Managing Databases
PostgreSQL stores data in a collection of operating system files. At the highest level of organization, you find a cluster. A cluster is a collection of databases (which, in turn, is a collection of schemas).
Creating a New Cluster
You create a new cluster using the initdb program. Note that initdb is an external program, not a command that you would execute in a PostgreSQL client.
When you run initdb, you are creating the data files that define a cluster. The most important command-line argument to initdb is --pgdata=cluster-location[4]. The --pgdata argument tells initdb the name of the directory that should contain the new cluster. For example, if you execute the command
[4] There are actually three ways to specify the cluster location. All the following commands are equivalent:
$ initdb --pgdata=/usr/newcluster $ initdb -D /usr/newcluster $ export PGDATA=/usr/newcluster ; initdb
$ initdb --pgdata=/usr/newcluster
initdb creates the directory /usr/newcluster and a few files and subdirectories within /usr/newcluster. It's usually a good idea to let initdb create the directory that contains the cluster so that all the file ownerships and permissions are properly defined. In fact, initdb won't create a cluster in a directory that is not empty. So, let's see the directory structure that we end up with after initdb has completed its work (see Figure 19.9).
Figure 19.9. The data directory layout.
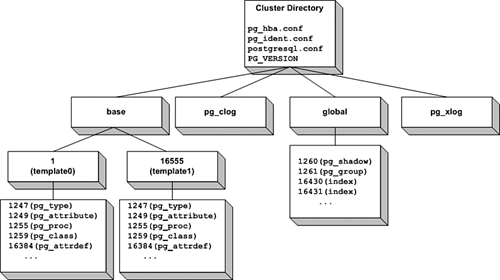
At the top of the directory structure is the cluster directory itself?I'll refer to that as $PGDATA because that is where the $PGDATA environment variable should point.
$PGDATA contains four files and four subdirectories[5]. $PGDATA/pg_hba.conf contains the host-based authentication configuration file. This file tells PostgreSQL how to authenticate clients on a host-by-host basis. We'll look at the pg_hba.conf file in great detail in Chapter 21, "Security." The $PGDATA/pg_ident.conf file is used by the ident authentication scheme to map OS usernames into PostgreSQL user names?again, I'll describe this file in the chapter dealing with PostgreSQL security. $PGDATA/postgresql.conf contains a list of runtime parameters that control various aspects of the PostgreSQL server. The fourth file, $PGDATA/PG_VERSION, is a simple text file that contains the version number from initdb.
[5] You are looking at a cluster created with PostgreSQL version 7.2. The exact details may differ if you are using a different version.
Now, let's look at each of the subdirectories created by initdb.
The pg_xlog directory contains the write-ahead logs. Write-ahead logs are used to improve database reliability and performance. Whenever you update a row within a table, PostgreSQL will first write the change to the write-ahead log, and at some later time will write the modifications to the actual data pages on disk. The pg_xlog directory usually contains a number of files, but initdb will create only the first one?extra files are added as needed. Each xlog file is 16MB long.
The pg_clog directory contains commit logs. A commit log reflects the state of each transaction (committed, in-progress, or aborted).
The global directory contains three tables that are shared by all databases within a cluster: pg_shadow, pg_group, and pg_database. The pg_shadow table holds user account definitions and is maintained by the CREATE USER, ALTER USER, and DROP USER commands. The pg_group table holds user group definitions and is maintained by the CREATE GROUP, ALTER GROUP, and DROP GROUP commands. pg_database contains a list of all databases within the cluster and is maintained by the CREATE DATABASE and DROP DATABASE commands. The global directory also contains a number of indexes for the pg_shadow, pg_group, and pg_database tables. global contains two other files that are shared by all databases in a cluster: pgstat.stat and pg_control. The pgstat.stat file is used by the statistics monitor (the statistics monitor accumulates performance and usage information for a database cluster). The pg_control file contains a number of cluster parameters, some of which are defined by initdb and will never change. Others are modified each time the postmaster is restarted. You can view the contents of the pg_control file using the pg_controldata utility provided in the contrib directory of a source distribution. Here's a sample of the output from pg_controldata:
$ pg_controldata pg_control version number: 71 Catalog version number: 200201121 Database state: IN_PRODUCTION pg_control last modified: Sat Jan 20 10:32:42 2002 Current log file id: 0 Next log file segment: 1 Latest checkpoint location: 0/11393C Prior checkpoint location: 0/1096A4 Latest checkpoint's REDO location: 0/11393C Latest checkpoint's UNDO location: 0/0 Latest checkpoint's StartUpID: 8 Latest checkpoint's NextXID: 155 Latest checkpoint's NextOID: 16556 Time of latest checkpoint: Sat Jan 20 09:43:11 2002 Database block size: 8192 Blocks per segment of large relation: 131072 LC_COLLATE: en_US LC_CTYPE: en_US
The initdb utility also creates two template databases in the new cluster: template0 and template1. The template0 database represents a "stock" database?it contains the definitions for all system tables, as well as definitions for the standard views, functions, and data types. You should never modify template0?in fact, you can't even connect to the template0 database without performing some evil magic. When you run initdb, the template0 database is copied to template1. You can modify the template1 database. Just as the template0 database is cloned to create template1, template1 is cloned whenever you create a new database using CREATE DATABASE (or createdb). It's useful to modify the template1 database when you want a particular feature (like a custom data type, function, or table) to exist in every database that you create in the future. For example, if you happen to run an accounting business, you might want to define a set of accounting tables (customers, vendors, accounts, and so on) in the template1 database. Then, when you sign up a new customer and create a new database for that customer, the new database will automatically contain the empty accounting tables.
You may also find it useful to create other template databases. To extend the previous example a bit, let's say that you have a core set of financial applications (general ledger, accounts payable, accounts receivable) that are useful regardless of the type of business your customer happens to run. You may develop a set of extensions that are well suited to customers who own restaurants, and another set of extensions that you use for plumbers. If you create two new template databases, restaurant_template and plumber_template, you'll be ready to sign up new restaurants and new plumbers with minimal work. When you want to create a database for a new restaurateur, simply clone the restaurant_template database.
After you have created a cluster (and the two default template databases), you can create the actual databases where you will do your work.
Creating a New Database
There are two ways to create a new database. You can use the CREATE DATABASE command from within a PostgreSQL client application (such as psql), or you can use the createdb shell script. The syntax for the CREATE DATABASE command is
CREATE DATABASE database-name [WITH [TEMPLATE = template-database-name ] [ENCODING = character-encoding ] [OWNER = database-owner ] [LOCATION = pathname ]]
A database-name must conform to the usual rules for PostgreSQL identifiers: it should start with an underscore or a letter and should be at most 31 characters long. If you need to include a space (or start the database name with a digit), enclose the database-name in double quotes.
When you execute the CREATE DATABASE command, PostgreSQL will copy an existing template database. If you don't include a TEMPLATE=template-database-name clause, CREATE DATABASE will clone the template1 database. A few restrictions control whether or not you can clone a given database. First, a cluster superuser can clone any database. The owner of a database can clone that database. Finally, any user with CREATEDB privileges can clone a database whose datistemplate attribute is set to true in the pg_database system table. Looking at this in the other direction, ordinary users cannot clone a database that is not specifically marked as a template (according to the datistemplate attribute).
You can choose an encoding for the new database using the ENCODING=character-encoding clause. An encoding tells PostgreSQL which character set to use within your database. If you don't specify an encoding, the new database will use the same encoding that the template database uses. Encodings are discussed in detail in Chapter 20, "Internationalization and Localization."
If you don't include the OWNER=username clause or if you specify OWNER=DEFAULT, you become the owner of the database. If you are a PostgreSQL superuser, you can create a database that will be owned by another user using the OWNER=username clause. If you are not a PostgreSQL superuser, you can still create a database (assuming that you hold the CREATEDB privilege), but you cannot assign ownership to another user.
The final option to the CREATE DATABASE command is LOCATION=pathname. This clause is used to control where PostgreSQL places the files that make up the new database. If you don't specify a location, CREATE DATABASE will create a subdirectory in the cluster ($PGDATA) to hold the new database. There are some restrictions to where you can place a new database; see the "Creating New Databases" section of Chapter 3, "PostgreSQL Syntax and Use," for more information.
As I mentioned earlier, there are two ways to create a new database: CREATE DATABASE and createdb. The createdb utility is simply a shell script that invokes the psql client to execute a CREATE DATABASE, command. createdb does not offer any more functionality than CREATE DATABASE so use whichever you find most convenient. For more information on the createdb utility, invoke createdb with the --help flag:
$ createdb --help createdb creates a PostgreSQL database. Usage: createdb [options] dbname [description] Options: -D, --location=PATH Alternative place to store the database -T, --template=TEMPLATE Template database to copy -E, --encoding=ENCODING Multibyte encoding for the database -h, --host=HOSTNAME Database server host -p, --port=PORT Database server port -U, --username=USERNAME Username to connect as -W, --password Prompt for password -e, --echo Show the query being sent to the backend -q, --quiet Don't write any messages By default, a database with the same name as the current user is created. Report bugs to <pgsql-bugs@postgresql.org>.
Routine Maintenance
Compared to most relational database management systems, PostgreSQL does not require much in the way of routine maintenance, but there are a few things you should do on a regular basis.
Managing Tables (cluster and vacuum)
When you delete (or update) rows in a PostgreSQL table, the old data is not immediately removed from the database. In fact, unlike other database systems, the free space is not even marked as being available for reuse. If you delete or modify a lot of data, your database may become very large very fast. You may also find that performance suffers because PostgreSQL will have to load obsolete data from disk even though it won't use that data.
To permanently free obsolete data from a table, you use the VACUUM command. The VACUUM command comes in four flavors:
VACUUM [table-name] VACUUM FULL [table-name] VACUUM ANALYZE [table-name] VACUUM FULL ANALYZE [table-name]
The first and third forms are the ones most commonly used.
In the first form, VACUUM makes all space previously used to hold obsolete data available for reuse. This form does not require exclusive access to the table and usually runs quickly. If you don't specify a table-name, VACUUM will process all tables in the database.
In the second form, VACUUM removes obsolete data from the table (or entire database). Without the FULL option, VACUUM only marks space consumed by obsolete data as being available for reuse. With the FULL option, VACUUM tries to shrink the data file instead of simply making space available for reuse. A VACUUM FULL requires exclusive access to each table and is generally much slower than a simple VACUUM.
The VACUUM ANALYZE command will first VACUUM a table (or database) and will then compute statistics for the PostgreSQL optimizer. I discussed optimization and statistics in Chapter 4, "Performance." If you will VACUUM a table (or database), you may as well update the per-table statistics as well.
The final form combines a VACUUM FULL with a VACUUM ANALYZE. As you might expect, this shrinks the database by removing obsolete data and then computes new performance-related statistics. Like VACUUM FULL, VACUUM FULL ANALYZE locks each table for exclusive use while it is being processed.
Another command that you may want to execute on a routine basis is the CLUSTER command. CLUSTER rearranges the rows in a given table so that they are physically stored in index order. This is a cheap way to get enormous performance gains?run this command occasionally and you'll look like a hero. See Chapter 4 for more information.
Managing Indexes
For the most part, indexes are self-maintaining. Occasionally, you may find that an index has become corrupted and must be rebuilt (actually, you are more likely to suspect a corrupted index than to find one). You can also improve performance slightly (and reduce disk space consumption) by rebuilding indexes on an occasional basis.
The easiest way to rebuild an index is with the REINDEX command. REINDEX comes in the following forms:
REINDEX INDEX index-name [FORCE] REINDEX TABLE table-name [FORCE] REINDEX DATABASE database-name [FORCE]
In all three forms, you can force REINDEX to rebuild indexes on system tables (they are normally ignored by REINDEX) by including the keyword FORCE at the end of the command. If you find you need to REINDEX system tables, you should consult the PostgreSQL Reference Manual for the gory details. (Warning?this is not for the faint-of-heart.)








