Materialized Query Tables
A materialized query table (MQT) is a table that is defined based on the result of a query of one or more base tables. Prior to v8.1, MQTs required an aggregation operator in their defining SQL and, thus, were called Automatic Summary Tables. The next section describes how MQTs can provide effective performance improvements in a database.
Avoiding Repetitious Calculations
Materialized query tables can help to avoid having to repeat calculations, such as SUMs, for a number of queries that reference the same base table. For a CUSTOMER_ORDER table that stores customer orders for a number of years, the table will grow very large. If the applications run multiple queries on orders for only the year 2002, and only three columns from the table are used in these queries, such as:
select SUM(AMOUNT), trans_dt from db2inst2.CUSTOMER_ORDER where trans_dt between '1/1/2002' and '12/31/2002' group by trans_dt
or
select SUM(AMOUNT), status from db2inst2.CUSTOMER_ORDER where trans_dt between '1/1/2002' and '12/31/2002' group by status
the queries can be executed using index scans, assuming that the table is indexed appropriately. The explain plan below is an excerpt from the first statement above, and it shows that the query has an execution cost of 152455 timerons, to retrieve only 378 rows.
-------------------- SECTION --------------------------------------- Section = 1 SQL Statement: select SUM(AMOUNT), trans_dt from db2inst2.CUSTOMER_ORDER where trans_dt between '1/1/2002' and '12/31/2002' group by trans_dt Estimated Cost = 152455 Estimated Cardinality = 378
Creating an MQT that contains the columns being selected and precomputes the sum can lead to a substantial savings in execution time. For this example, the MQT should be created as follows:
CREATE TABLE DB2INST2.SUMMARY_CUSTOMER_ORDER_2002 AS (SELECT SUM(AMOUNT) AS TOTAL_SUM, TRANS_DT, STATUS FROM DB2INST2.CUSTOMER_ORDER WHERE TRANS_DT BETWEEN '1/1/2002' AND '12/31/2002' GROUP BY TRANS_DT, STATUS) DATA INITIALLY DEFERRED REFRESH DEFERRED;
The clause DATA INITIALLY DEFERRED instructs DB2 not to insert the data into the MQT as part of the CREATE TABLE statement. Instead, the DBA will have to perform a REFRESH TABLE statement to populate the MQT. The clause REFRESH DEFERRED indicates that the data in the table reflects the result of the query as a snapshot only at the time the REFRESH TABLE statement was issued. For more information on creating MQTs, see the SQL Reference.
To populate the MQT created above, issue the following statement:
REFRESH TABLE DB2INST2.SUMMARY_CUSTOMER_ORDER_2002;
Once the MQT has been populated, queries run against the MQT can run much faster than queries run against the base table, because the MQT contains many fewer rows, and the SUM has already been precomputed. An excerpt from the execution once the MQT has been created and populated shows a dramatic performance improvement, with an estimated cost of 101 timerons versus the original cost of 152455 timerons.
-------------------- SECTION --------------------------------------- Section = 1 SQL Statement: select sum(total_sum), trans_dt from db2inst2.summary_customer_order_2002 where trans_dt between '1/1/2002' and '12/31/2002' group by trans_dt Estimated Cost = 101 Estimated Cardinality = 25
NOTE
If the data in the CUSTOMER_ORDER table for the year 2002 gets updated after the MQT was refreshed, the MQT may need to be refreshed again.
For an MQT based on a table that changes frequently, it may be best to use the REFRESH IMMEDIATE option when creating the MQT to enable DB2 to update the MQT automatically as the base table is being updated.
Avoiding Resource-Intensive Scans
Assume a set of frequently executed reports that query up-to-date totals for the year 2002. The reports, which used to run very quickly in January, are now running more and more slowly as the amount of data for the year increases. Assume also that the table is indexed appropriately and the queries are being executed using index scans.
MQTs can be used to help improve performance in this case, as well. However, because the data is being updated all the time and the reports need current data, the MQT cannot be defined using the REFRESH DEFERRED option, because the MQT will get out of sync with the base table the next time the base table is updated. For an MQT based on a table that changes frequently, the REFRESH IMMEDIATE option should be used when creating the MQT to enable DB2 to update the MQT automatically as the base table is being updated. The MQT can be created as follows:
CREATE TABLE DB2INST2.SUMMARY_CUSTOMER_ORDER_2002 AS( SELECT TRANS_DT, STATUS, COUNT(*) AS COUNT_ALL, SUM(AMOUNT) AS SUM_AMOUNT, COUNT(AMOUNT) AS COUNT_AMOUNT FROM DB2INST2.CUSTOMER_ORDER GROUP BY TRANS_DT, STATUS) DATA INITIALLY DEFERRED REFRESH IMMEDIATE ENABLE QUERY OPTIMIZATION
NOTE
Although the statement above is interested only in SUM(AMOUNT), it is best to include the COUNT(*) and COUNT(AMOUNT) in the full select. This helps to optimize the maintenance of the MQT. An example follows.
To enable the optimizer to choose the MQT automatically, even when it is not explicitly referenced in the query, as we did in the example above, the ENABLE QUERY OPTIMIZATION must be in effect. This option is the default.
If all of the records for a given date are being deleted from the base table, as in the statement:
DELETE FROM DB2INST2.CUSTOMER_ORDER WHERE TRANS_DT = '4/21/2002'
DB2 must detect that all of the records for a particular date are now deleted and delete all of the corresponding records in the MQT. Having the COUNT field allows DB2 to do this quickly, without having to scan either the table or its index. The COUNT(AMOUNT) is required only when the AMOUNT column is nullable.
Because this table was created with the REFRESH DEFERRED option, the MQT must be populated manually, as follows:
REFRESH TABLE DB2INST2.SUMMARY_CUSTOMER_ORDER_2002;
Because the table (MQT) has been enabled for optimization, it is also good practice to gather statistics on the table, as follows:
RUNSTATS ON TABLE DB2INST2.SUMMARY_CUSTOMER_ORDER_2002 WITH DISTRIBUTION
The query above can now be routed to the MQT in the query rewrite phase of the optimization, and its new access plan would look like the following:
-------------------- SECTION --------------------------------------- Section = 1 SQL Statement: select SUM(AMOUNT), trans_dt from db2inst2.customer_order where trans_dt >= '1/1/2002' group by trans_dt Estimated Cost = 392 Estimated Cardinality = 268
The detailed access plan shows that the optimizer is using the MQT (Summary Table) to resolve this query, even though the query is selected from the CUSTOMER_ORDER table, not the MQT:
Subsection #1: Access Summary Table Name = DB2INST2.SUMMARY_CUSTOMER_ORDER_2002 ID = 2,46 | #Columns = 2 | Relation Scan
Whenever the CUSTOMER_ORDER table is modified, an exclusive table lock may be obtained and held on the MQT SUMMARY_CUSTOMER_ORDER_2002 until the end of the transaction. That is true only for MQTs with aggregate functions created with the REFRESH IMMEDIATE option. Therefore, transactions modifying relevant fields in the CUSTOMER_ORDER table (including all inserts, updates, and deletes) must be kept very short to reduce lock contention. This issue does not apply to MQTs created with the REFRESH DEFERRED option, nor to replicated MQTs (described in the next section).
Enabling Collocated Joins Using Replicated MQTs
In a partitioned database, the performance of joins can be greatly enhanced through collocation of rows of the different tables involved in the join. Figure 6.15 describes such an environment, where the STORE and TRANS tables have both been partitioned on the STOREID column. An SQL query that requires a join on the STOREID column will see significant performance benefits from this partitioning scheme because of the greater parallelism achieved through collocated joins.
Figure 6.15. Replicating tables for collocation.
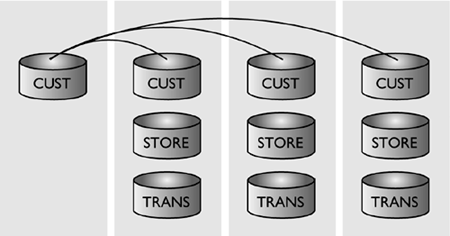
However, when the CUST table is also involved in the join, then a collocated join is not possible, because the CUST table does not have a STOREID column and, therefore, cannot be partitioned by STOREID. Although DB2 UDB can choose to perform a directed join in this particular case, the performance would be less efficient than that of a collocated join, because the movement of data rows occurs during the query execution.
A materialized query table can be used to replicate tables to other database partitions to enable collocated joins, even when not all of the tables are joined on the partitioned key. In Figure 6.15, the CUST table is replicated to the other database partitions using the materialized query table infrastructure in order to enable collocated joins for superior performance.
For another example, the table CUSTOMER_ADDRESS has a reference to another table, ZIP_CODE, but the CUSTOMER_ADDRESS and ZIP_CODE tables are not collocated. However, these two tables are very frequently joined. Without a replicated MQT, the access plan would look like the following. In this case, every time a query is issued that causes the join, it is necessary to broadcast the entire ZIP_CODE table to every database partition.
NOTE
Access plans will be discussed in more detail later in this chapter, so this section will examine only the relevant pieces of the explain plan.
-------------------- SECTION --------------------------------------- Section = 1 SQL Statement: select c.*, z.zip, z.state_name, z.country_name from db2inst2.customer_address c join db2inst2.zip_code z on c.zip_cd = z.zip_cd Estimated Cost = 100975 Estimated Cardinality = 255819 Coordinator Subsection: Distribute Subsection #2 | Broadcast to Node List | | Nodes = 0, 1 Distribute Subsection #1 | Broadcast to Node List | | Nodes = 0, 1 Access Table Queue ID = q1 #Columns = 38 Return Data to Application | #Columns = 38 Subsection #1: Access Table Queue ID = q2 #Columns = 4 | Output Sorted | | #Key Columns = 1 | | | Key 1: (Ascending) Nested Loop Join . . . Insert Into Asynchronous Table Queue Completion ID = q1 Subsection #2: Access Table Name = DB2INST2.ZIP_CODE ID = 2,590 | #Columns = 4 | Relation Scan | | Prefetch: Eligible . . . | | Broadcast to All Nodes of Subsection 1 | | Rows Can Overflow to Temporary Table Insert Into Asynchronous Table Queue Completion ID = q2 End of section
This may be a good situation in which to use a replicated MQT. A replicated MQT should be created based on a table in a single-partition database partition group, which would allow collocated joins if replicated to other database partitions. To create the replicated MQT, use the CREATE TABLE statement with the REPLICATED option, as below:
CREATE TABLE DB2INST2.SUMMARY_ZIP_CODE AS (SELECT * FROM DB2INST2.ZIP_CODE) DATA INITIALLY DEFERRED REFRESH IMMEDIATE ENABLE QUERY OPTIMIZATION REPLICATED
By default, the first column will be hashed, and since no table space is defined, USERSPACE1 is used.
NOTE
Aggregates are not allowed in the definition of a replicated MQT.
If the table ZIP_CODE table has a unique index on ZIP_CD, this index should be created on the MQT, as well, to let the optimizer know that this column is unique and to allow it to choose an access plan based on this knowledge. To populate the MQT, create an index on it and update the table's and index's statistics, using the following commands:
REFRESH TABLE DB2INST2.SUMMARY_ZIP_CODE CREATE UNIQUE INDEX CU_ZIP_CD ON DB2INST2.SUMMARY_ZIP_CODE(ZIP_CD) RUNSTATS ON TABLE DB2INST2.SUMMARY_ZIP_CODE WITH DISTRIBUTION AND DETAILED INDEXES ALL
This will allow the optimizer's query rewrite facility to reroute the query to the MQT, eliminating the need to broadcast the ZIP_CODE table to all database partitions every time the query is run. The new access plan would look like the following:
-------------------- SECTION --------------------------------------- Section = 1 SQL Statement: select c.*, z.zip, z.state_name, z.country_name from db2inst2.customer_address c join db2inst2.zip_code z on c.zip_cd = z.zip_cd Estimated Cost = 54176 Estimated Cardinality = 255819 Coordinator Subsection: Distribute Subsection #1 | Broadcast to Node List | | Nodes = 0, 1 Access Table Queue ID = q1 #Columns = 38 Return Data to Application | #Columns = 38 Subsection #1: Access Summary Table Name = DB2INST2.SUMMARY_ZIP_CODE ID = 2,47 | #Columns = 4 | Relation Scan . . . Nested Loop Join | Access Table Name = DB2INST2.CUSTOMER_ADDRESS ID = 2,591 | | #Columns = 35 | | Index Scan: Name = DB2INST2.CU_ZIP_CD ID = 2 . . . | | Insert Into Asynchronous Table Queue ID = q1 | | | Broadcast to Coordinator Node | | | Rows Can Overflow to Temporary Table Insert Into Asynchronous Table Queue Completion ID = q1 End of section
In this case, the cost is lower when the optimizer uses the MQT to allow a collocated join; however, if there were more partitions, and the partitions were placed on more than one server, the difference in costs between these access plans would be much greater.
Using replicated MQTs may yield significant performance advantages when the table that is being replicated to the other partitions:
is very frequently joined
is not heavily updated
is not too large
However, it may still make sense for infrequently updated larger tables to be replicated if the one-time cost of replication can be offset by the performance benefits of collocation.
NOTE
The locking issues described previously for REFRESH IMMEDIATE tables do not occur for replicated MQTs.
REFRESH IMMEDIATE vs. REFRESH DEFERRED
REFRESH IMMEDIATE MQTs affect performance of queries in the same manner that indexes do. They:
Speed up the performance of relevant select statements, while returning current data
Are automatically chosen by the optimizer whenever it makes sense
Can degrade the performance of insert, update, and delete statements
Cannot be updated directly
May occupy considerable disk space
May have exclusive locks held during updates of their base tables
To examine the performance impact of MQTs on updates, first examine the explain plan for an INSERT statement shown below:
-------------------- SECTION --------------------------------------- Section = 1 SQL Statement: insert into db2inst2.zip_code(zip_cd, zip, state_cd, state_name, country_name) values (60606, '60606', 'IL', 'Illinois', 'United States') Estimated Cost = 25 Estimated Cardinality = 1
Next, examine the explain plan for the same statement, but with a REFRESH IMMEDIATE MQT based on the table, as below:
-------------------- SECTION --------------------------------------- Section = 1 SQL Statement: insert into db2inst2.zip_code(zip_cd, zip, state_cd, state_name, country_name) values (60606, '60606', 'IL', 'Illinois', 'United States') Estimated Cost = 50 Estimated Cardinality = 1
In this example, the estimated cost of inserting a record into the base table is doubled when a REFRESH IMMEDIATE MQT is defined on the table. On the other hand, REFRESH DEFERRED MQTs have no effect on the performance of insert, update, and delete statements.
As a rule of thumb, use REFRESH IMMEDIATE MQTs in moderation, to optimize frequently run queries in which current data is important.
NOTE
Some MQTs are not eligible for immediate refreshes. The exact rules defining when they can and cannot be defined as REFRESH IMMEDIATE are described in the SQL Reference.
Let the Optimizer Decide
The optimizer may choose to reroute a query to an MQT defined with the REFRESH IMMEDIATE option instead of its base table, depending on:
The current statistics on the base table, the MQT, and their indexes
The value of the CURRENT QUERY OPTIMIZATION setting
The optimizer may choose to reroute a query to an MQT defined with the REFRESH DEFERRED option if CURRENT REFRESH AGE setting is set to ANY.
NOTE
The CURRENT QUERY OPTIMIZATION and CURRENT REFRESH AGE options are described in detail in the SQL Reference.
The best practices for using MQTs are as follows:
Create an appropriate MQT for the queries being executed.
Create appropriate indexes on the base table and MQT.
Keep the statistics current.
Let the optimizer choose whether to use the base table or the MQT; do not explicitly reference the MQT in the SQL.
In some cases, the optimizer may choose not to use the MQT in place of the base table. In these cases, the SQL statement can be rewritten to reference the MQT directly. And the optimizer will use the MQT in the access plan, regardless of whether it was defined as REFRESH DEFERRED or REFRESH IMMEDIATE, and regardless of the values of CURRENT REFRESH AGE and CURRENT QUERY OPTIMIZATION.
MQTs are very useful in various situations and can have a significant performance impact. The above examples illustrated how applying MQTs could significantly improve query performance but can also negatively impact update performance if performed frequently. Although MQTs are very convenient and effective, they do come at a price of additional disk space.
MQTs created with the REFRESH DEFERRED option do not impact the performance of inserts, updates, and deletes on the base tables but may not be used by the optimizer as often as MQTs created with the REFRESH IMMEDIATE option.






