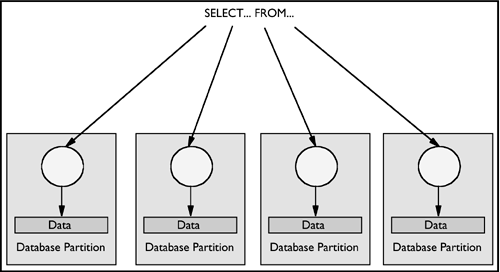
Inter-partition parallelism refers to the ability to break up a query into multiple parts across multiple partitions of a partitioned database on a single server or between multiple servers. The query will be executed in parallel on all of the database partitions. Inter-partition parallelism can be used to take advantage of multiple processors of an SMP server or multiple processors spread across a number of servers.
Figure 2.7 shows a query that is broken into four pieces that can be executed in parallel, with the results returned more quickly than if the query was run in a serial fashion in a single partition. In this case, the degree of parallelism for the query is limited by the number of database partitions.
Figure 2.7. Inter-partition parallelism.
Combined Intra-Partition Parallelism and Inter-Partition Parallelism
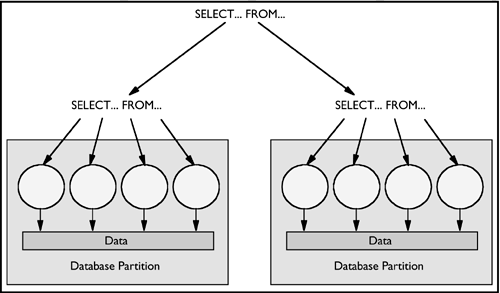
In a partitioned database, intra-partition parallelism and inter-partition parallelism can be combined and used at the same time (Figure 2.8). This combination provides, in effect, two dimensions of parallelism. This results in an even more dramatic increase in the speed at which queries are processed. Combined intra-partition and inter-partition parallelism can be used to take advantage of multiple processors of a single or multiple SMP servers.
Figure 2.8. Combined intra-partition and inter-partition parallelism.
Why Partition a Database on a Large SMP Server?
Although DB2 can break a query into a number of pieces that can be executed in parallel, the scalability of DB2 with intra-partition parallelism can be limited or restricted only by the operating system and hardware on which DB2 is installed.
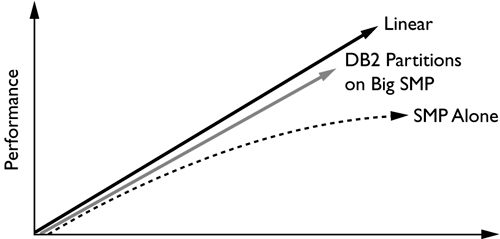
Creating multiple database partitions within a larger SMP server has proven to provide better scalability than intra-partition parallelism alone. As the number of CPUs grows, the scalability decreases when using intra-partition parallelism alone. By creating multiple database partitions within the SMP server, the scalability will remain almost linear. In a recent test of DB2 with multiple database partitions on a single SMP server growing from 6 to 24 CPUs (Figure 2.9), DB2 was able to deliver a speedup of 23.9 times on query response time.
Figure 2.9. Comparing query scaling on large SMP servers.
Considerations with Multiple Database Partitions
In a partitioned database, the partition or partitions that will accept connection requests from clients are known as coordinator partitions. Because DB2 will automatically route all requests to the underlying database partitions, not all partitions need to be configured as coordinator partitions. In fact, when DB2 is configured with multiple database partitions within a single server, only one database partition per server can be a coordinator. The first database partition on the server listed in the db2nodes.cfg file is the only database partition that can be a coordinator partition.
Because the database partitions share a common install path and home directory, the listener port for the partitions, as defined in the database manager configuration, is the same for all database partitions on the same server. Because the database partitions cannot use the same listener process, only one partition per server can be a coordinator.
This should be taken into consideration when choosing where to create database partition groups within the database. Database partition groups that will be created on a single partition may benefit from being placed on database partitions that can be coordinators. Accessing tables in a single partitioned database partition group that is not a coordinator requires the coordinator to receive the SQL statement, then to pass it to the database partition where the SQL statement will be executed. The extra overhead of the coordinator partition "handling" the request and sending it to the affected database partition is not significant if the operation is complex and accesses a large amount of data. A transactional environment, where only a single row may be updated, can result in increased response time. However, DB2 provides a method to achieve maximum scalability and throughput, even for single-row selects or updates, known as local bypass.
Local Bypass
There is an API that can be called within the application to determine on which database partition the particular row is stored so that the application can then call another API to connect directly to the identified partition and read/update/delete the row.
These APIs are:
sqlugtpi ? Get partition information for the table being worked on
sqlugrpn ? Determine the partition to connect to
There are some important considerations when using these APIs that need to be noted:
As noted previously, only one database partition per server can be a coordinator; therefore, even if the application is directed to another partition on the server, it will be handled by the first database partition on the server. The communication between partitions within the same server uses shared memory to reduce the overhead associated with TPC/IP.
These APIs can be invoked from only one of the servers identified in the db2nodes.cfg file.
They cannot be called in an application running on Windows if the database is on a UNIX server.
The application must be running on the same server as one of the database partitions.
Some pseudo-code to show the use of the above APIs:
[View full width]//create an array of connections as the connection pool to use. SQLHDBC hDbc[NumOfNodes]; // will have one connection for each logical node SQLAllocEnv(&hEnv); for (NodeNum=0; NodeNum < NumOfNodes; NodeNum++) { SQLAllocHandle(SQL_HANDLE_DBC, henv, hdbc); // used to be SQLAllocConnect SQLSetConnectAttr(hDbc[NodeNum], SQL_ATTR_CONNECT_NODE, NodeNum); SQLConnect(hDbc[NodeNum], "Your_DB_NAME"); } // Now you have one connection for each logical node ready. // Need to get the partition information for the table you are working on // See last sample for more information about this part strcpy(table_name, dbname); strcat(table_name, "table_name"); sqlugtpi( table_name, &part_info, &sqlca_inst ); if(check_error("sqlugtpi failed", &sqlca_inst)!=0){ exit(-1); } // Say you got your primary key value and want to see which node you want to connect anddo your SQL // See last sample for more information about this part key_value[0] = malloc(10); sprintf(key_value[0],"%d", YouKeyValue); key_len[0] = strlen(key_value[0]); sqlugrpn( part_info.sqld, key_value, key_len, ctrycode, codepage, &part_info, &part_number, &node_number, chklvl, &sqlca_inst, SQL_CHARSTRING_FORMAT, (void*)0, (void *)0 ); if(check_error("sqlugrpn failed", &sqlca_inst)!=0){ exit(-1); } // node_number is the node you need to connect // Then you just need to use the connection handle hDbc[node_number] // here is more CLI stuff for running your sql, consulting the CLI documentation SQLAllocStmt(hDbc[node_number], & hStmt); SQLPrepare(hStmt, "Your SQL Statement String like select * from ...."); << ... more statement specific calls to bind the columns and parameters, etc. >> SQLExect(hStmt); SQLFetch(.....) SQLFreeStmt(....)
Multiple Database Partitions within a Single Server
When configuring multiple database partitions on the same server, it is important that each database partition have sufficient resources in order to perform optimally. Each database partition contains a number of processes (or threads on Windows), and it is important to ensure that there are enough CPU cycles available to execute these processes. To ensure that there are sufficient CPU resources available, it is recommended that the ratio of database partitions to CPUs not exceed 1:1, i.e., do not create more database partitions on a server than there are CPUs in the server.
Depending on the speed and relative processing power of the CPUs on the server, a ratio of CPUs to database partitions of 1:1 or 2:1 will normally give the best performance. For most servers, a ratio of CPUs to database partitions of 2:1 will provide the best performance; however, with faster processors, such as the IBM pSeries P690 (Regatta), it is possible to reduce this ratio to 1:1 if needed.
For a database with multiple database partitions on the same server, DB2 UDB can use shared memory to communicate between the database partitions instead of using the network interconnect. The use of shared memory improves the performance of inter-partition communication but must be enabled using the DB2 registry variable DB2_FORCE_FCM_BP. Any inter-partition communication between database partitions on different servers will still use the dedicated interconnect; however, all inter-partition communication between database partitions on the same server will use shared memory, as shown in Figure 2.10.
Figure 2.10. Inter-partition communication within and between servers.
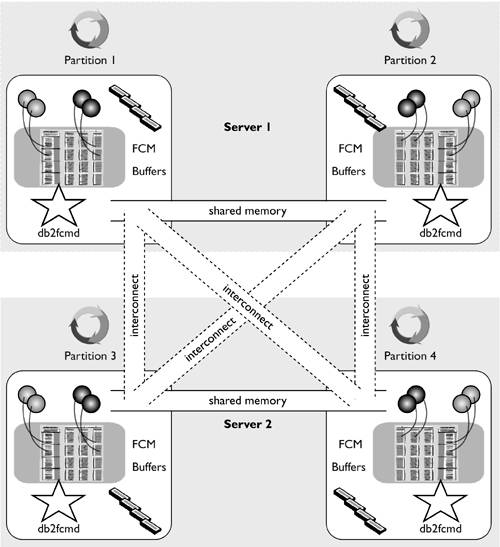
One of the features available with the IBM pSeries P690 server is the ability to create logical servers within a large SMP server, using logical partitions (LPARs). This is a good way to separate different DB2 UDB instances within a single server and ensure that each partition gets dedicated resources. However, it may not be an optimal way of separating database partitions for the same database within a server. Currently, the only way to communicate between LPARs on the same server is using a network interconnect because the LPARs cannot currently communicate using any optimized methods, such as shared memory. Therefore, when creating multiple database partitions on the same IBM pSeries P690 server, it is normally best not to use LPARs so that the inter-partition communication can benefit from the use of shared memory.
An additional benefit of this approach is that when some database partitions are not as busy as others, they can take advantage of all of the resources available on the server and not be constrained to the resources assigned to the LPAR.
NOTE
This is also true with the Sun E10000 and E15000 servers that support a concept similar to LPARs, called domains.






