Basic Database Terminology
Before we get into the interesting stuff, it might be useful to get acquainted with a few of the terms that you will encounter in your PostgreSQL life. PostgreSQL has a long history?you can trace its history back to 1977 and a program known as Ingres. A lot has changed in the relational database world since 1977. When you are breaking ground with a new product (as the Ingres developers were), you don't have the luxury of using standard, well-understood, and well-accepted terminology?you have to make it up as you go along. Many of the terms used by PostgreSQL have synonyms (or at least close analogies) in today's relational marketplace. In this section, I'll show you a few of the terms that you'll encounter in this book and try to explain how they relate to similar concepts in other database products.
Database
A database is a named collection of tables. (see table). A database can also contain views, indexes, sequences, data types, operators, and functions. Other relational database products use the term catalog.
Command
A command is a string that you send to the server in hopes of having the server do something useful. Some people use the word statement to mean command. The two words are very similar in meaning and, in practice, are interchangeable.
Query
A query is a type of command that retrieves data from the server.
Table (relation, file, class)
A table is a collection of rows. A table usually has a name, although some tables are temporary and exist only to carry out a command. All the rows in a table have the same shape (in other words, every row in a table contains the same set of columns). In other database systems, you may see the terms relation, file, or even class?these are all equivalent to a table.
Column (field, attribute)
A column is the smallest unit of storage in a relational database. A column represents one piece of information about an object. Every column has a name and a data type. Columns are grouped into rows, and rows are grouped into tables. In Figure 1.1, the shaded area depicts a single column.
Figure 1.1. A column (highlighted).
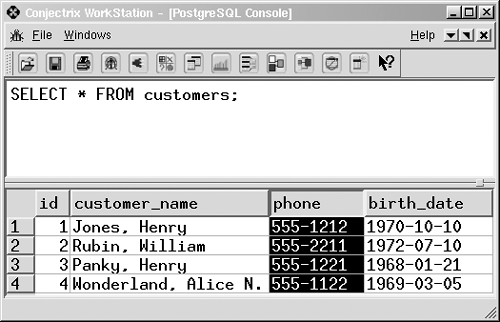
The terms field and attribute have similar meanings.
Row (record, tuple)
A row is a collection of column values. Every row in a table has the same shape (in other words, every row is composed of the same set of columns). If you are trying to model a real-world application, a row represents a real-world object. For example, if you are running an auto dealership, you might have a vehicles table. Each row in the vehicles table represents a car (or truck, or motorcycle, and so on). The kinds of information that you store are the same for all vehicles (that is, every car has a color, a vehicle ID, an engine, and so on). In Figure 1.2, the shaded area depicts a row.
Figure 1.2. A row (highlighted).
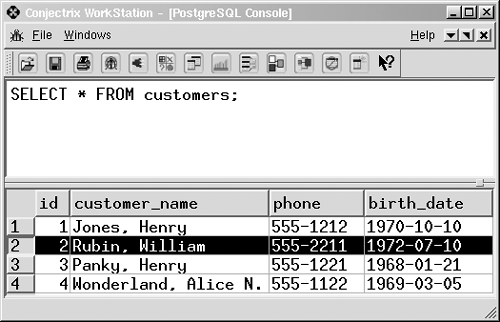
You may also see the terms record or tuple?these are equivalent to a row.
View
A view is an alternative way to present a table (or tables). You might think of a view as a "virtual" table. A view is (usually) defined in terms of one or more tables. When you create a view, you are not storing more data, you are instead creating a different way of looking at existing data. A view is a useful way to give a name to a complex query that you may have to use repeatedly.
Client/server
PostgreSQL is built around a client/server architecture. In a client/server product, there are at least two programs involved. One is a client and the other is a server. These programs may exist on the same host or on different hosts that are connected by some sort of network. The server offers a service; in the case of PostgreSQL, the server offers to store, retrieve, and change data. The client asks a server to perform work; a PostgreSQL client asks a PostgreSQL server to serve up relational data.
Client
A client is an application that makes requests of the PostgreSQL server. Before a client application can talk to a server, it must connect to a postmaster (see postmaster) and establish its identity. Client applications provide a user interface and can be written in many languages. Chapters 8 through 17 will show you how to write a client application.
Server
The PostgreSQL server is a program that services commands coming from client applications. The PostgreSQL server has no user interface?you can't talk to the server directly, you must use a client application.
Postmaster
Because PostgreSQL is a client/server database, something has to listen for connection requests coming from a client application. That's what the postmaster does. When a connection request arrives, the postmaster creates a new server process in the host operating system.
Transaction
A transaction is a collection of database operations that are treated as a unit. PostgreSQL guarantees that all the operations within a transaction complete or that none of them complete. This is an important property?it ensures that if something goes wrong in the middle of a transaction, changes made before the point of failure will not be reflected in the database. A transaction usually starts with a BEGIN command and ends with a COMMIT or ROLLBACK (see the next entries).
Commit
A commit marks the successful end of a transaction. When you perform a commit, you are telling PostgreSQL that you have completed a unit of operation and that all the changes that you made to the database should become permanent.
Rollback
A rollback marks the unsuccessful end of a transaction. When you roll back a transaction, you are telling PostgreSQL to discard any changes that you have made to the database (since the beginning of the transaction).
Index
An index is a data structure that a database uses to reduce the amount of time it takes to perform certain operations. An index can also be used to ensure that duplicate values don't appear where they aren't wanted. I'll talk about indexes in Chapter 4, "Query Optimization."
Result set
When you issue a query to a database, you get back a result set. The result set contains all the rows that satisfy your query. A result set may be empty.







